
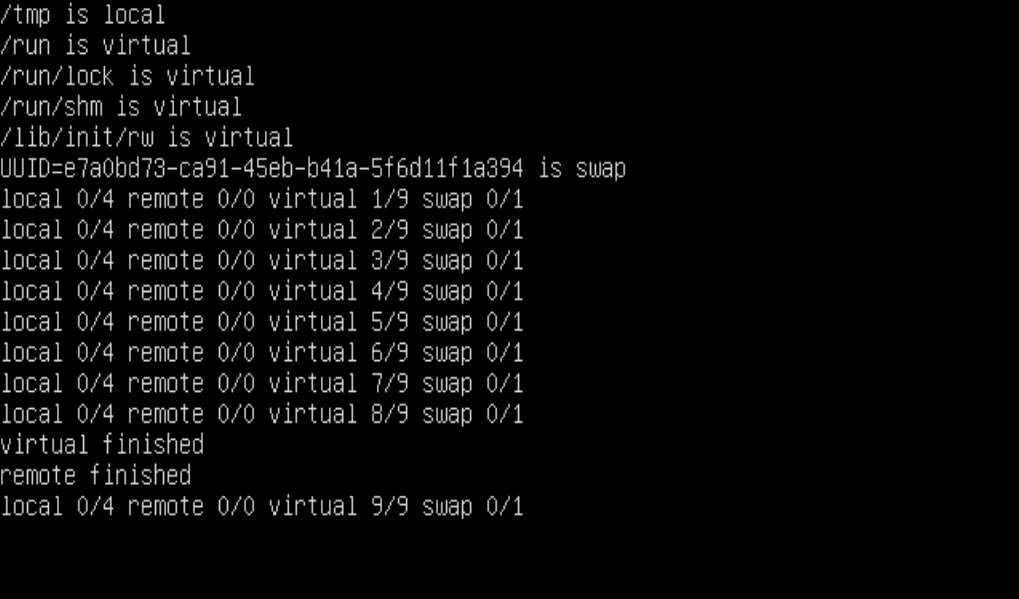
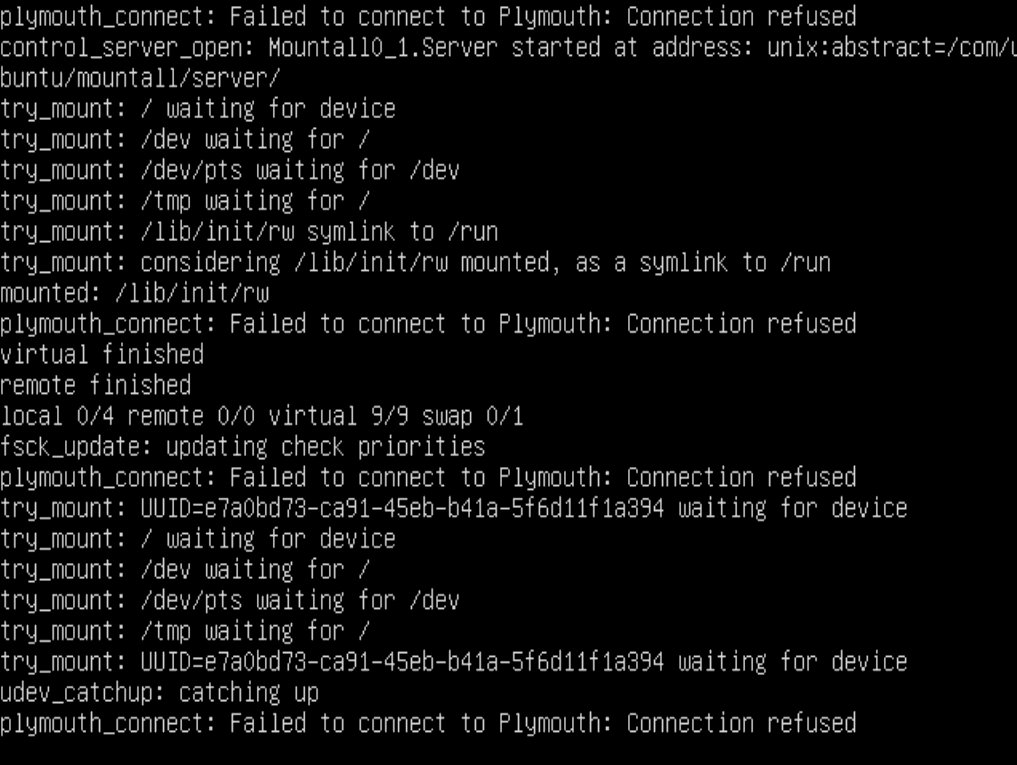
boot failures as /dev is not transferred to /root (because 'udevadm exit' times out waiting for a deadlocked worker)
| Affects | Status | Importance | Assigned to | Milestone | |
|---|---|---|---|---|---|
| Release Notes for Ubuntu |
Invalid
|
Undecided
|
Unassigned | ||
| linux (Ubuntu) |
Invalid
|
High
|
Unassigned | ||
| Oneiric |
Invalid
|
High
|
Unassigned | ||
| Precise |
Invalid
|
Undecided
|
Unassigned | ||
| udev (Ubuntu) |
Fix Released
|
High
|
Andy Whitcroft | ||
| Oneiric |
Fix Released
|
High
|
Andy Whitcroft | ||
| Precise |
Fix Released
|
High
|
Andy Whitcroft | ||
Bug Description
After running a do-release-upgrade -d on a natty server, I'm unable to boot the machine properly.
It looks like it doesn't see the local disks anymore.
I think this looks quite a lot like the debbug linked from here:
https:/
ProblemType: Bug
DistroRelease: Ubuntu 11.10
Package: linux-image-
ProcVersionSign
Uname: Linux 3.0.0-7-server x86_64
AlsaDevices:
total 0
crw-rw---- 1 root audio 116, 1 2011-07-29 13:34 seq
crw-rw---- 1 root audio 116, 33 2011-07-29 13:34 timer
AplayDevices: Error: [Errno 2] No such file or directory
Architecture: amd64
ArecordDevices: Error: [Errno 2] No such file or directory
AudioDevicesInUse: Error: command ['fuser', '-v', '/dev/snd/seq', '/dev/snd/timer'] failed with exit code 1:
CRDA: Error: [Errno 2] No such file or directory
Date: Fri Jul 29 13:40:10 2011
HibernationDevice: RESUME=
IwConfig:
lo no wireless extensions.
eth0 no wireless extensions.
eth1 no wireless extensions.
MachineType: HP ProLiant DL380 G5
PciMultimedia:
ProcEnviron:
LANGUAGE=en_US:
PATH=(custom, user)
LANG=en_US
SHELL=/bin/bash
ProcKernelCmdLine: BOOT_IMAGE=
RelatedPackageV
linux-
linux-
linux-firmware 1.56
RfKill: Error: [Errno 2] No such file or directory
SourcePackage: linux
UpgradeStatus: Upgraded to oneiric on 2011-07-29 (0 days ago)
dmi.bios.date: 06/28/2007
dmi.bios.vendor: HP
dmi.bios.version: P56
dmi.chassis.type: 23
dmi.chassis.vendor: HP
dmi.modalias: dmi:bvnHP:
dmi.product.name: ProLiant DL380 G5
dmi.sys.vendor: HP
Related branches
- Steve Langasek: Disapprove
- Ubuntu branches: Pending requested
-
Diff: 29 lines (+11/-0)2 files modifieddebian/changelog (+7/-0)
debian/udev.initramfs-bottom (+4/-0)

| Changed in linux (Ubuntu): | |
| status: | New → Confirmed |
{kind=link}
{kind=link}
| Changed in linux (Ubuntu): | |
| importance: | Undecided → High |
{kind=link}
{kind=link}
| summary: |
- HP DL380G5 does not see disks after upgrade to Oneiric + HP DL380G5 root disk mounted read-only on boot and boot fails |
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| tags: | added: server-o-ro |
| Changed in linux (Ubuntu): | |
| assignee: | nobody → Ubuntu Foundations Team (ubuntu-foundations-team) |
| Changed in udev (Ubuntu): | |
| assignee: | Ubuntu Foundations Team (ubuntu-foundations-team) → James Hunt (jamesodhunt) |
| tags: |
added: kernel-request-3.0.0-11.17 removed: kernel-request-3.0.0-7.8 |
| tags: | added: rls-mgr-o-tracking |
| Changed in udev (Ubuntu Oneiric): | |
| milestone: | none → ubuntu-11.10 |
| summary: |
- HP DL380G5 root disk mounted read-only on boot and boot fails + boot failures caused by udev race |
| Changed in linux (Ubuntu Oneiric): | |
| status: | Incomplete → Invalid |
| summary: |
- boot failures caused by udev race + boot failures because 'udevadm exit' does not kill udevd worker threads |
| Changed in udev (Ubuntu Oneiric): | |
| milestone: | ubuntu-11.10 → oneiric-updates |
| status: | Confirmed → Triaged |
| Changed in linux (Ubuntu Precise): | |
| status: | New → Invalid |
| Changed in udev (Ubuntu Precise): | |
| status: | New → Triaged |
| importance: | Undecided → High |
| tags: |
added: rls-mgr-p-tracking removed: rls-mgr-o-tracking |
| Changed in ubuntu-release-notes: | |
| status: | New → Triaged |
| tags: | added: rls-mgr-o-tracking |
| tags: | added: iso-testing |
| Changed in udev (Ubuntu Oneiric): | |
| assignee: | James Hunt (jamesodhunt) → Steve Langasek (vorlon) |
| status: | Triaged → Fix Committed |
| tags: | added: kernel-da-key |
| Changed in udev (Ubuntu Oneiric): | |
| status: | Fix Released → In Progress |
| assignee: | Steve Langasek (vorlon) → Andy Whitcroft (apw) |
| tags: | removed: kernel-da-key |
| tags: |
added: verification-done removed: verification-needed |
Hmm, this now looks like some sort of race condition on based on a couple of issues. I've managed to boot successfully once in 10 attempts without any problems but more often than none I either get to a login prompt and no disks visible or stuck in a udev loop with the errors:
udev[90]: timeout: killing '/sbin/modprobe -bv pci:v000014E4d0
c02sc00i00' [178]
Lots and lots of the above shown, then finally:
bnx2: Can't load firmware file "bnx2/bnx2-
bnx2: 0000:05:00.0 PCI INT A disabled
bnx2: probe of 0000:05:00.0 failed with error -2