
{kind=link}
© 2004
Canonical Ltd.
•
Terms of use
•
Data privacy
•
Contact Launchpad Support
•
Blog
•
Careers
•
System status
•
1b1ed1a
(Get the code!)
Hi Serge,
Thanks for following up. Sorry for not replying sooner. Here's a test case that reproduces this reliably on precise:
Create a new VM using these settings:
ISO: http://
Virtual CPUs: 2 (or more)
After install, edit /etc/rc.local and add the following line to set up a reboot loop:
grep STOP /proc/cmdline || shutdown -r now test
Reboot the VM.
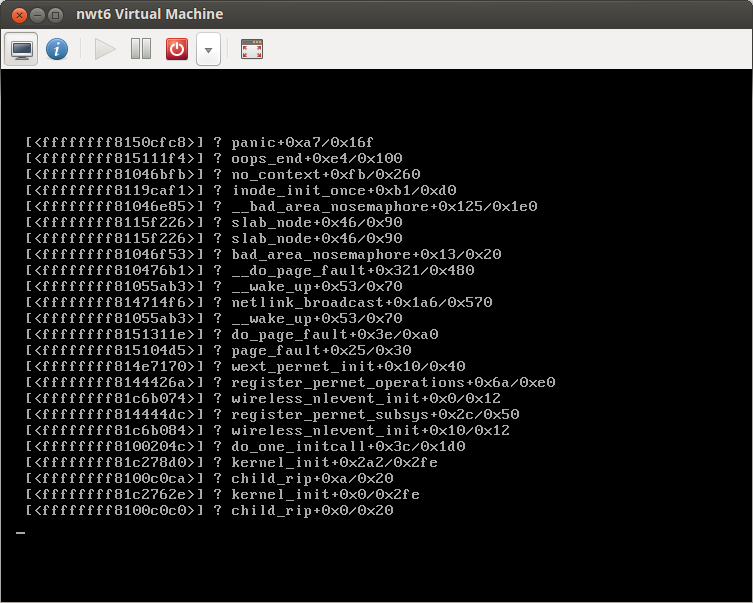
In my testing, it almost immediately gets into a loop where right after the GRUB countdown, it jumps back to the beginning of the boot sequence. After a few boots, it stops on either a kernel panic (see attached) or hangs (sometimes causing virt-manager to lock up) with messages like these (similar to bug 957957) in the syslog:
Nov 7 20:30:55 selma kernel: [855283.206924] kvm [27518]: vcpu0 unhandled rdmsr: 0xc0010001
A colleague pointed out today that reducing the virtual CPU allocation for the VM guest to 1 does appear to either make this far less frequent or go away entirely (haven't done enough testing to tell). Obviously that's not a long term solution, but I mention it in case it's a helpful workaround for others who find this bug report.
The good news is that on saucy, the same test case has not reproduced after 80+ reboots. (Unfortunately, my saucy VM host and precise VM host are not identical hardware. Hopefully that's not important.)