qemu-kvm : Ubuntu 12.04 (host) / Centos 6.3 (guest) rebooting from guest gets stuck in a seabios/grub loop - cannot initialise kernel (10.04 is fine)
| Affects | Status | Importance | Assigned to | Milestone | |
|---|---|---|---|---|---|
| libvirt |
New
|
Undecided
|
Unassigned | ||
| qemu-kvm |
New
|
Undecided
|
Unassigned | ||
| CentOS |
New
|
Undecided
|
Unassigned | ||
Bug Description
I have a really annoying bug, I can reproduce often (although it is a bit random).
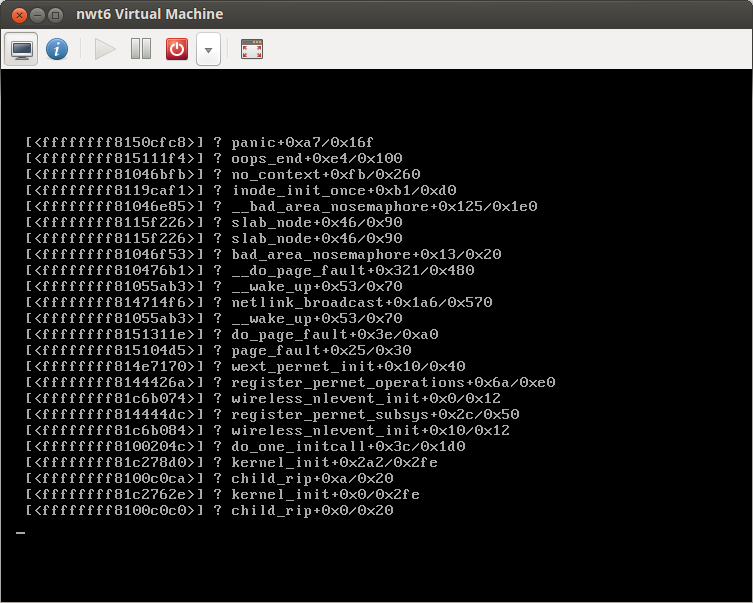
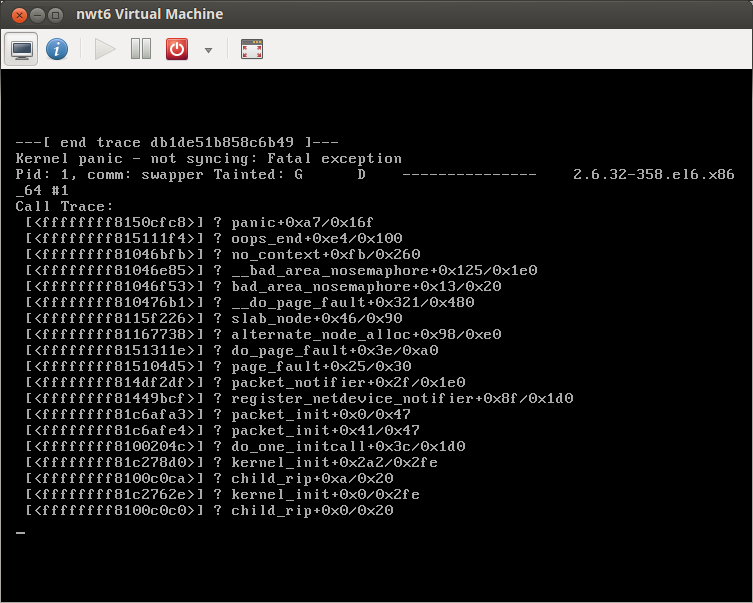
I have an Ubuntu 12.04 KVM server , using Centos 6 guests - when I install the latest kernel for centos 6.3 -2.6.32-279.1.1.el6 - if you reboot from inside a Centos6 vm it gets stuck in a loop between seabios/grub - this does't happen 100% of the time - there is a high chance it will though - usually after 3 reboots it will get stuck in the loop - it will NEVER reboot without manual intervention (virsh destroy..)
It seem to fail at the kernel initialise stage - if I use vga=normal I can see the words 'Probing EEID...' for a sec (then it reboots)
If i use virsh/virt-manager to reboot its fine, only from inside a centos6 vm (with latest centos kernel) does this occur
As a test I installed centos 6.2 - this was 100% fine *until* I did a yum update then I got the same issue.
Ubuntu 10.04 KVM host / Centos 6.3 (guest) is fine - so i'm unsure where the fault is. Likewize a Centos 6.3 kvm host and centos 6.3 guest is also fine...
I have installed a 2nd Ubuntu 12.04 KVM server and the exact same thing occurs (i.e 2 different servers = same issue)
How can I troubleshoot this ? I already have already enabled the boot options 'console=ttyS0' (which I can access vm's using virsh console id) however this gives no output (as it crashes when initialising the kernel)
I have also tried installing the latest qemu-kvm (1.1) from source on the Ubuntu 12.04 kvm server, the same thing occurs .
At present we are replacing Ubuntu as the KVM host (to Centos) whilst this bug remains.

{kind=link}
{kind=link}
Thanks for submitting this bug. If you have another host on which you can still reproduce this, then it would be great if you could:
1. sudo mv /usr/share/
2. apport-collect 1025188
However since you've switched to a centos host for now, I assume I'll need to try to reproduce myself. I'll grab a centos iso to try.
Could you however give the contents of /proc/cpuinfo ?