wubi install unusable - Buffer I/O error on device loop0
Bug #204133 reported by
Brian Murray
This bug affects 2 people
| Affects | Status | Importance | Assigned to | Milestone | |
|---|---|---|---|---|---|
| Wubi |
Fix Released
|
High
|
Agostino Russo | ||
| 8.04 |
In Progress
|
High
|
Agostino Russo | ||
| linux (Ubuntu) |
Invalid
|
Undecided
|
Unassigned | ||
| Hardy |
Invalid
|
Undecided
|
Unassigned | ||
| Intrepid |
Invalid
|
Undecided
|
Unassigned | ||
| lupin (Ubuntu) |
Fix Released
|
Undecided
|
Unassigned | ||
| Hardy |
Won't Fix
|
Undecided
|
Unassigned | ||
| Intrepid |
Fix Released
|
Undecided
|
Unassigned | ||
| ntfs-3g (Ubuntu) |
Fix Released
|
Undecided
|
Unassigned | ||
| Hardy |
Fix Released
|
Undecided
|
Unassigned | ||
| Intrepid |
Fix Released
|
Undecided
|
Unassigned | ||
Bug Description
LATEST ISO TESTED:
Ubuntu amd64 20080411 w/
wubi rev 482
ISO TESTED:
Ubuntu amd64 20080319
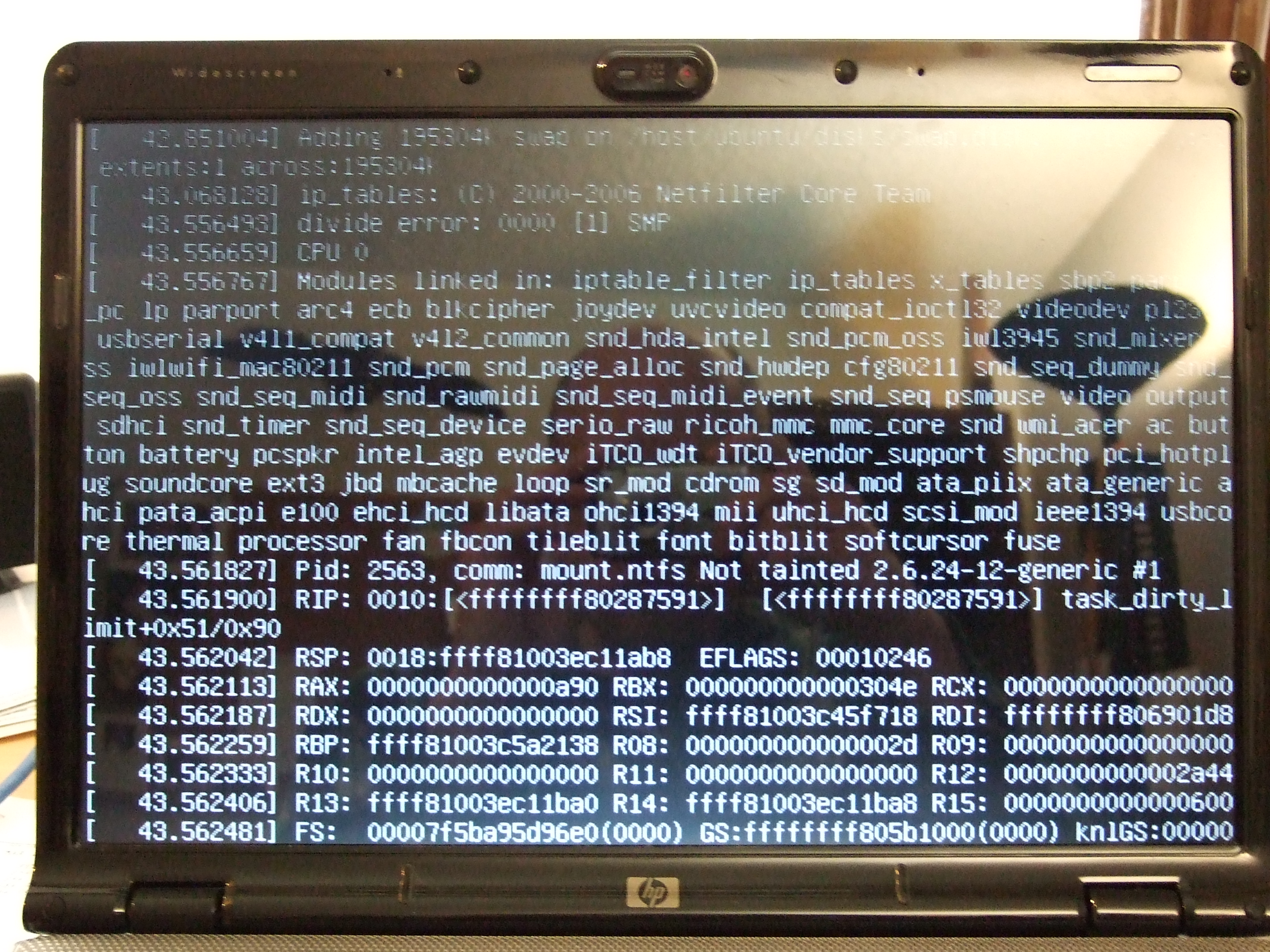
After what seemed to be a successful install via wubi I am unable to login to the system.
I booted into rescue mode and found in dmesg the following:
Buffer I/O error on device loop0, logical block 872512
lost page write due to I/O error, on loop0
...
EXT3-fs error (device loop0): ext3_get_inode_loc: unable to read inode block - inode=114030, block=229669
Aborting journal on device loop0.
__journal_
(repeat 6x)
Remounting filesystem read-only
Related branches

{kind=link}
{kind=link}
| Changed in wubi: | |
| assignee: | nobody → ago |
| importance: | Undecided → Medium |
| status: | New → Confirmed |
| description: | updated |
| description: | updated |
| Changed in wubi: | |
| status: | In Progress → Fix Released |
| Changed in ntfs-3g: | |
| status: | Fix Released → Fix Committed |
| Changed in wubi: | |
| assignee: | Agostino Russo (ago) → Kurupeththalage Sanath Rathna Kumara (ksrkumara) |
| status: | Fix Released → New |
| Changed in wubi: | |
| assignee: | Kurupeththalage Sanath Rathna Kumara (ksrkumara) → Agostino Russo (ago) |
| status: | New → Fix Released |
To post a comment you must log in.
Brian,
Were you by any chance using an amd64 image on VMWare?