
palimpsest bad sectors false positive
| Affects | Status | Importance | Assigned to | Milestone | |
|---|---|---|---|---|---|
| OEM Priority Project |
Fix Released
|
Undecided
|
Robert | ||
| libatasmart |
Confirmed
|
Medium
|
|||
| libatasmart (Fedora) |
Won't Fix
|
High
|
|||
| libatasmart (Mandriva) |
New
|
Undecided
|
Unassigned | ||
| libatasmart (Ubuntu) |
Fix Released
|
Medium
|
Martin Pitt | ||
| Karmic |
Fix Released
|
Medium
|
Martin Pitt | ||
| Lucid |
Fix Released
|
Medium
|
Martin Pitt | ||
| libatasmart (zUbuntu) |
New
|
Undecided
|
Unassigned | ||
Bug Description
Binary package hint: gnome-disk-utility
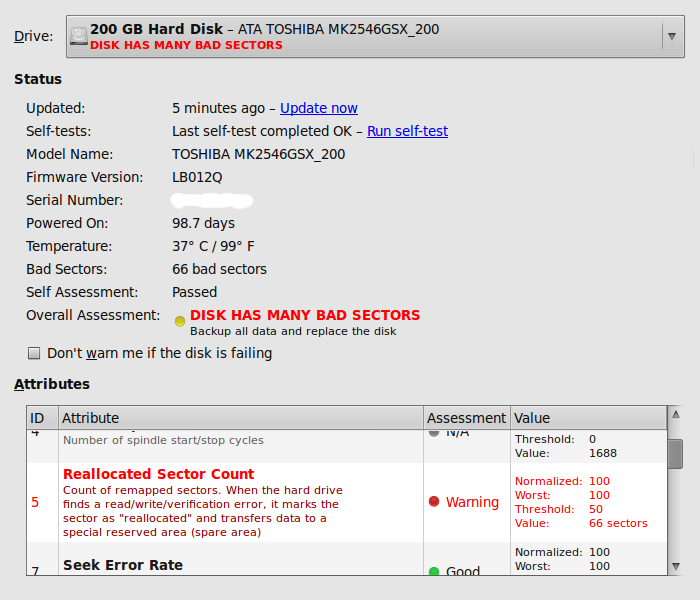
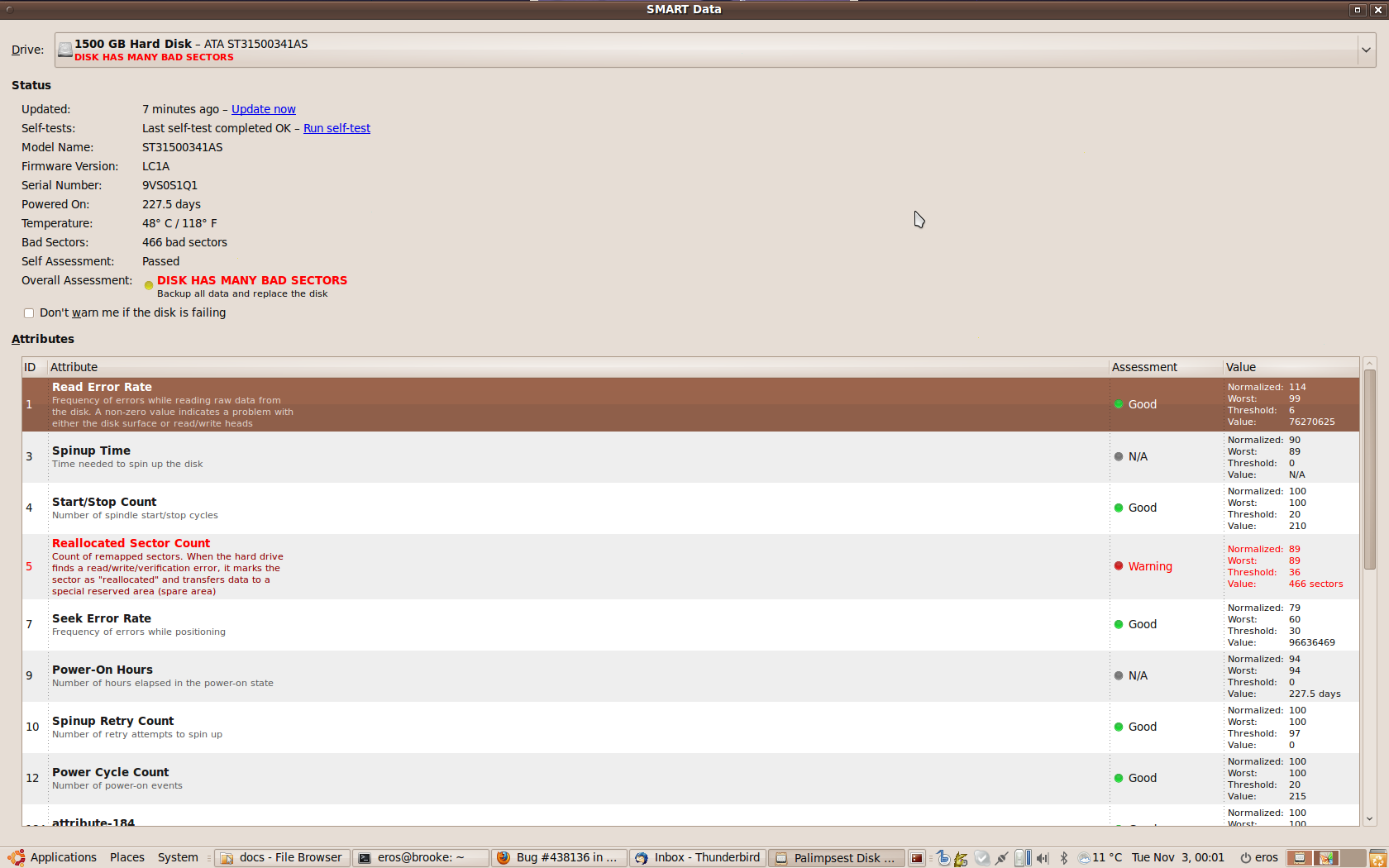
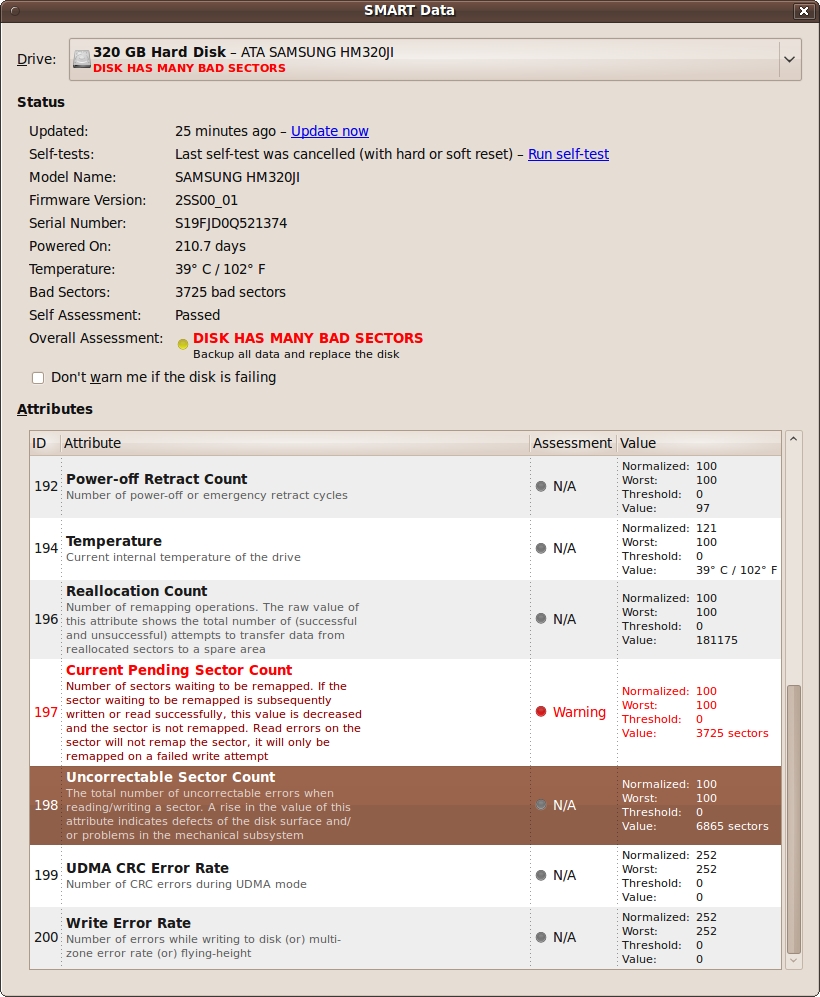
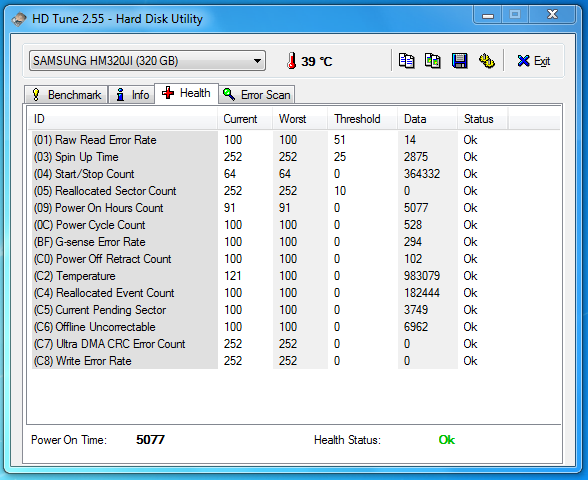
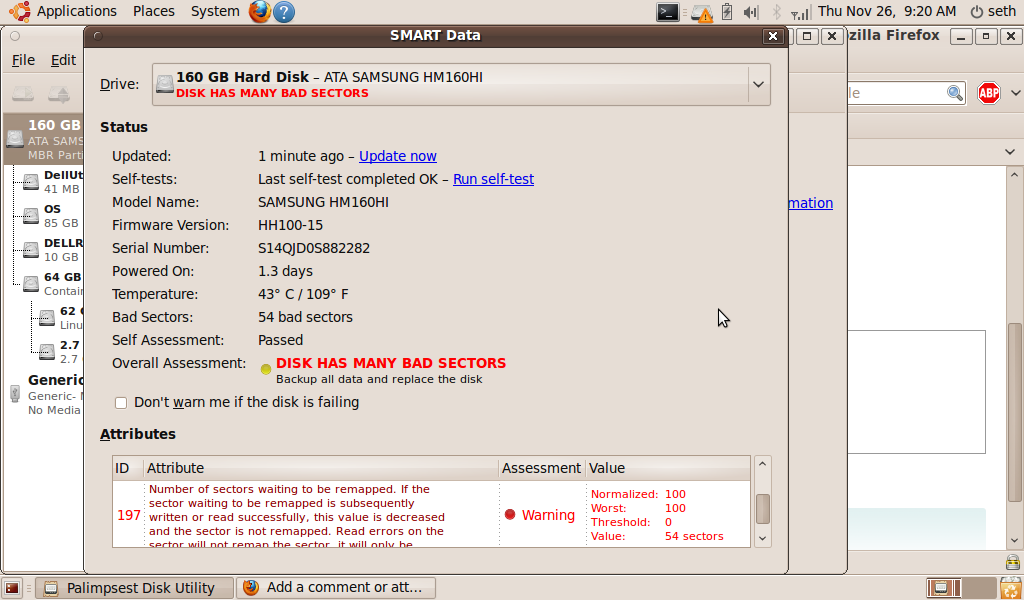
palimpsest complains, that the disk has many bad sectors. palimpsest thinks, that SMART value 5 "Reallocated Sector Count" fails (screenshot attached). smartctl reports " 5 Reallocated_
SRU information:
- Impact: Way too trigger happy about "broken disk" notifications, which both scares people and also makes them ignore situations where the disk is actually about to die
- Fixed in lucid by reverting from our own bad sectors heuristics (using the raw numbers) to the manufactuer normalized numbers and manufacturer thresholds: http://
- No regression reports since then in lucid.
SRU TEST CASE:
- Download seb128's demo SMART data which have a few bad blocks, but not enough to be over the manufacturer threshold:
wget -O /tmp/smart.blob http://
- Install libatasmart-bin
- Run
skdump --load=
With the karmic final version this says "BAD_SECTOR_MANY" which the GUI will react on with a scary notification.
The updated version should just say BAD_SECTOR.
If you leave out the --overall argument, you get a detailled list of the attributes. The broken ones will be printed in bold.
On a healthy system, "sudo ./skdump /dev/sda --overall" should still say "GOOD", and on a genuinely broken hard disk it should give the appropriate BAD_SECTOR/
ProblemType: Bug
Architecture: amd64
Date: Mon Sep 28 15:20:15 2009
DistroRelease: Ubuntu 9.10
Package: gnome-disk-utility 2.28.0-0ubuntu2
ProcEnviron:
PATH=(custom, user)
LANG=de_DE.UTF-8
SHELL=/bin/bash
ProcVersionSign
SourcePackage: gnome-disk-utility
Uname: Linux 2.6.31-11-generic x86_64

{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Changed in gnome-disk-utility (Ubuntu): | |
| assignee: | nobody → Sergey Sventitski (sergey-sventitski) |
| Changed in gnome-disk-utility (Ubuntu): | |
| assignee: | Sergey Sventitski (sergey-sventitski) → nobody |
| Changed in gnome-disk-utility (Ubuntu Karmic): | |
| status: | New → Confirmed |
| importance: | Undecided → Medium |
| Changed in gnome-disk-utility (Ubuntu Lucid): | |
| importance: | Undecided → Medium |
| status: | New → Confirmed |
| Changed in gnome-disk-utility (Ubuntu Lucid): | |
| assignee: | nobody → Canonical Ubuntu QA Team (canonical-qa) |
| Changed in gnome-disk-utility (Ubuntu Lucid): | |
| assignee: | Canonical Ubuntu QA Team (canonical-qa) → Canonical Desktop Team (canonical-desktop-team) |
| affects: | gnome-disk-utility (Ubuntu Karmic) → libatasmart (Ubuntu Karmic) |
| Changed in libatasmart (Ubuntu Lucid): | |
| assignee: | Canonical Desktop Team (canonical-desktop-team) → Martin Pitt (pitti) |
| Changed in libatasmart (Ubuntu Karmic): | |
| status: | Confirmed → Triaged |
| Changed in libatasmart (Ubuntu Lucid): | |
| status: | Confirmed → Triaged |
| Changed in libatasmart (Fedora): | |
| status: | Unknown → Confirmed |
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| description: | updated |
{kind=link}
{kind=link}
{kind=link}
| tags: | added: regression-potential |
| Changed in libatasmart (Ubuntu Lucid): | |
| milestone: | none → ubuntu-10.04-beta-1 |
| Changed in libatasmart (Ubuntu Lucid): | |
| assignee: | nobody → Martin Pitt (pitti) |
| Changed in libatasmart (Ubuntu Lucid): | |
| milestone: | ubuntu-10.04-beta-1 → ubuntu-10.04-beta-2 |
| Changed in libatasmart (Ubuntu Lucid): | |
| status: | Triaged → In Progress |
| Changed in libatasmart: | |
| status: | Unknown → Confirmed |
| Changed in libatasmart (Ubuntu Karmic): | |
| assignee: | nobody → Canonical Platform QA Team (canonical-platform-qa) |
| Changed in libatasmart (Ubuntu Karmic): | |
| milestone: | none → karmic-updates |
| Changed in libatasmart (Ubuntu Karmic): | |
| status: | Triaged → In Progress |
| assignee: | Canonical Platform QA Team (canonical-platform-qa) → Martin Pitt (pitti) |
| description: | updated |
| description: | updated |
| description: | updated |
| Changed in oem-priority: | |
| status: | New → In Progress |
| Changed in oem-priority: | |
| status: | In Progress → Fix Released |
| Changed in oem-priority: | |
| status: | Fix Released → Incomplete |
| assignee: | nobody → Robert (robertkanabis) |
| status: | Incomplete → Confirmed |
| Changed in oem-priority: | |
| status: | Confirmed → Fix Released |
| Changed in libatasmart: | |
| importance: | Unknown → Medium |
{kind=link}
{kind=link}
| Changed in libatasmart: | |
| importance: | Medium → Unknown |
| Changed in libatasmart: | |
| importance: | Unknown → Medium |
| Changed in libatasmart: | |
| status: | Confirmed → Fix Released |
| Changed in libatasmart: | |
| status: | Fix Released → Confirmed |
| tags: | added: oneiric precise |
{kind=link}
{kind=link}
| Changed in libatasmart (Fedora): | |
| importance: | Unknown → High |
| status: | Confirmed → Won't Fix |
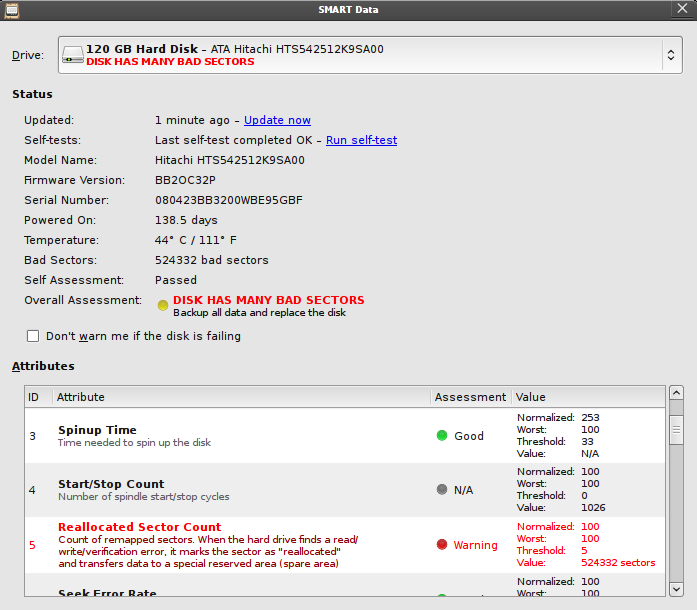
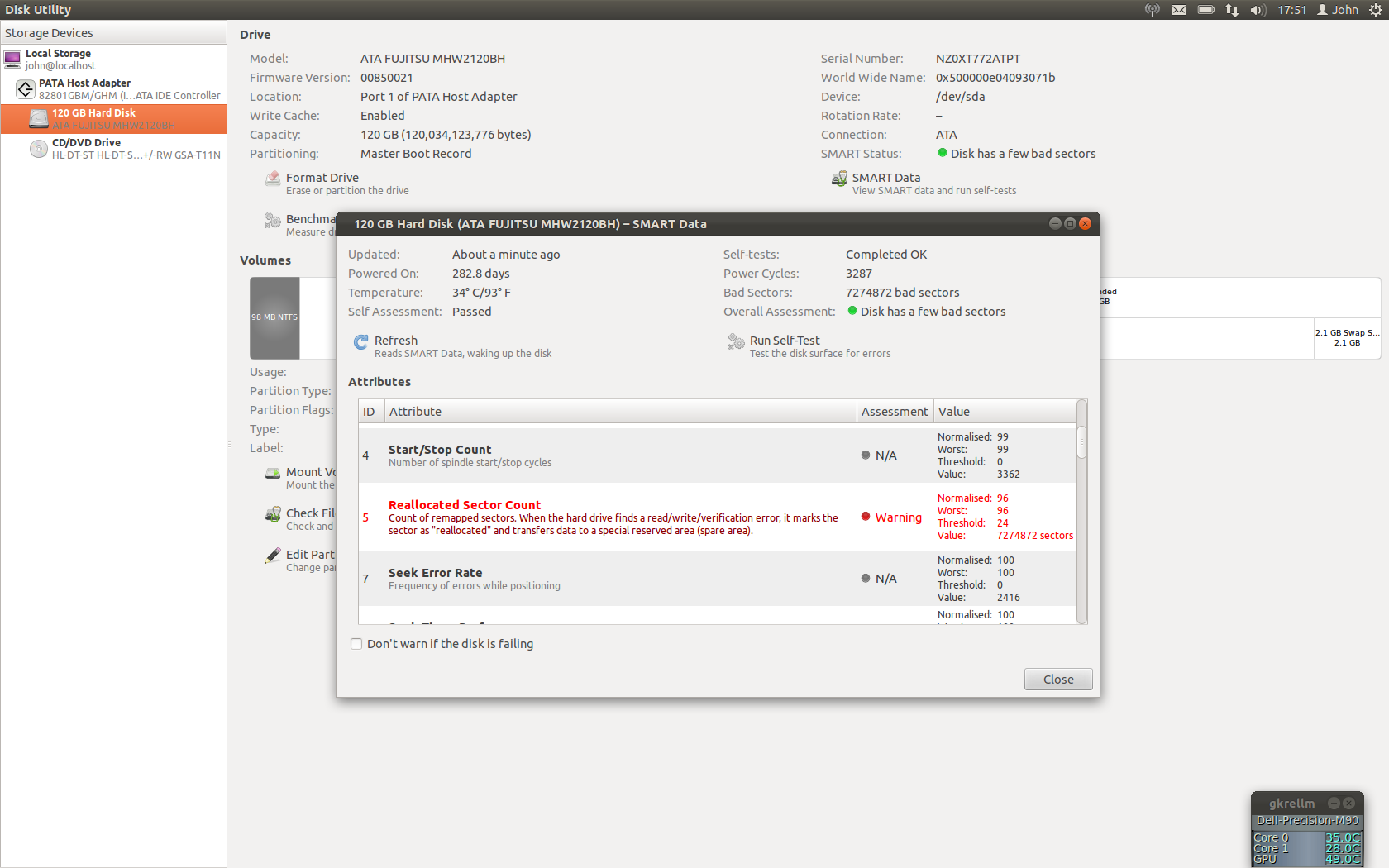
I can confirm. Suffering from the same issue in 9.10 where Palimpsest is saying my Hitachi HTS541680J9SA00 has many bad sectors. Reallocated Sector Count. Pops it up every time I restart the computer.