
| Affects | Status | Importance | Assigned to | Milestone | |
|---|---|---|---|---|---|
| Linux |
Confirmed
|
Medium
|
|||
| linux (Ubuntu) |
Fix Released
|
High
|
Unassigned | ||
| Xenial |
Fix Released
|
High
|
Unassigned | ||
| Yakkety |
Fix Released
|
High
|
Unassigned | ||
Bug Description
As per bug 721896 and various others:
I'm on an AWS t2.micro instance (Xeon E5-2670, 991MiB of memory). Occasionally (about once a day), kswapd0 falls into a busy loop and spins on 100% CPU usage indefinitely. This can be provoked by copying/writing large files (e.g. dding a 256MB file), but it happens occasionally otherwise. System memory usage (not including buffers/caches) currently sits at 36%, which is typical[1]. Initially I had no swap space configured; I've since tried enabling a 256MB swap file, but the problem continues to occur and no swap space is used. The system can be recovered with `echo 1 > /proc/sys/
Happy to provide further information/take further debugging actions.
[1] Full output from `free`:
total used free shared buffers cached
Mem: 1014936 483448 531488 28556 9756 112700
-/+ buffers/cache: 360992 653944
Swap: 262140 0 262140
ProblemType: Bug
DistroRelease: Ubuntu 15.10
Package: linux-image-
ProcVersionSign
Uname: Linux 4.2.0-18-generic x86_64
AlsaDevices:
total 0
crw-rw---- 1 root audio 116, 1 Nov 19 19:40 seq
crw-rw---- 1 root audio 116, 33 Nov 19 19:40 timer
AplayDevices: Error: [Errno 2] No such file or directory: 'aplay'
ApportVersion: 2.19.1-0ubuntu5
Architecture: amd64
ArecordDevices: Error: [Errno 2] No such file or directory: 'arecord'
AudioDevicesInUse: Error: command ['fuser', '-v', '/dev/snd/seq', '/dev/snd/timer'] failed with exit code 1:
CRDA: N/A
Date: Fri Nov 20 20:44:30 2015
Ec2AMI: ami-1c552a76
Ec2AMIManifest: (unknown)
Ec2Availability
Ec2InstanceType: t2.micro
Ec2Kernel: unavailable
Ec2Ramdisk: unavailable
IwConfig: Error: [Errno 2] No such file or directory: 'iwconfig'
Lsusb: Error: command ['lsusb'] failed with exit code 1: unable to initialize libusb: -99
MachineType: Xen HVM domU
PciMultimedia:
ProcEnviron:
TERM=screen
PATH=(custom, no user)
LANG=en_US.UTF-8
SHELL=/bin/bash
ProcFB: 0 xen
ProcKernelCmdLine: BOOT_IMAGE=
RelatedPackageV
linux-
linux-
linux-firmware N/A
RfKill: Error: [Errno 2] No such file or directory: 'rfkill'
SourcePackage: linux
UdevLog: Error: [Errno 2] No such file or directory: '/var/log/udev'
UpgradeStatus: No upgrade log present (probably fresh install)
dmi.bios.date: 05/06/2015
dmi.bios.vendor: Xen
dmi.bios.version: 4.2.amazon
dmi.chassis.type: 1
dmi.chassis.vendor: Xen
dmi.modalias: dmi:bvnXen:
dmi.product.name: HVM domU
dmi.product.
dmi.sys.vendor: Xen
CVE References

|
|
#153 |
|
|
#154 |
(In reply to nleo from comment #0)
> kswapd0 randomly load one core of CPU by 100%
You cannot issue a SIGKILL to 'kswapd' since it is
a kernel thread.
> CommitLimit: 1967896 kB
> Committed_AS: 3498576 kB
Seem to be over committing memory.
|
|
#155 |
(switched to email. Please respond via emailed reply-to-all, not via the
bugzilla web interface).
On Tue, 19 Nov 2013 19:40:40 +0000 <email address hidden> wrote:
> https:/
>
> Bug ID: 65201
> Summary: kswapd0 randomly high cpu load
> Product: Memory Management
> Version: 2.5
> Kernel Version: 3.12
> Hardware: x86-64
> OS: Linux
> Tree: Mainline
> Status: NEW
> Severity: normal
> Priority: P1
> Component: Other
> Assignee: <email address hidden>
> Reporter: <email address hidden>
> Regression: No
>
> kswapd0 randomly load one core of CPU by 100%
>
> Linux localhost 3.12.0-1-ARCH #1 SMP PREEMPT Wed Nov 6 09:06:27 CET 2013
> x86_64
> GNU/Linux
>
> No swap enabled
>
> Befor on same laptop was installed Ubuntu 12.04 and kernel 3.2 32-bit pae,
> and
> there is no such problem.
>
> [root@localhost ~]# free -mh
> total used free shared buffers cached
> Mem: 3.8G 2.4G 1.3G 0B 150M 508M
> -/+ buffers/cache: 1.8G 2.0G
> Swap: 0B 0B 0B
hm, I wonder what kswapd is up to.
Could you please make it happen again and then
dmesg -n 7
dmesg -c
echo m > /proc/sysrq-trigger
echo t > /proc/sysrq-trigger
dmesg -s 1000000 > foo
then send us foo?
>
> [root@localhost ~]# cat /proc/meminfo
> MemTotal: 3935792 kB
> MemFree: 1381360 kB
> Buffers: 154216 kB
> Cached: 533096 kB
> SwapCached: 0 kB
> Active: 1958896 kB
> Inactive: 438004 kB
> Active(anon): 1740916 kB
> Inactive(anon): 136292 kB
> Active(file): 217980 kB
> Inactive(file): 301712 kB
> Unevictable: 0 kB
> Mlocked: 0 kB
> SwapTotal: 0 kB
> SwapFree: 0 kB
> Dirty: 2064 kB
> Writeback: 0 kB
> AnonPages: 1709628 kB
> Mapped: 196696 kB
> Shmem: 167620 kB
> Slab: 81516 kB
> SReclaimable: 61312 kB
> SUnreclaim: 20204 kB
> KernelStack: 1696 kB
> PageTables: 13088 kB
> NFS_Unstable: 0 kB
> Bounce: 0 kB
> WritebackTmp: 0 kB
> CommitLimit: 1967896 kB
> Committed_AS: 3498576 kB
> VmallocTotal: 34359738367 kB
> VmallocUsed: 361304 kB
> VmallocChunk: 34359300731 kB
> HardwareCorrupted: 0 kB
> AnonHugePages: 157696 kB
> HugePages_Total: 0
> HugePages_Free: 0
> HugePages_Rsvd: 0
> HugePages_Surp: 0
> Hugepagesize: 2048 kB
> DirectMap4k: 18476 kB
> DirectMap2M: 4059136 kB
>
> And I can't kill it. I heared that it's not good idea, but just for lulz)
>
> --
> You are receiving this mail because:
> You are the assignee for the bug.
|
|
#156 |
Created attachment 174671
kmsg dump
Sometimes I have same problem. I don't have swap. I have kernel 3.19.0 (i686) compiled without CONFIG_SWAP.
|
|
#157 |
My Acer C720 too suffers occasionally. Turning swap on/off doesn't help. Dropping caches *does* help:
# echo 3 > /proc/sys/
Next my guess would be to try to deactivate zswap.
|
|
#158 |
Zswap isn't to blame, dropping caches may help or may not. There's the output of `sudo perf top`:
26,24% [kernel] [k] _raw_spin_lock
14,72% [kernel] [k] _raw_spin_unlock
6,62% [kernel] [k] super_cache_count
4,97% [kernel] [k] shrink_slab.part.12
4,92% [kernel] [k] list_lru_count_one
2,15% [i2c_designware
1,86% [kernel] [k] shrink_lruvec
1,74% [kernel] [k] mem_cgroup_iter
1,61% [kernel] [k] native_read_tsc
1,55% [kernel] [k] delay_tsc
1,52% [kernel] [k] kswapd%
|
|
#159 |
(In reply to Anatoli Sakhnik from comment #4)
> My Acer C720 too suffers occasionally. Turning swap on/off doesn't help.
I have the same hardware. After system upgrade (current running kernel version 4.2.0) I get high CPU usage after "heavy" web site opens. If suggested workaround doesn't help (dropping caches), I just quit web browser and everything returns back to normal.
|
|
#160 |
Same here, also on an Acer C720 running arch. kswapd0 takes up a whole core whenever swap is being used. I run the Arch kernel, with a small patch to the chromos_laptop driver to enable my trackpad.
The weird thing is memory and swap both aren't that full. Memory is at 50% utilization, and swap is only at 8%, according to xfce4-taskmanager. It seems like Google Docs is the worst offender for triggering this issue.
|
|
#161 |
I had this bug, and for me it turned out to be my /tmp directory that
is a tmpfs (to gain speed and save my ssd).
df /tmp
gave
tmpfs 3880480 2449036 1431444 95% /tmp
After removing junk from /tmp/ the system returned to normal.
Also in my case I had no swap, and sufficient free memory.
Would be interested to know if this works for you.
| Sam Lade (sam-sentynel) wrote : | #1 |
- CurrentDmesg.txt Edit (35.3 KiB, text/plain; charset="utf-8")
- Dependencies.txt Edit (2.6 KiB, text/plain; charset="utf-8")
- JournalErrors.txt Edit (183.2 KiB, text/plain; charset="utf-8")
- Lspci.txt Edit (3.0 KiB, text/plain; charset="utf-8")
- ProcCpuinfo.txt Edit (799 bytes, text/plain; charset="utf-8")
- ProcInterrupts.txt Edit (1.7 KiB, text/plain; charset="utf-8")
- ProcModules.txt Edit (2.3 KiB, text/plain; charset="utf-8")
- UdevDb.txt Edit (92.1 KiB, text/plain; charset="utf-8")
- WifiSyslog.txt Edit (61.1 KiB, text/plain; charset="utf-8")
| Brad Figg (brad-figg) wrote : Status changed to Confirmed | #2 |
This change was made by a bot.
| Changed in linux (Ubuntu): | |
| status: | New → Confirmed |
| mecat (habdankm) wrote : | #3 |
same issue here:
root@orangepi:
Linux orangepi 3.4.39 #2 SMP PREEMPT Mon Oct 12 12:03:03 CEST 2015 armv7l armv7l armv7l GNU/Linux
root@orangepi:
DISTRIB_ID=Ubuntu
DISTRIB_
DISTRIB_
DISTRIB_
also
echo 1 > /proc/sys/
temporary solve issue
| Joseph Salisbury (jsalisbury) wrote : | #4 |
Did this issue start happening after an update/upgrade? Was there a prior kernel version where you were not having this particular problem?
Would it be possible for you to test the latest upstream kernel? Refer to https:/
If this bug is fixed in the mainline kernel, please add the following tag 'kernel-
If the mainline kernel does not fix this bug, please add the tag: 'kernel-
Once testing of the upstream kernel is complete, please mark this bug as "Confirmed".
Thanks in advance.
[0] http://
| Changed in linux (Ubuntu): | |
| importance: | Undecided → Medium |
| status: | Confirmed → Incomplete |
| tags: | added: kernel-da-key |
| Sam Lade (sam-sentynel) wrote : | #5 |
This was a clean build, so I don't have any information about previous versions unfortunately. (The previous server, which didn't have this issue, was different AWS hardware and the previous Ubuntu version.)
I've tested with the latest mainline kernel and this is still occurring.
| Changed in linux (Ubuntu): | |
| status: | Incomplete → Confirmed |
| tags: | added: kernel-bug-exists-upstream |
| Changed in linux (Ubuntu): | |
| status: | Confirmed → Triaged |
| Sean Groarke (sgroarke) wrote : | #6 |
Pretty much same description here. Started when I upgraded Amazon instance to 15.10.
Causing a lot of disruption - available to test also if it helps move us forward.
| Joseph Salisbury (jsalisbury) wrote : | #7 |
I'd like to perform a bisect to figure out what commit caused this regression. We need to identify the earliest kernel where the issue started happening as well as the latest kernel that did not have this issue.
Can you test the following kernels and report back? We are looking for the first kernel version that exhibits this bug:
4.0 Final: http://
4.1 Final: http://
4.2 Final: http://
You don't have to test every kernel, just up until the kernel that first has this bug. We can then narrow down further by testing some release candidates.
Thanks in advance!
| Changed in linux (Ubuntu): | |
| importance: | Medium → High |
| Sam Lade (sam-sentynel) wrote : | #8 |
Okay, I cloned my server and tried kernel versions. The latest version which does _not_ exhibit the issue is 3.12.51. The first which does is 3.13-rc1.
| Joseph Salisbury (jsalisbury) wrote : | #9 |
Thanks for testing, Sam. Could you also test the 3.12 final version, since 3.13-rc1 is the next linear version after 3.12 final. The kernel can be downloaded from:
| Sam Lade (sam-sentynel) wrote : | #10 |
3.12 final doesn't exhibit the issue either.
| Joseph Salisbury (jsalisbury) wrote : | #11 |
I started a kernel bisect between v3.12 final and v3.13-rc1. The kernel bisect will require testing of about 7-10 test kernels.
I built the first test kernel, up to the following commit:
5cbb3d216e20417
The test kernel can be downloaded from:
http://
Can you test that kernel and report back if it has the bug or not? I will build the next test kernel based on your test results.
Thanks in advance
| Sam Lade (sam-sentynel) wrote : | #12 |
No bug on that version.
| Joseph Salisbury (jsalisbury) wrote : | #13 |
I built the next test kernel, up to the following commit:
e1f56c89b040134
The test kernel can be downloaded from:
http://
Can you test that kernel and report back if it has the bug or not? I will build the next test kernel based on your test results.
Thanks in advance
| Sam Lade (sam-sentynel) wrote : | #14 |
No bug on that version.
| Joseph Salisbury (jsalisbury) wrote : | #15 |
I built the next test kernel, up to the following commit:
9073e1a804c3096
The test kernel can be downloaded from:
http://
Can you test that kernel and report back if it has the bug or not? I will build the next test kernel based on your test results.
Thanks in advance
| Sam Lade (sam-sentynel) wrote : | #16 |
Bug is present in this version.
| Changed in linux (Ubuntu): | |
| assignee: | nobody → Joseph Salisbury (jsalisbury) |
| status: | Triaged → In Progress |
| Joseph Salisbury (jsalisbury) wrote : | #17 |
I built the next test kernel, up to the following commit:
ab0169bb5cc4a5c
The test kernel can be downloaded from:
http://
Can you test that kernel and report back if it has the bug or not? I will build the next test kernel based on your test results.
Thanks in advance
| Sam Lade (sam-sentynel) wrote : | #18 |
No bug in that version.
| Joseph Salisbury (jsalisbury) wrote : | #19 |
I built the next test kernel, up to the following commit:
f080480488028bc
The test kernel can be downloaded from:
http://
Can you test that kernel and report back if it has the bug or not? I will build the next test kernel based on your test results.
Thanks in advance
| Sam Lade (sam-sentynel) wrote : | #20 |
Bug is present in this version.
| Joseph Salisbury (jsalisbury) wrote : | #21 |
I built the next test kernel, up to the following commit:
b746f9c7941f227
The test kernel can be downloaded from:
http://
Can you test that kernel and report back if it has the bug or not? I will build the next test kernel based on your test results.
Thanks in advance
| Sam Lade (sam-sentynel) wrote : | #22 |
No bug in that version.
| Joseph Salisbury (jsalisbury) wrote : | #23 |
I built the next test kernel, up to the following commit:
72c1253574a1854
The test kernel can be downloaded from:
http://
Can you test that kernel and report back if it has the bug or not? I will build the next test kernel based on your test results.
Thanks in advance
| Sam Lade (sam-sentynel) wrote : | #24 |
- kswapd0-kernel-oops.txt Edit (32.4 KiB, text/plain)
It's crashing on boot with this version. It's related to paging, so it might be relevant to the issue, so I've attached the full dmesg and here's the actual crash:
[ 3.716345] BUG: unable to handle kernel paging request at 000060ffc0002370
[ 3.720056] IP: [<ffffffff811a6
[ 3.720056] PGD 0
[ 3.720056] Oops: 0000 [#1] SMP
[ 3.720056] Modules linked in: ipt_MASQUERADE iptable_nat nf_nat_ipv4 nf_nat nf_conntrack_ipv4 nf_defrag_ipv4 xt_tcpudp xt_recent xt_conntrack nf_conntrack iptable_filter ip_tables x_tables autofs4 crct10dif_pclmul crc32_pclmul ghash_clmulni_intel aesni_intel aes_x86_64 lrw gf128mul glue_helper ablk_helper cryptd psmouse floppy pata_acpi
[ 3.720056] CPU: 0 PID: 4 Comm: kworker/0:0 Not tainted 3.12.0-
[ 3.720056] Hardware name: Xen HVM domU, BIOS 4.2.amazon 12/07/2015
[ 3.720056] Workqueue: events css_killed_work_fn
[ 3.720056] task: ffff88003da946b0 ti: ffff88003daac000 task.ti: ffff88003daac000
[ 3.720056] RIP: 0010:[<
[ 3.720056] RSP: 0000:ffff88003d
[ 3.720056] RAX: 0000000000000246 RBX: ffff88003d803a60 RCX: 000000000000053e
[ 3.720056] RDX: 000060ffc0002358 RSI: 0000000000000001 RDI: ffff88003c4e822c
[ 3.720056] RBP: ffff88003daadd20 R08: ffff88003cc55000 R09: 0000000000000004
[ 3.720056] R10: ffff88003c4e8000 R11: 0000000000000001 R12: 0000000000000000
[ 3.720056] R13: ffffea0000e0e980 R14: ffff88003c4e8000 R15: 0000000000000001
[ 3.720056] FS: 000000000000000
[ 3.720056] CS: 0010 DS: 0000 ES: 0000 CR0: 0000000080050033
[ 3.720056] CR2: 000060ffc0002370 CR3: 0000000036754000 CR4: 00000000001406f0
[ 3.720056] Stack:
[ 3.720056] ffffffff811a7bc8 ffff88003fffb780 ffffea0000e0e980 ffff88003cc55000
[ 3.720056] ffff88003c4e8000 ffff88003c4e822c ffff880036c1da00 ffffea0000e0e980
[ 3.720056] ffff88003fffbcc0 ffff88003d803a60 ffffea0000e0e9a0 ffff88003daadda8
[ 3.720056] Call Trace:
[ 3.720056] [<ffffffff811a7
[ 3.720056] [<ffffffff811a8
[ 3.720056] [<ffffffff811a8
[ 3.720056] [<ffffffff810de
[ 3.720056] [<ffffffff810e1
[ 3.720056] [<ffffffff81081
[ 3.720056] [<ffffffff81081
[ 3.720056] [<ffffffff81081
[ 3.720056] [<ffffffff81088
[ 3.720056] [<ffffffff81088
[ 3.720056] [<ffffffff816ff
[ 3.720056] [<ffffffff81088
[ 3.720056] Code: d6 00 55 00 4d 85 e4 4c 8b 55 c8 4c 8b 45 c0 0f 85 a5 00 00 00 41 8b 55 18 85 d2 0f 88 99 00 00 00 49 8b 96 30 02 00 00 45 89 fb <4c> 39 5a 18 0f 8c c2 00 00 00 44 89 f9 f7 d9 89 ce 65 48 01 72
[ 3.720056] RIP [<ffffffff811a6
| Joseph Salisbury (jsalisbury) wrote : | #25 |
Thanks for testing. I skipped that commit in the bisect, in case it's not related to the bug.
I built the next test kernel, up to the following commit:
cbbc58d4fdfab1a
The test kernel can be downloaded from:
http://
Can you test that kernel and report back if it has the bug or not? I will build the next test kernel based on your test results.
Thanks in advance
| Sam Lade (sam-sentynel) wrote : | #26 |
Same crash on that version.
| Joseph Salisbury (jsalisbury) wrote : | #27 |
I built the next test kernel, up to the following commit:
3b7834743f9492e
The test kernel can be downloaded from:
http://
Can you test that kernel and report back if it has the bug or not? I will build the next test kernel based on your test results.
Thanks in advance
| Sam Lade (sam-sentynel) wrote : | #28 |
That version has also crashed.
| mm (mtl-0) wrote : | #29 |
This bug is also affecting me on 2 (ident) Xubuntu 15.10 systems:
uname -a: ### 4.2.0-22-generic #27-Ubuntu SMP Thu Dec 17 22:57:08 UTC 2015 x86_64 x86_64 x86_64 GNU/Linux
cat /etc/lsb-release
DISTRIB_ID=Ubuntu
DISTRIB_
DISTRIB_
DISTRIB_
also
echo 1 or echo 3 > /proc/sys/
temporary solves the issue
| mm (mtl-0) wrote : | #30 |
Also see here: https:/
| Joseph Salisbury (jsalisbury) wrote : | #31 |
I built the next test kernel, up to the following commit:
d7876f1be40a162
The test kernel can be downloaded from:
http://
Can you test that kernel and report back if it has the bug or not? I will build the next test kernel based on your test results.
Thanks in advance
| Sam Lade (sam-sentynel) wrote : | #32 |
Crashed again.
| Joseph Salisbury (jsalisbury) wrote : | #33 |
I built the next test kernel, up to the following commit:
732e563373ffc57
The test kernel can be downloaded from:
http://
Can you test that kernel and report back if it has the bug or not? I will build the next test kernel based on your test results.
Thanks in advance
| Sam Lade (sam-sentynel) wrote : | #34 |
Crashed again.
| Joseph Salisbury (jsalisbury) wrote : | #35 |
I built the next test kernel, up to the following commit:
56aba608257b451
The test kernel can be downloaded from:
http://
Can you test that kernel and report back if it has the bug or not? I will build the next test kernel based on your test results.
Thanks in advance
| Sam Lade (sam-sentynel) wrote : | #36 |
Crashed again.
| Joseph Salisbury (jsalisbury) wrote : | #37 |
I built the next test kernel, up to the following commit:
59ab5a8f4445699
The test kernel can be downloaded from:
http://
Can you test that kernel and report back if it has the bug or not? I will build the next test kernel based on your test results.
Thanks in advance
| Sam Lade (sam-sentynel) wrote : | #38 |
Crashed again.
| Joseph Salisbury (jsalisbury) wrote : | #39 |
I built the next test kernel, up to the following commit:
98fda169290b3b2
The test kernel can be downloaded from:
http://
Can you test that kernel and report back if it has the bug or not? I will build the next test kernel based on your test results.
Thanks in advance
| Sam Lade (sam-sentynel) wrote : | #40 |
Crashed again.
| Joseph Salisbury (jsalisbury) wrote : | #41 |
I built the next test kernel, up to the following commit:
519192aaae38e24
The test kernel can be downloaded from:
http://
Can you test that kernel and report back if it has the bug or not? I will build the next test kernel based on your test results.
Thanks in advance
| Sam Lade (sam-sentynel) wrote : | #42 |
Crashed again.
| Øystein Gisnås (oystein-gisnas) wrote : | #43 |
Sorry for commenting in the middle of your ongoing work, but I struggle matching your findings to my own.
Just like Sam and Sean reported, I see the bug on EC2 t2.micro running 15.10. I can reproduce it on t2.small as well, but it takes a little longer as I have to exaust the free memory. I've installed several instances with different Ubuntu versions keeping everything the same. I only observe this bug on Ubuntu 15.10
All versions running the latest security updates:
14.04 (3.13.0-74): OK
15:04 (3.19.0-43): OK
15:10 (4.2.0-22): Not OK
If I understand the comments correctly, the hypothesis is that the bug was introduced between 3.12 final and 3.13-rc1. To me it seems to have been introduced between 3.19.0-43 and 4.2.0-22.
Is that worth double checking?
| Sam Lade (sam-sentynel) wrote : | #44 |
I've found that how easy it is to reproduce varies somewhat - some versions it's triggered at almost any file manipulation, others I've had to copy a couple of large files around at the same time or otherwise increase disk access while moving large files - but I can reproduce it absolutely consistently in the versions listed above. I've noticed that in the affected versions I get large kswapd0 CPU usage spikes while copying files around even if it doesn't always get stuck at 100% usage indefinitely (though I can always get it to do that with sufficient provocation), while unaffected versions kswapd0 hardly shows up in CPU usage no matter what I do.
| Øystein Gisnås (oystein-gisnas) wrote : | #45 |
Interesting. I think for now, I should assume that the problem I see is not the same bug. Although the symptoms are very similar with kswapd0 spinning at 100%, swap space not being used, echo 1 > /proc/sys/
| Sergii Koshel (s-s-koshel) wrote : | #46 |
Btw, it is very easy to reproduce with t2.nano type of AWS instance.
Linux ip-10-0-2-68 4.2.0-22-generic #27-Ubuntu SMP Thu Dec 17 22:57:08 UTC 2015 x86_64 x86_64 x86_64 GNU/Linux
| Øystein Gisnås (oystein-gisnas) wrote : | #47 |
- 15.04-kswapd0.log Edit (4.2 KiB, text/plain)
Could you share the exact commands to reproduce? I tried dd'ing to run out of memory on r2.micro (1GB memory). Please see the attached command logs. Is this comparable with your results?
What I find interesting is that on 15.04, it runs out of free memory and starts waiting for I/O (no noteworthy use of kswapd0), while on 15.10 it starts using kswapd0 up to 100%, even a while after the dd comand has completed.
Could you compare this with your own results?
Sergii/Sean: do you see the bug on any older kernel versions other than those who come with 15.10?
| Øystein Gisnås (oystein-gisnas) wrote : | #48 |
| Simon (sam-ua) wrote : | #49 |
Issue on AWS t2.micro
root@ip-
Linux ip-127-0-0-1 4.2.0-23-generic #28-Ubuntu SMP Sun Dec 27 17:47:31 UTC 2015 x86_64 x86_64 x86_64 GNU/Linux
root@ip-
DISTRIB_ID=Ubuntu
DISTRIB_
DISTRIB_
DISTRIB_
| mm (mtl-0) wrote : | #50 |
I can also confirm the issue on Amazon AWS t2.nano
Linux ip-172-31-5-83 4.2.0-22-generic #27-Ubuntu SMP Thu Dec 17 22:57:08 UTC 2015 x86_64 x86_64 x86_64 GNU/Linux
after DDing a 512Mb file:
top - 18:36:00 up 9 min, 1 user, load average: 1.03, 0.64, 0.30
Tasks: 74 total, 3 running, 71 sleeping, 0 stopped, 0 zombie
%Cpu(s): 0.5 us, 27.0 sy, 0.2 ni, 41.3 id, 9.8 wa, 0.0 hi, 0.0 si, 21.2 st
KiB Mem: 498852 total, 86092 used, 412760 free, 4852 buffers
KiB Swap: 0 total, 0 used, 0 free. 15444 cached Mem
PID USER PR NI VIRT RES SHR S %CPU %MEM TIME+ COMMAND
32 root 20 0 0 0 0 R 98.4 0.0 1:59.16 kswapd0
1 root 20 0 37432 2552 1044 S 0.0 0.5 0:02.77 systemd
2 root 20 0 0 0 0 S 0.0 0.0 0:00.00 kthreadd
3 root 20 0 0 0 0 S 0.0 0.0 0:00.00 ksoftirqd/0
5 root 0 -20 0 0 0 S 0.0 0.0 0:00.00 kworker/0:0H
6 root 20 0 0 0 0 S 0.0 0.0 0:00.02 kworker/u30:0
7 root 20 0 0 0 0 S 0.0 0.0 0:00.03 rcu_sched
8 root 20 0 0 0 0 S 0.0 0.0 0:00.00 rcu_bh
9 root 20 0 0 0 0 R 0.0 0.0 0:00.02 rcuos/0
10 root 20 0 0 0 0 S 0.0 0.0 0:00.00 rcuob/0
11 root rt 0 0 0 0 S 0.0 0.0 0:00.00 migration/0
12 root rt 0 0 0 0 S 0.0 0.0 0:00.00 watchdog/0
13 root 0 -20 0 0 0 S 0.0 0.0 0:00.00 khelper
14 root 20 0 0 0 0 S 0.0 0.0 0:00.00 kdevtmpfs
15 root 0 -20 0 0 0 S 0.0 0.0 0:00.00 netns
16 root 0 -20 0 0 0 S 0.0 0.0 0:00.00 perf
17 root 20 0 0 0 0 S 0.0 0.0 0:00.01 xenwatch
root@ip-
USER PID %CPU %MEM VSZ RSS TTY STAT START TIME COMMAND
root 1 0.4 0.5 37432 2552 ? Ss 18:26 0:02 /sbin/init
root 2 0.0 0.0 0 0 ? S 18:26 0:00 [kthreadd]
root 3 0.0 0.0 0 0 ? S 18:26 0:00 [ksoftirqd/0]
root 5 0.0 0.0 0 0 ? S< 18:26 0:00 [kworker/0:0H]
root 6 0.0 0.0 0 0 ? S 18:26 0:00 [kworker/u30:0]
root 7 0.0 0.0 0 0 ? S 18:26 0:00 [rcu_sched]
root 8 0.0 0.0 0 0 ? S 18:26 0:00 [rcu_bh]
root 9 0.0 0.0 0 0 ? S 18:26 0:00 [rcuos/0]
root 10 0.0 0.0 0 0 ? S 18:26 0:00 [rcuob/0]
root 11 0.0 0.0 0 0 ? S 18:26 0:00 [migration/0]
root 12 0.0 0.0 0 0 ? S 18:26 0:00 [watchdog/0]
root 13 0.0 0.0 0 0 ? S< 18:26 0:00 [khelper]
root 14 0.0 0.0 0 0 ? S 18:26 0:00 [kdevtmpfs]
root 15 0.0 0.0 0 0 ? S< 18:26 0:00 [netns]
root 16 0.0 0.0 0 0 ? S< 18:26 0:00 [perf]
root ...
| mm (mtl-0) wrote : | #51 |
I really tried hard DD'ing and filling up RAM but I really can not reproduce the issue under Ubuntu 15.04 on AWS EC2 nano. On my home server boxes that issue also didn't appear on Ubuntu 15.04 either - so I really think it was introduced between 15.04 and 15.10.
Linux ip-172-31-7-84 3.19.0-20-generic #20-Ubuntu SMP Fri May 29 10:10:47 UTC 2015 x86_64 x86_64 x86_64 GNU/Linux
root@ip-
DISTRIB_ID=Ubuntu
DISTRIB_
DISTRIB_
DISTRIB_
top - 19:17:38 up 45 min, 2 users, load average: 3.52, 2.91, 1.93
Tasks: 87 total, 3 running, 84 sleeping, 0 stopped, 0 zombie
%Cpu(s): 36.4 us, 13.3 sy, 0.0 ni, 0.0 id, 0.0 wa, 0.0 hi, 0.0 si, 50.3 st
KiB Mem: 499128 total, 492924 used, 6204 free, 8552 buffers
KiB Swap: 1048572 total, 18664 used, 1029908 free. 136340 cached Mem
PID USER PR NI VIRT RES SHR S %CPU %MEM TIME+ COMMAND
11405 root 20 0 127120 124140 1360 R 36.6 24.9 3:19.84 memtester
11425 root 20 0 168080 165052 1340 R 36.0 33.1 3:09.11 memtester
11797 root 20 0 7012 2724 1660 D 16.6 0.5 0:54.64 dd
12110 root 20 0 7012 2792 1728 D 7.7 0.6 0:01.19 dd
1190 root 20 0 0 0 0 D 2.0 0.0 0:00.98 kworker/u30+
32 root 20 0 0 0 0 S 1.0 0.0 0:01.62 kswapd0
1 root 20 0 35032 2020 1476 S 0.0 0.4 0:01.68 systemd
2 root 20 0 0 0 0 S 0.0 0.0 0:00.00 kthreadd
3 root 20 0 0 0 0 S 0.0 0.0 0:00.00 ksoftirqd/0
5 root 0 -20 0 0 0 S 0.0 0.0 0:00.00 kworker/0:0H
7 root 20 0 0 0 0 S 0.0 0.0 0:00.67 rcu_sched
8 root 20 0 0 0 0 S 0.0 0.0 0:00.00 rcu_bh
[...]
Total DISK READ : 3.88 K/s | Total DISK WRITE : 67.48 M/s
Actual DISK READ: 3.88 K/s | Actual DISK WRITE: 65.99 M/s
TID PRIO USER DISK READ DISK WRITE> SWAPIN IO COMMAND
12110 be/4 root 0.00 B/s 67.48 M/s 0.00 % 86.28 % dd if=/de~0096 bs=1M
1 be/4 root 0.00 B/s 0.00 B/s 0.00 % 0.00 % init
2 be/4 root 0.00 B/s 0.00 B/s 0.00 % 0.00 % [kthreadd]
3 be/4 root 0.00 B/s 0.00 B/s 0.00 % 0.00 % [ksoftirqd/0]
5 be/0 root 0.00 B/s 0.00 B/s 0.00 % 0.00 % [kworker/0:0H]
7 be/4 root 0.00 B/s 0.00 B/s 0.00 % 0.00 % [rcu_sched]
8 be/4 root 0.00 B/s 0.00 B/s 0.00 % 0.00 % [rcu_bh]
[...]
| Peet (peet44) wrote : | #52 |
This bug kinda makes me curious. I tried to reproduce this issue on a vm but I couldn't get kswapd0 into the 100% cpu state.
Isn't it possible to use kernel's lockdep feature to automatically detect the issue if it is an software lock or something like that?
| Sam Lade (sam-sentynel) wrote : | #53 |
For clarity here: I have not tested 15.04 and I can entirely believe that the issue doesn't appear on that version. I'm testing the specified kernel versions on Ubuntu 15.10 and the issue is reliably reproducible. It doesn't seem to depend on whether swap is enabled or how full the RAM is; large (~256MB) file writes are sufficient to provoke it. You'll see kswapd0 CPU usage spiking while writing large files; it doesn't always get stuck on 100%, but it's more likely to if the system has other disk activity (run another dd at the same time, grep a bunch of files, etc).
| Øystein Gisnås (oystein-gisnas) wrote : | #54 |
I've tested 15.10 with different versions, including mainline versions, and I can reproduce the bug on the following version: 4.4.0-040400-
As the latest 15.04 also gives the symptoms, I suspect it's not caused by a specific kernel versions. After downgrading and upgrading different packages between 15.04 and 15.10, I've narrowed it down to udev.
Could you all please try downgrading udev (and libudev1) to version 219-7ubuntu6, and see if the symptoms disappear. Note that you have to restart after the downgrade.
| mm (mtl-0) wrote : | #55 |
Thanks a lot for your hard work!
I tested it with Amazon EC2 15.10 and it seems that downgrading fixed it.
Now testing my Xubuntu Home Server.
| mm (mtl-0) wrote : | #56 |
Seems also to be fixed on my Xubuntu Home Servers. But I will report back later.
| mm (mtl-0) wrote : | #57 |
Update: Sadly not fixed for my Home Servers:
top - 19:19:36 up 45 min, 1 user, load average: 3,95, 3,81, 3,46
Aufgaben: 175 total, 4 running, 171 sleeping, 0 stopped, 0 zombie
%Cpu(s): 1,0 be, 44,8 sy, 1,8 ni, 14,3 un, 37,6 wa, 0,0 hi, 0,5 si, 0,0 st
KiB Mem: 1872072 total, 1847332 used, 24740 free, 7704 buffers
KiB Swap: 5130332 total, 75924 used, 5054408 free. 1048580 cached Mem
PID BENUTZER PR NI VIRT RES SHR S %CPU %MEM TIME+ COMMAND
39 root 20 0 0 0 0 R 92,4 0,0 35:48.75 kswapd0
2243 root 20 0 0 0 0 S 5,8 0,0 0:29.69 kworker/u4:1
2315 root 39 19 2367016 455472 6272 S 5,8 24,3 1:44.55 java
1 root 20 0 37832 3808 1828 S 0,0 0,2 0:01.92 systemd
2 root 20 0 0 0 0 S 0,0 0,0 0:00.00 kthreadd
3 root 20 0 0 0 0 S 0,0 0,0 0:04.14 ksoftirqd/0
5 root 0 -20 0 0 0 S 0,0 0,0 0:00.00 kworker/0:0H
7 root 20 0 0 0 0 S 0,0 0,0 0:02.52 rcu_sched
8 root 20 0 0 0 0 S 0,0 0,0 0:00.00 rcu_bh
9 root 20 0 0 0 0 R 0,0 0,0 0:02.38 rcuos/0
10 root 20 0 0 0 0 S 0,0 0,0 0:00.00 rcuob/0
| Sam Lade (sam-sentynel) wrote : | #58 |
I can't reproduce with the older version of udev either. However, I think this is still a kernel issue, apparently triggered by an interaction with a recent change in udev. Finding the change to udev that causes this could be instructive for figuring out what the underlying kernel issue is, but I disagree that this isn't related to specific kernel versions - as demonstrated above I have the point at which this starts happening to within a few revisions of the kernel, with the same version of udev.
| Øystein Gisnås (oystein-gisnas) wrote : | #59 |
Agreed. That means we may have two possible leads for finding the culprit.
Are there any seasoned kernel and systemd/udev persons that could look at the changelog and make a guess at which commits we should test? The alternative is to continue to bisect the kernel and also start bisecting udev.
| Sam Lade (sam-sentynel) wrote : | #60 |
- ftrace of kswapd0 exhibiting issue Edit (1.1 MiB, text/plain)
So, I've had an exciting evening armed with ftrace and a kernel debugger. I'm questioning my own sanity a bit here, but I'm fairly sure at this point that setting ftrace going and loading the kernel debugging module (I'm using kgdboe here because I'm on AWS) stop whatever the issue is from happening - kswapd0's CPU usage doesn't even increase with them enabled, never mind run out of control. However, it *is* possible to trigger issue and then enable ftrace or load the debug module and break in. I haven't found the debugger super useful, though I did manage to break into kswapd0 while it was doing things at one point, so it's potentially an option if necessary. ftrace looked more useful; I've attached a trace of an arbitrary time slice taken with the issue happening. Happy to do extra work with either if these if anyone has further ideas.
| Joseph Salisbury (jsalisbury) wrote : | #61 |
The bisect indicated the following commit as the first bad commit:
commit 519192aaae38e24
Author: Thomas Huth <email address hidden>
Date: Mon Sep 9 17:32:56 2013 +0200
KVM: Add documentation for kvm->srcu lock
However, this commit is only a documentation change, so it's probably not the real cause of the issue. We may need to go back through and test all the bisect test kernels again to see if we marked good or bad incorrectly.
| Sam Lade (sam-sentynel) wrote : | #62 |
I found an issue with the image I've been cloning test VMs from which may have affected test results. I've got my own kernel builds set up now and am rerunning the bisect. Will let you know what I find.
| Marten van Wezel (g-u5untu-y) wrote : | #63 |
FWIW this affects me too. I installed pretty much exactly the same installation (Ubuntu + Kodi + Steam) on two Mac minis, two days ago.
You can compare the devices if you wish - MacMini 4,1 and 5,1 respectively. 4,1 works fine, 5,1 does not. https:/
Notable differences: Intel HD 3000 video on the broken 5,1 device, NVidia GT320M on working 4,1 device. Some other things as well.
Also, it seemed to coincide a few times with 'video card state changes', ie. screen saving on, etc. Could be total coincidence
| Marten van Wezel (g-u5untu-y) wrote : | #64 |
As an addendum, is there a quick-fix for this? Meaning: can I revert to kernel 3.xsomething easily in Ubuntu? Or are there all types of unwelcome side effects to dropping from new-hotness to old-coldness, kernel-wise?
signed, pro linux sysadmin for many years, back in the 2000's, now only recently gotten back into it for only my home purposes, so I'm completely behind on how kernel stuff fits together with things. (where are my /dev/ devices, sob).
| Sean Groarke (sgroarke) wrote : | #65 |
Marten
Not a fix, but a workaround. (Well, of course every server is different - but works good for me for now....!)
Create in /etc/cron.hourly/ something like kswapd.
chmod +x kswapd
Then into it drop:
echo 1 > /proc/sys/
You'll get a lot of
[649613.095072] kswapd (29670): drop_caches: 1
in your dmesg/syslog.
But for me, this works great. Of course it depends on the bug not occurring within the first hour of the "fix" being applied (i.e. cron.hourly). And clearly this will vary from box to box. But on my AWS server (low traffic web-server with a few other odds and sods on it) this has effectively "solved" this issue enough, until we get a full fix.
Sean
| Marten van Wezel (g-u5untu-y) wrote : | #66 |
Egads, the thick plottens... turns out I have some type of error in my system. In particular:
marten@
MemTotal: 859916 kB
Yes you read that right, 860Mb. That's clearly incorrect. I'll go and see if I can put in something better. For this thread though this might be a good hint on how to debug things.
Sean- To your point - Yeah I have a 'fixkswapd' script that says:
marten@
schedtool -D -n 19 `pidof kswapd0`
echo 1 > /proc/sys/
Maybe my system has an *actual* memory problem rather than a bug. I'll report back if/when I fix this.
| Marten van Wezel (g-u5untu-y) wrote : | #67 |
Instant-update:
So indeed I had a broken memory module. I had installed 2x1GB, but only 1 showed. (the 860 is due to the video controller using 200-odd MB system RAM)
Now back up and running with 4GB . Will report back if I encounter the issue again (I haven't put the crontab fix in place so I'll be able to notice the issue if it happens, if not, perhaps my stumbling about might've given you guys a few datapoints.. perhaps broken ram is the cause, or perhaps ultra-low ram.
| Dennis Stevense (decafdennis) wrote : | #68 |
A workaround that seems to work for me (and one that doesn't involve dropping caches periodically) is to downgrade udev to 219-7ubuntu6 (as suggested by Øystein above). On 15.10 wily, add vivid-updates to your apt sources to be downgrade to this version of udev.
I noticed this bug is more likely to occur on servers with less memory / more memory pressure. I was only able to reproduce it on our t2.micro and t2.small instances on EC2, and using larger EC2 instances was our first workaround. (In fact, after downgrading udev I was also downgrade to smaller EC2 instances again.)
This bug also seems more likely to occur on servers with faster disk I/O, given I was only able to reproduce it on instances with gp2 (SSD) storage and not on standard (magnetic) storage on EC2.
Our use case is a bunch of EC2 instances all using the Ubuntu 15.10 wily AMI, and currently running the latest 4.2.0-23-generic kernel.
| Øystein Gisnås (oystein-gisnas) wrote : | #69 |
I've bisected systemd and found the commit that triggers the bug. http://
A working workaround on the latest 15.10 is to comment out line 2 (ATTR{[
| Øystein Gisnås (oystein-gisnas) wrote : | #70 |
Could someone with good udev/kernel knowledge try to debug what's going wrong with this hotadd? I've tried to run systemd-udevd in debug mode, but it didn't show anything of interest. https:/
| Nelson Elhage (nelhage) wrote : | #71 |
I did some experimentation, and I can reproduce @oystein-gisnas's result that nuking that file from `/lib/udev/
However, removing that file and restarting udev does *not* seem to fix the issue. So I suspect the problem is not with udev, but rather with some kernel feature that udev is enabling or toggling as part of processing that file.
Also, as an aside, editing that file isn't a good workaround, since upgrading udev may clobber it again. If you instead create an `/etc/udev/
| Dennis Stevense (decafdennis) wrote : | #72 |
Confirmed Nelson Elhage's workaround: copy /lib/udev/
| Nelson Elhage (nelhage) wrote : | #73 |
Some further debugging: On my t2.micro test case, the machine comes up with 9 memory devices, the last of which is offline at boot. Bringing that device online by hand (with the udev rules disabled) triggers the bug.
# echo online > /sys/devices/
So something about bringing that node online causes the problem. The udev bugfix causes udev to automatically bring it up, which is why that introduced the issue, but it doesn't seem like udev is really the root problem here.
|
|
#162 |
same problem here, c720p chromebook , happens on several different distros like arch, ubuntu, xubuntu. I downgraded to the 4.1.x kernel and the issue is less frequent (needs much more memory pressure to trigger). then I downgraded to the 3.17 kernel and the issue is gone completely. all the previous suggestions and workarrounds didn't work for me. only downgrading the kernel did.
| Changed in linux (Ubuntu): | |
| status: | In Progress → Confirmed |
| assignee: | Joseph Salisbury (jsalisbury) → nobody |
| Nelson Elhage (nelhage) wrote : | #74 |
One more note to anyone else trying to debug this: I can reproduce quite reliably by copying a 3GiB file from S3 onto a gp2 EBS volume using `aws s3 cp`.
| mm (mtl-0) wrote : | #75 |
As part of my workaround/fix I downgraded udev and upgraded RAM from 3GB to 8GB on my homeserver.
Now I am experiencing the following which can't be normal either:
top - 13:50:48 up 1 day, 19:29, 1 user, load average: 0,11, 0,15, 0,14
tasks: 200 total, 1 running, 198 sleeping, 0 stopped, 1 zombie
%Cpu(s): 6,1 be, 2,5 sy, 0,2 ni, 81,6 un, 9,1 wa, 0,0 hi, 0,4 si, 0,0 st
KiB Mem: 8067248 total, 4768336 used, 3298912 free, 477524 buffers
KiB Swap: 4194300 total, 4170948 used, 23352 free. 2803672 cached Mem
Filename Type Size Used Priority
/var/cache/
Linux ##### 4.2.0-25-generic #30-Ubuntu SMP Mon Jan 18 12:31:50 UTC 2016 x86_64 x86_64 x86_64 GNU/Linux
Any idea? I hope the system won't crash ....
|
|
#163 |
Same problem here on Acer C720 Chromebook. I have 2GB of swap space on the SSD (I replaced the original 16GB M2 SSD with a 256GB version) and whenever swap is used I get this problem.
Linux localhost 4.2.0-27-generic #32-Ubuntu SMP Fri Jan 22 04:49:08 UTC 2016 x86_64 x86_64 x86_64 GNU/Linux
lsb_release -a
No LSB modules are available.
Distributor ID: Ubuntu
Description: Ubuntu 15.10
Release: 15.10
Codename: wily
echo 3 > /proc/sys/
|
|
#164 |
I didn't suffer from the bug since compiled kernel myself: https:/
|
|
#165 |
(In reply to Anatoli Sakhnik from comment #11)
> I didn't suffer from the bug since compiled kernel myself:
> https:/
> something causing the trouble, but I didn't try to bisect what was the
> culprit.
This bug seems to affect 2Gb models only. Do you have the 2Gb or 4Gb version? What are the changes you made on your kernel?
|
|
#166 |
Mine is 2G. I didn't change anything in the kernel source code, but switched off many options in the config file: https:/
Even today, if I boot stock arch kernel, the bug regresses; if I boot linux-c720, kswapd0 is still. In theory, I could experiment with different configurations in between stock's and mine to triage the issue.
|
|
#167 |
perhaps you removed something related to
http://
also relevant:
https:/
|
|
#168 |
I have no idea yet.
|
|
#169 |
To avoid this bug I installed ChromeOS on my C720 (with 2GB RAM). I was happy with performance. Until today. I noticed lags. For some reason this bug appeared suddenly. There was no update. Kernel version is 3.8.11. Stock ChromeOS kernel.
|
|
#170 |
(In reply to Anatoli Sakhnik from comment #13)
> Mine is 2G. I didn't change anything in the kernel source code, but switched
> off many options in the config file:
> https:/
>
> Even today, if I boot stock arch kernel, the bug regresses; if I boot
> linux-c720, kswapd0 is still. In theory, I could experiment with different
> configurations in between stock's and mine to triage the issue.
could you please share your configuration for the kernel so I can try your AUR package and solve this issue once for all :) ? thanks in advance
|
|
#171 |
|
|
#172 |
We encounter this regularly on AWS, but only on t2.small instances, which indeed are the only ones we run which have 2GB of RAM.
We use the latest Ubuntu 15.10 AMIs as found here https:/
| JockeTF (jocketf) wrote : | #76 |
I'm seeing this issue in Ubuntu Xenial Xerus (development branch).
|
|
#173 |
The workaround suggested above (echo 3 > /proc/sys/
I've found another workaround that works well for me so far: create a file /etc/sysctl.
vm.min_
The idea behind this workaround is a post by Kirill A. Shutemov on LKML (http://
Would be interesting to know if this helps others
|
|
#174 |
Same problem here:
- No swap machine
- Wily (U15.10) - 4.2.0-19-generic #23-Ubuntu SMP Wed Nov 11 11:39:30 UTC 2015 x86_64 x86_64 x86_64 GNU/Linux
- 1GB RAM
- `meminfo` - Should have enough RAM to not swap though buffers do seem high
MemTotal: 1014932 kB
MemFree: 231296 kB
MemAvailable: 871180 kB
Buffers: 580684 kB
Cached: 47812 kB
SwapCached: 0 kB
Active: 547952 kB
Inactive: 164364 kB
Active(anon): 84280 kB
Inactive(anon): 4288 kB
Active(file): 463672 kB
Inactive(file): 160076 kB
Unevictable: 0 kB
Mlocked: 0 kB
SwapTotal: 0 kB
SwapFree: 0 kB
Dirty: 224 kB
Writeback: 0 kB
AnonPages: 83800 kB
Mapped: 39688 kB
Shmem: 4768 kB
Slab: 48008 kB
SReclaimable: 31172 kB
SUnreclaim: 16836 kB
KernelStack: 1936 kB
PageTables: 3844 kB
NFS_Unstable: 0 kB
Bounce: 0 kB
WritebackTmp: 0 kB
CommitLimit: 507464 kB
Committed_AS: 314640 kB
VmallocTotal: 34359738367 kB
VmallocUsed: 13524 kB
VmallocChunk: 34359717628 kB
HardwareCorrupted: 0 kB
AnonHugePages: 49152 kB
CmaTotal: 0 kB
CmaFree: 0 kB
HugePages_Total: 0
HugePages_Free: 0
HugePages_Rsvd: 0
HugePages_Surp: 0
Hugepagesize: 2048 kB
DirectMap4k: 53248 kB
DirectMap2M: 1126400 kB
- kernel config: https:/
- strace shows nothing interesting
- `perf` report:
Samples: 12K of event 'cpu-clock', Event count (approx.): 3245250000
Overhead Command Shared Object Symbol
19.34% kswapd0 [kernel.kallsyms] [k] shrink_lruvec
17.04% kswapd0 [kernel.kallsyms] [k] mem_cgroup_iter
8.60% kswapd0 [kernel.kallsyms] [k] mem_cgroup_
6.57% kswapd0 [kernel.kallsyms] [k] shrink_slab
5.47% kswapd0 [kernel.kallsyms] [k] global_dirty_limits ...
|
|
#175 |
Cont'd from previous post
In order of attempts on a live system:
- gdb didn't work at all since kernel wasn't built w/ debugging flags
- hotload of 10 and 0 swappiness (from 60) didn't make the kswapd process reduce cpu usage
- hotload of vm.min_
- hotload of vm.dirty_
- hotload of vm.dirty_ratio=10 (from 20) didn't make the process reduce cpu usage
- hotload of vm.dirty_
- hotload of vm.dirty_ratio=25 (from 10) didn't make the process reduce cpu usage
- live swapon on a new 256MB swapfile didn't reduce process use
- live swapoff and swapon after that also didn't drop cpu usage
Sidenote: We're using Docker so I'm not sure if that is contributing to the situation.
| Alexander Mashin (alex-mashin) wrote : | #77 |
I confirm that the bug is present on Amazon t2.nano instance with Ubuntu 15.10, kernel 4.2.0-30-generic, and can only be worked around by commenting out line 2 in /lib/udev/
| JockeTF (jocketf) wrote : | #78 |
The workaround fixes the issue in Xenial Xerus (development branch) as well.
| Alexander Mashin (alex-mashin) wrote : | #79 |
I don't know, if the following comment be relevant to this particular bug, but here it is:
* If there is no swap, the kernel should not try to swap. As simple as this. If there is no swap file or partition, and there is kswapd0 in top, if even it doesn't consume 100% of CPU, it is a bug. Sysadmins are entitled to forbid swapping altogether (because it's evil, as on a web server swapping is effectively deny of service), and the most natural way to do so is not to mount a swap partition.
* If there is cached memory, there should be no swapping. Memory must be freed by flushing file buffers first. It is ridiculous that the kerner is generous to filesystems, caching their files, but not to the applications that really need memory, allowing either to swap or fork to fail. At the moment there is a misleading article somewhere in the Ubuntu knowledge base that claims that cached memory is not "eaten" and is as available as free. As long as the kernel is allowed to swap when there are file buffers, the latter are NOT free and available.
|
|
#176 |
Good news! I was able to get rid of the bug completely by setting the `mem` kernel parameter to a value slightly less than physical memory. I own an Acer C720 (2GB model), and setting `mem=1920M` does the job.
The idea sprung up in my head after reading the aforementioned bug report on github[1]. I hope this might give some clue to the issue.
[1]: https:/
|
|
#177 |
Created attachment 208411
ftrace (function_graph)
|
|
#178 |
Created attachment 208421
ftrace (vmscan tracepoints)
|
|
#179 |
Created attachment 208431
/proc/vmstat (time 0)
|
|
#180 |
Created attachment 208441
/proc/vmstat (time 5s)
|
|
#181 |
Created attachment 208451
/proc/zoneinfo
|
|
#182 |
Created attachment 208461
/proc/pagetypeinfo
|
|
#183 |
Created attachment 208471
/proc/buddyinfo
|
|
#184 |
Created attachment 208481
vmstat -m (time 0)
|
|
#185 |
Created attachment 208491
vmstat -m (time 5s)
|
|
#186 |
I am able to semi-reliably reproduce this (or very similar?) problem on a setup very close to one in comment #21
- kernel: 4.2.0-30-generic (ubuntu 15.10)
- 2 GB RAM, 1 CPU, running under Xen (EC2 t2.small instance)
- docker with LVM thin-pool storage backend, running 3 containers, no memory limits set for their memcg's
- server is mostly idling (load average 0.0-0.1)
To reproduce it I have to:
1. set vm.overcomit_
2. initiate some disk activity:
find -xdev / -type f |xargs -P10 -n1 md5sum &>/dev/null &
find /var/lib/docker -type f |xargs -P10 -n1 md5sum &>/dev/null &
3. run some memory allocations until you hit OOM
for x in {1..200}; do ./memalloc & : ; done
memalloc above is a simple C program which allocates 100MB and memsets it with 'x':
#include <stdio.h>
#include <stdlib.h>
#include <string.h>
#include <unistd.h>
int main(int argc, char *argv[])
{
int block_mb = 100;
char *buf;
printf("allocing %dMB: ", block_mb);
buf = malloc(block_mb * 1024 * 1000);
if (! buf) {
printf(
exit(
}
printf("ok\n");
memset(buf, 'x', block_mb * 1024 * 1000);
sleep(180);
return 0;
}
once you hit OOM, console slows down, it is time to CTRL+C, pkill memalloc and then check top. many times it spins `kswapd0` then recovers within tens of seconds, but once in a while it stays there for hours (didn't have patience to check for longer).
Once I triggered bug, I tried to get as much information as possible from running system. I am attaching /proc/*info files (some taken 5 s apart), ftrace outputs for event tracer (vmscan events only), ftrace output for function_graph tester. Let me know if you need more information.
To recover from situation need to free enough memory in a short period of time, sometime dropping caches helps, sometimes needed to close applications/
|
|
#187 |
It would be very helpful if there was a way to get output similar to ftrace function_graph tracer, but with function args and return values, but from the look of it, `pgdat_balance` for some reason keeps returning false even that /proc/zoneinfo shows that number of free pages is much higher than any watermark.
Problem description and recovery method very closely resembles discussion around kernel 3.7 (https:/
> The zonelist reclaim in kswapd would do
> nothing because all high watermarks are met, but the compaction logic
> would find its own requirements unmet and loop over the zones again.
> Indefinitely, until some third party would free enough memory to help
> meet the higher compaction watermark.
| Greg Fefelov (gfv) wrote : | #80 |
Alexander,
please note that if a kernel process name contains "swap" as a substring, it does not immediately mean that this process exclusively does process memory swap-in/swap-out. kswapd is a kernel process name for an important piece of memory management subsystem: it frees pages by flushing them to disk or discarding when the system is low on memory, saving you the trouble of OOMs. This includes both buffer cache and process memory; however, disk buffers are freed first.
Generally that means that on a system with disabled swap you _will_ see high cpu% in kswapd when you have almost no memory and buffers have not been synced to disk yet. This is not a bug (but you should consider installng more memory or having a stricter sync policy).
However, this discussion is very off topic, since this bug is not an intended behavior.
| Reupen Shah (reupen) wrote : | #81 |
This has also been affecting me on a t2.micro EC2 instance with Ubuntu 15.10, most recently occurred with:
4.2.0-30-generic #36-Ubuntu SMP Fri Feb 26 00:58:07 UTC 2016 x86_64 x86_64 x86_64 GNU/Linux
For me it often triggers when installing updates (probably kernel ones in particular). Otherwise the server is not doing much so probably not much of a surprise it doesn't trigger on other occasions.
| Islam (islam) wrote : | #82 |
This is also affecting Ubuntu 15.10 Kernel 4.2.0-35-generic
I have 700MB free RAM 400 MB Cached and kswapd0 is taking more than 99% of the CPU.
| antgel (antgel) wrote : | #83 |
After reading 82 comments, I'm not sure if this is a kernel or udev (or other) bug. Any clues if anyone's working on this in relevant upstreams?
| mallardquacken (mallard) wrote : | #84 |
confirmed on released version of 16.04 LTS desktop
# uname -a
Linux laptop 4.4.0-21-generic #37-Ubuntu SMP Mon Apr 18 18:33:37 UTC 2016 x86_64 x86_64 x86_64 GNU/Linux
| mm (mtl-0) wrote : | #85 |
I can also confirm the bug ist still present in Xubuntu 16.04 LTS desktop
4.4.0-21-generic #37-Ubuntu SMP Mon Apr 18 18:33:37 UTC 2016 x86_64 x86_64 x86_64 GNU/Linux
| mm (mtl-0) wrote : | #86 |
I can confirm this bug is only triggered when the machine got 2-3GB RAM or less. I got two identical machines running Ubuntu 16.04. One got 8Gb of RAM and on this machine kswapd0 doesn't deadlock at 100% CPU Usage. On my 2GB RAM machine the issue is worse than under Ubuntu 15.10 ....
| Andreas E. (andreas-e) wrote : | #87 |
In the earliest linked report of this bug the deadlock occured also with 8GB RAM (and still the case in 15.10). Will test 16.04 later when it stabilizes.
| erik (erik-eriksson) wrote : | #88 |
I can see this bug on a system recently upgraded from Ubuntu 15.04 to 16.04.
I did not see this behaviour before upgrading.
The system is an Intel NUC Desktop with 8 GB RAM and kswapd0 completely locks up the system after a while.
|
|
#188 |
(In reply to Anatoli Sakhnik from comment #4)
> My Acer C720 too suffers occasionally. Turning swap on/off doesn't help.
> Dropping caches *does* help:
>
> # echo 3 > /proc/sys/
>
> Next my guess would be to try to deactivate zswap.
above work around works for me, kernel 4.4.2 debian jessie.
bug happens randomly after heavy web browsers for kernel 4.5
downgrade to 3.16 stable jessie kernel, bug gone.
upgrade 4.4.2 bug came again
| Impulse (kristal-plus) wrote : | #89 |
Confirm.
Linux impulse-X55VD 4.6.0-040600rc6
| Gregg King (greggking) wrote : | #90 |
I'm also seeing this on 16.04 on an AWS nano (~0.5GB RAM). More than happy to help troubleshoot this if people let me know what info is needed.
Here's some basic info from my machine:
$ uname -a
4.4.0-22-generic #39-Ubuntu SMP Thu May 5 16:53:32 UTC 2016 x86_64 x86_64 x86_64 GNU/Linux
$ free -m
total used free shared buff/cache available
Mem: 486 73 140 20 272 362
Swap: 0 0 0
$ top
top - 01:44:48 up 3 days, 2:34, 1 user, load average: 1.00, 1.01, 1.05
Tasks: 131 total, 2 running, 129 sleeping, 0 stopped, 0 zombie
%Cpu(s): 0.0 us, 90.9 sy, 0.0 ni, 9.0 id, 0.0 wa, 0.0 hi, 0.0 si, 0.0 st
KiB Mem : 498480 total, 143612 free, 75852 used, 279016 buff/cache
KiB Swap: 0 total, 0 free, 0 used. 370732 avail Mem
PID USER PR NI VIRT RES SHR S %CPU %MEM TIME+ COMMAND
29 root 20 0 0 0 0 R 99.9 0.0 4066:36 kswapd0
1 root 20 0 37908 6028 4048 S 0.0 1.2 0:08.79 systemd
2 root 20 0 0 0 0 S 0.0 0.0 0:00.00 kthreadd
----- CUT THE REST -----
| François Leurent (131-ubuntu) wrote : | #91 |
Same issue here, uname -a
4.4.0-22-generic #39-Ubuntu SMP Thu May 5 16:53:32 UTC 2016 x86_64 x86_64 x86_64 GNU/Linux
free -m
total used free shared buff/cache available
Mem: 1836 68 1608 12 159 1722
Swap: 1949 0 1949
(i'll edit this in a few minute, with top result (uptime is 0s)
| mb (doitnow) wrote : | #92 |
- Screenshot from 2016-05-19 15:25:29.png Edit (45.4 KiB, image/png)
{kind=link}
Fresh install of 16.04 on EC2 Nano instance, and kswapd0 takes most of the CPU when running a job with high CPU and high IO.
I've resorted to running the following command every minute as a cron task:
# m h dom mon dow command
* * * * * echo 3 > /proc/sys/
That works for 10 or 15 seconds, but after that kswapd0 comes back and hogs the CPU again.
I'm using less than 20% of available memory, shouldn't need to swap.
See attached screenshot of top at the 25-second mark after dropping caches.
| mm (mtl-0) wrote : | #94 |
I can the following hotfix works for me for several days on a 2GB Ram system:
echo "vm.min_
after that: reboot.
| mm (mtl-0) wrote : | #95 |
I can confirm after after 6 days uptime: my hotfix (echo "vm.min_
| MintPaw (jerusanders) wrote : | #96 |
I can confirm that setting vm.min_
{kind=link}
After restarting and running heavy processes, kswapd0 still uses 100% cpu until I reboot or run this follow very unfortunate script.
#!/bin/bash
if [ "$EUID" -ne 0 ]; then
echo "Rerunning as root"
sudo $0
exit
fi
swapoff -a
sleep 1
echo 3 > /proc/sys/
sleep 1
swapon /dev/sda2
| Haw Loeung (hloeung) wrote : | #97 |
OOI, does this fix this?
| for i in /sys/devices/
If so, was the scaling governor set to "ondemand" by any chance?
| MintPaw (jerusanders) wrote : | #98 |
They seem to be set to "powersave", which is kinda ironic. I've set them to performance and will report back later.
| MintPaw (jerusanders) wrote : | #99 |
Nope, setting it to performance doesn't seems to help.
| MintPaw (jerusanders) wrote : | #100 |
Actually, this is even a problem with no active swap partition. What is the actual problem here? Is kswapd0 just running for no reason?
| Jonathan Vargas (jvargas-alkaid) wrote : | #101 |
- Selection_320.png Edit (237.7 KiB, image/png)
{kind=link}
I face the same issue, running a t2.micro (1 GB) for a Nginx/Ruby application with really low demand. The kswapd0 process takes the CPU to 100% and the overall system performance is downgraded.
Linux server 4.4.0-22-generic #40-Ubuntu SMP Thu May 12 22:03:46 UTC 2016 x86_64 x86_64 x86_64 GNU/Linux
To reproduce it, I just create a 1GB file in the filesystem using "dd":
if=/dev/zero of=temp bs=1k count=1024k
I created a swap file to solve the issue but it continues. After dropping the page cache with:
echo 3 > /proc/sys/
the issue is solved temporarily.
| Gregg King (greggking) wrote : Re: [Bug 1518457] Re: kswapd0 100% CPU usage | #102 |
I've had the issue mostly when running with no swap. I added 1GB swap file and it fixed it on the machine with less memory usage, but the machine with the database (using more memory most of the time) still has the bug occur about once a day.
Ubuntu 16.04 for both, not happening on 14.04.
Sent from my iPhone
> On Jun 4, 2016, at 5:11 PM, Jonathan Vargas <email address hidden> wrote:
>
> I face the same issue, running a t2.micro (1 GB) for a Nginx/Ruby
> application with really low demand. The kswapd0 process takes the CPU to
> 100% and the overall system performance is downgraded.
>
> Linux server 4.4.0-22-generic #40-Ubuntu SMP Thu May 12 22:03:46 UTC
> 2016 x86_64 x86_64 x86_64 GNU/Linux
>
> To reproduce it, I just create a 1GB file in the filesystem using "dd":
>
> if=/dev/zero of=temp bs=1k count=1024k
>
> I created a swap file to solve the issue but it continues. After
> dropping the page cache with:
>
> echo 3 > /proc/sys/
>
> the issue is solved temporarily.
>
>
> ** Attachment added: "Selection_320.png"
> https:/
>
> --
> You received this bug notification because you are subscribed to the bug
> report.
> https:/
>
> Title:
> kswapd0 100% CPU usage
>
> Status in Linux:
> Unknown
> Status in linux package in Ubuntu:
> Confirmed
>
> Bug description:
> As per bug 721896 and various others:
>
> I'm on an AWS t2.micro instance (Xeon E5-2670, 991MiB of memory).
> Occasionally (about once a day), kswapd0 falls into a busy loop and
> spins on 100% CPU usage indefinitely. This can be provoked by
> copying/writing large files (e.g. dding a 256MB file), but it happens
> occasionally otherwise. System memory usage (not including
> buffers/caches) currently sits at 36%, which is typical[1]. Initially
> I had no swap space configured; I've since tried enabling a 256MB swap
> file, but the problem continues to occur and no swap space is used.
> The system can be recovered with `echo 1 > /proc/sys/
>
> Happy to provide further information/take further debugging actions.
>
>
> [1] Full output from `free`:
> total used free shared buffers cached
> Mem: 1014936 483448 531488 28556 9756 112700
> -/+ buffers/cache: 360992 653944
> Swap: 262140 0 262140
>
> ProblemType: Bug
> DistroRelease: Ubuntu 15.10
> Package: linux-image-
> ProcVersionSign
> Uname: Linux 4.2.0-18-generic x86_64
> AlsaDevices:
> total 0
> crw-rw---- 1 root audio 116, 1 Nov 19 19:40 seq
> crw-rw---- 1 root audio 116, 33 Nov 19 19:40 timer
> AplayDevices: Error: [Errno 2] No such file or directory: 'aplay'
> ApportVersion: 2.19.1-0ubuntu5
> Architecture: amd64
> ArecordDevices: Error: [Errno 2] No such file or directory: 'arecord'
> AudioDevicesInUse: Error: command ['fuser', '-v', '/dev/snd/seq', '/dev/snd/timer'] failed with exit code 1:
> CRDA: N/A
> Date: Fri Nov 20 20:44:30 2015
> Ec2AMI: ami-1c552a76...
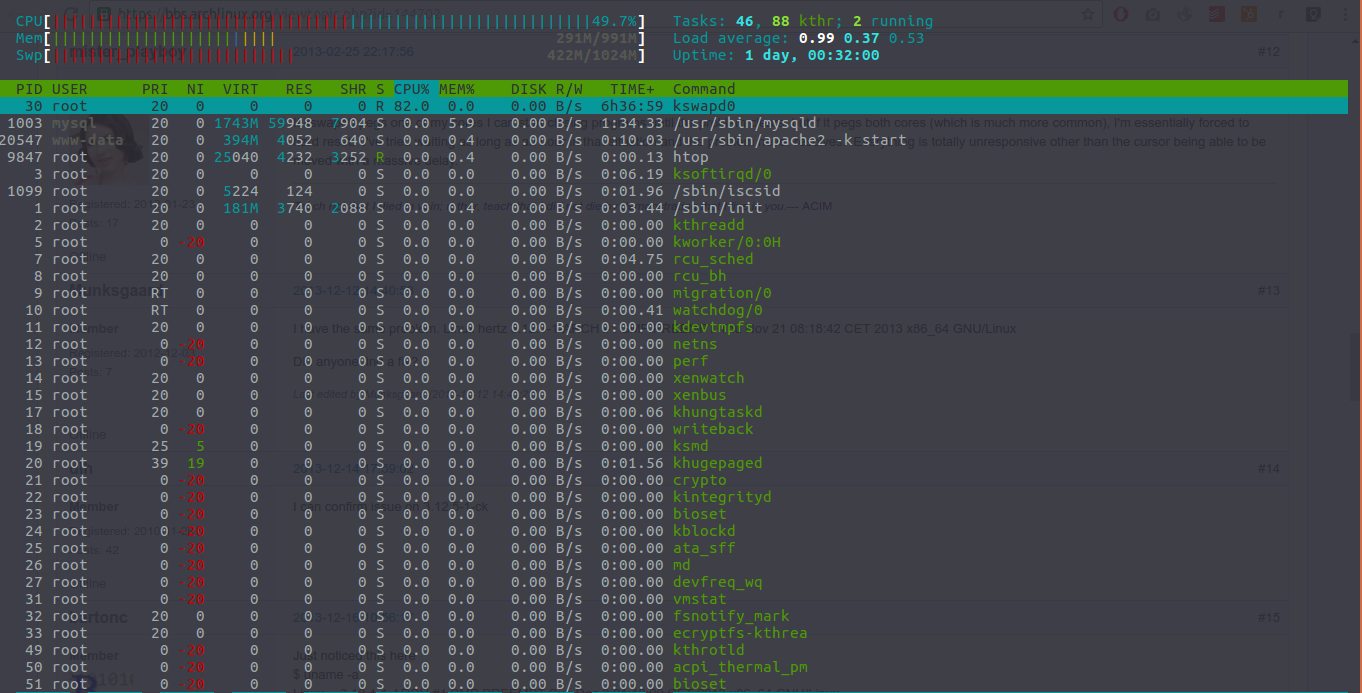{kind=link}
| MintPaw (jerusanders) wrote : | #103 |
I've fixed this in Arch Linux by moving to the 4.6.1-2-ARCH kernel, when previously on the 4.5.? kernel. This problem also doesn't occur in either the 4.0.7-2 or the 3.16-2 kernels for me at least.
I hear this is happening mostly on the 4.4.0-* kernel, which doesn't seem to be an option in the Arch Linux archive(https:/
| MintPaw (jerusanders) wrote : | #104 |
Whoops, it does seem to happen on 4.6.1-2, although the condition are different. It seems, does anyone have a sure fire repro case?
| Thorsten von Eicken (tve-rightscale) wrote : | #105 |
Is the ability to repro a hold-up on this issue? I can spend time to provide STRs on an EC2 instance using the latest official 16.04 image, but I don't want to go through the effort if repro isn't really a hold-up.
| tomtom (tbjornli) wrote : | #106 |
I can confirm that this issue also exist on AWS c4.large (vCPU 2, mem 3,75 GiB).
$ uname -a
Linux server 4.4.0-22-generic #39-Ubuntu SMP Thu May 5 16:53:32 UTC 2016 x86_64 x86_64 x86_64 GNU/Linux
$ free -m
total used free shared buff/cache available
Mem: 3762 1307 1204 69 1251 2321
Swap: 2047 39 2008
| Andrew Noruk (p-andrew-s) wrote : | #107 |
I'm also facing the kswap0 99% CPU issue. Typically, I notice it start minutes after boot time, but restarting the MongoDB process on the server will temporarily fix it, however the process will usually pop up again randomly.
I used to run test instances of MongoDB on AWS t2.micros with no issues but recently am being plagued by the kswap0 issue after I tried to upgrade the base AMI to Ubuntu 16.04.
uname -a
Linux hostname 4.4.0-22-generic #40-Ubuntu SMP Thu May 12 22:03:46 UTC 2016 x86_64 x86_64 x86_64 GNU/Linux
| Rasmus Larsen (rla-2) wrote : | #108 |
I had this issue too on AWS.
In my case, it was the udev rule for vm-hotadd and the fix as mentioned previously basically came down to "touch /etc/udev/
The udev rule basically seems to only be active for Xen or Hyper-V and while it seems the Hyper-V stuff was also present in previous versions, the Xen stuff seems to be introduced in 15.10 or newer.
So if you're seeing this issue on anything running on Xen, including AWS, try:
touch /etc/udev/
reboot
This is probably a bug in Xen or a bug in the kernel.
| Gregg King (greggking) wrote : | #109 |
Thank you so much Rasmus!
Your solution worked for me:
sudo touch /etc/udev/
reboot
I could always trigger the CPU usage bug with this:
stress --cpu 8 --io 4 --vm 7 --vm-bytes 128M --vm-hang 3 --timeout 60s
If running it once didn't work, a second run would do it. Now I've run it
over and over and kswap hits 1-2% during the stress test and drops back
down as soon as it ends.
Like Rasmus says, it's an AWS instance which runs on Xen.
On 17 June 2016 at 07:37, Rasmus Larsen <email address hidden> wrote:
> I had this issue too on AWS.
>
> In my case, it was the udev rule for vm-hotadd and the fix as mentioned
> previously basically came down to "touch /etc/udev/
> hotadd.rules" which effectively disables the /lib/udev/
> hotadd.rules file (after a reboot).
>
> The udev rule basically seems to only be active for Xen or Hyper-V and
> while it seems the Hyper-V stuff was also present in previous versions,
> the Xen stuff seems to be introduced in 15.10 or newer.
>
> So if you're seeing this issue on anything running on Xen, including
> AWS, try:
>
> touch /etc/udev/
> reboot
>
> This is probably a bug in Xen or a bug in the kernel.
>
> --
> You received this bug notification because you are subscribed to the bug
> report.
> https:/
>
> Title:
> kswapd0 100% CPU usage
>
> Status in Linux:
> Unknown
> Status in linux package in Ubuntu:
> Confirmed
>
> Bug description:
> As per bug 721896 and various others:
>
> I'm on an AWS t2.micro instance (Xeon E5-2670, 991MiB of memory).
> Occasionally (about once a day), kswapd0 falls into a busy loop and
> spins on 100% CPU usage indefinitely. This can be provoked by
> copying/writing large files (e.g. dding a 256MB file), but it happens
> occasionally otherwise. System memory usage (not including
> buffers/caches) currently sits at 36%, which is typical[1]. Initially
> I had no swap space configured; I've since tried enabling a 256MB swap
> file, but the problem continues to occur and no swap space is used.
> The system can be recovered with `echo 1 > /proc/sys/
>
> Happy to provide further information/take further debugging actions.
>
>
> [1] Full output from `free`:
> total used free shared buffers cached
> Mem: 1014936 483448 531488 28556 9756 112700
> -/+ buffers/cache: 360992 653944
> Swap: 262140 0 262140
>
> ProblemType: Bug
> DistroRelease: Ubuntu 15.10
> Package: linux-image-
> ProcVersionSign
> Uname: Linux 4.2.0-18-generic x86_64
> AlsaDevices:
> total 0
> crw-rw---- 1 root audio 116, 1 Nov 19 19:40 seq
> crw-rw---- 1 root audio 116, 33 Nov 19 19:40 timer
> AplayDevices: Error: [Errno 2] No such file or directory: 'aplay'
> ApportVersion: 2.19.1-0ubuntu5
> Architecture: amd64
> ArecordDevices: Error: [Errno 2] No such file or directory: 'arecord'
> AudioDevicesInUse: Error: command ['fuser', '-v', '/dev/snd/seq',
> '/dev/snd/timer'] failed with ex...
| quinn (q-shanahan) wrote : | #110 |
Is there a fix for this that doesn't require a reboot / something I could add to an ec2 instance's user_data?
| Argat (argat) wrote : | #111 |
The suggested workaround works for me also on AWS instances with 15.10:
sudo touch /etc/udev/
reboot
Been stable now for over a week.
| Joern Heissler (joernheissler) wrote : | #112 |
Can this workaround please be added to the official EC2 images? EC2 cannot hot swap CPU or memory from what I know.
Having this workaround built in would mean not having to reboot every newly launched instance.
|
|
#189 |
Same thing on Thinkpad X220 with 8 GB RAM running Ubuntu 14.04, with Ubuntu's Kernel 3.16.0-77-generic.
Swap is disabled.
kswapd0 runs on high CPU and the HD light is on all the time during this (no idea why).
After 20 (!) minutes the OOM killer manages to kill a process to resolve the situation.
| Christopher Snowhill (kode54) wrote : | #113 |
Is this known to affect paravirtualized instances, or is it restricted to hvm? Can anyone tell me what conditions I need to create this in a fresh instance? I'll spin up a PV t2.nano and see if I can reproduce it there.
| Øystein Gisnås (oystein-gisnas) wrote : | #114 |
I've tried this on t1.micro (PV) and t2.micro (HVM) instances in eu-west-1. To reproduce, I used the following two commands:
sudo apt install docker.io
sudo docker run -p 80:8080 cptactionhank/
The startup should work, but navigate to http://
Test results:
ubuntu/
ubuntu/
It's worth noting that the memory blocks varies between distro and PV/HVM:
Amazon Linux HVM: /sys/devices/
RHEL 7.2 HVM: /sys/devices/
Ubuntu 16.04 HVM: /sys/devices/
Ubuntu 16.04 PV: /sys/devices/
Why Ubuntu on HVM has an extra memory block is a mystery. It seems to be offline by default, but enabled by the udev hotadd rule. And EC2 doesn't support hotadd.
As Joern Heissler suggested, why not remove the hotadd rule from the official images as a workaround? Although the underlying problem probably is related to why the additional memory block is there at all.
| Felix Bünemann (felix-buenemann) wrote : | #115 |
I have run into this issue when using the goofys s3 fuse filesystem (https:/
| Robin Miller (robincello) wrote : | #116 |
We have been seeing this issue intermittently on a set of servers that were running Ubuntu 15.10 and then 16.04. After overriding that udev vm hotadd rule as suggested above a couple weeks ago, the issue has yet to return (not a conclusive result, but so far so good).
| Robin Miller (robincello) wrote : | #117 |
To add - these servers are all built on the official Ubuntu Amazon EC2 AMIs of the 'ebs-ssd' variety.
| Andrew Tappert (andrewtappert) wrote : | #118 |
The original description says "kswapd0 falls into a busy loop and spins on 100% CPU usage indefinitely". But I think, while the effect may be similar, the actual behavior is a bit different. I think what is happening is that kswapd is accessing pages of memory that are causing the hypervisor (rather than the kernel) to do extra work. If you look at the overall CPU utilization of the instance, you'll see high "st" (steal) time. This can also be provoked manually, for example by trying to read via /proc/kcore from the extra memory region that has been identified in discussion above (for example, try to do a full memory dump with the Volatility getkcore tool).
| José Martínez (xosemp) wrote : | #119 |
- fillmem.sh Edit (440 bytes, text/x-sh)
I wrote a tiny batch script to reliably reproduce the bug. It mounts a tmpfs filesystem and writes a file that fills 98% of the currently available memory.
You can also pass it a custom percentage, like: ./fillmem.sh 95
<95% is hit and miss on a newly launched instance. 98% (the default) has inmediately spun kswapd to 100% on all of my tests.
----------
@andrewtappert: steal time means the T2 instance has run out of CPU credits. They launch with just enough credits to burst the CPU to 100% for 30 minutes.
I'm always getting SYS time on kswapd, until I hit the T2 credits limit.
|
|
#190 |
Same problem on Amazon's t2.nano instance (512MB of RAM). Seemed to be triggered by doing a bunch of file IO. This is a brand new install of Ubuntu 16.04. I have no swap enabled, and yet:
top - 06:42:57 up 1:58, 1 user, load average: 2.43, 2.66, 2.31
Tasks: 125 total, 3 running, 122 sleeping, 0 stopped, 0 zombie
%Cpu(s): 2.1 us, 6.9 sy, 0.0 ni, 0.0 id, 0.9 wa, 0.0 hi, 0.0 si, 90.1 st
KiB Mem : 498416 total, 348096 free, 49772 used, 100548 buff/cache
KiB Swap: 0 total, 0 free, 0 used. 411900 avail Mem
PID USER PR NI VIRT RES SHR S %CPU %MEM TIME+ COMMAND
29 root 20 0 0 0 0 R 65.0 0.0 103:16.64 kswapd0
14343 root 20 0 0 0 0 R 2.9 0.0 0:00.82 python
Running "echo 1 > /proc/sys/
Also, my /tmp isn't full at all (6.5GB / 85% left on root).
|
|
#191 |
A workaround for machines running under Xen has been found over on Ubuntu's bug tracker, see comment #69:
https:/
The workaround is to disable hot-add of memory:
touch /etc/udev/
reboot
|
|
#192 |
I tried the same Ubuntu inspired "disable hot-add of memory" (and CPU) workaround under AWS EC2 HVM, Centos 7.x with mainline (elrepo) 4.4.15 kernel: no such luck, I still see this occasionally.
| Andy Robertson (andyrobertson101) wrote : | #120 |
All of my t2.micro & nano instances are affected by this in AWS EC2 after upgrading to Ubuntu16.
doing "echo 1 > /proc/sys/
I moved a couple instances over to f1.micro on GCP / GCE (1 vCPU, 0.6 GB memory) and the problem seems to have gone away. I can't do this with all of my instances yet though so a fix in AWS would be nice.
| Paul Csiki (paulcsiki) wrote : | #121 |
https:/
Seems to have resolved all this issues on AWS t2.micro instances.
| Gregg King (greggking) wrote : | #122 |
Did you try this from Rasmussen up above?
sudo touch /etc/udev/
reboot
That fixed it for me on EC2
On Saturday, 3 September 2016, Andy Robertson <email address hidden>
wrote:
> All of my t2.micro & nano instances are affected by this in AWS EC2
> after upgrading to Ubuntu16.
>
> doing "echo 1 > /proc/sys/
> a short period of time, but it comes back within a few minutes.
>
> I moved a couple instances over to f1.micro on GCP / GCE (1 vCPU, 0.6 GB
> memory) and the problem seems to have gone away. I can't do this with
> all of my instances yet though so a fix in AWS would be nice.
>
> --
> You received this bug notification because you are subscribed to the bug
> report.
> https:/
>
> Title:
> kswapd0 100% CPU usage
>
> Status in Linux:
> Unknown
> Status in linux package in Ubuntu:
> Confirmed
>
> Bug description:
> As per bug 721896 and various others:
>
> I'm on an AWS t2.micro instance (Xeon E5-2670, 991MiB of memory).
> Occasionally (about once a day), kswapd0 falls into a busy loop and
> spins on 100% CPU usage indefinitely. This can be provoked by
> copying/writing large files (e.g. dding a 256MB file), but it happens
> occasionally otherwise. System memory usage (not including
> buffers/caches) currently sits at 36%, which is typical[1]. Initially
> I had no swap space configured; I've since tried enabling a 256MB swap
> file, but the problem continues to occur and no swap space is used.
> The system can be recovered with `echo 1 > /proc/sys/
>
> Happy to provide further information/take further debugging actions.
>
>
> [1] Full output from `free`:
> total used free shared buffers cached
> Mem: 1014936 483448 531488 28556 9756 112700
> -/+ buffers/cache: 360992 653944
> Swap: 262140 0 262140
>
> ProblemType: Bug
> DistroRelease: Ubuntu 15.10
> Package: linux-image-
> ProcVersionSign
> Uname: Linux 4.2.0-18-generic x86_64
> AlsaDevices:
> total 0
> crw-rw---- 1 root audio 116, 1 Nov 19 19:40 seq
> crw-rw---- 1 root audio 116, 33 Nov 19 19:40 timer
> AplayDevices: Error: [Errno 2] No such file or directory: 'aplay'
> ApportVersion: 2.19.1-0ubuntu5
> Architecture: amd64
> ArecordDevices: Error: [Errno 2] No such file or directory: 'arecord'
> AudioDevicesInUse: Error: command ['fuser', '-v', '/dev/snd/seq',
> '/dev/snd/timer'] failed with exit code 1:
> CRDA: N/A
> Date: Fri Nov 20 20:44:30 2015
> Ec2AMI: ami-1c552a76
> Ec2AMIManifest: (unknown)
> Ec2Availability
> Ec2InstanceType: t2.micro
> Ec2Kernel: unavailable
> Ec2Ramdisk: unavailable
> IwConfig: Error: [Errno 2] No such file or directory: 'iwconfig'
> Lsusb: Error: command ['lsusb'] failed with exit code 1: unable to
> initialize libusb: -99
> MachineType: Xen HVM domU
> PciMultimedia:
>
> ProcEnviron:
> TERM=screen
> PATH=(custom, no user)
> LANG=en_US.UTF-8
> SHELL=/bin/bash
...
| Paul Buonopane (zenexer) wrote : | #123 |
From man 7 udev:
The udev rules are read from the files located in the system rules directory /lib/udev/rules.d, the volatile runtime directory /run/udev/rules.d and the local administration directory /etc/udev/rules.d. All rules files are collectively sorted and processed in lexical order, regardless of the directories in which they live. However, files with identical filenames replace each other. Files in /etc have the highest priority, files in /run take precedence over files with the same name in /lib. This can be used to override a system-supplied rules file with a local file if needed; a symlink in /etc with the same name as a rules file in /lib, pointing to /dev/null, disables the rules file entirely. Rule files must have the extension .rules; other extensions are ignored.
As such, the best way to work around this is:
sudo ln -s /dev/null /etc/udev/
Unlike deleting or modifying the original file, this will persist across upgrades without requiring manual conflict resolution.
| Richard Trout (richard-trout) wrote : | #124 |
Thanks #123 (as easy as?) works for me as a workaround.
| Poldi (poldi) wrote : | #125 |
I have the same issue on 16.04
| Dan Streetman (ddstreet) wrote : | #126 |
The problem is a bit complex. The Xen hypervisor uses memory ballooning, to control how many memory pages the guest can use. The kernel enumerates its e820 memory at boot, and since it's only 1G in this case, it all gets placed into the DMA32 zone. Then later during boot when the Xen balloon driver is initialized, it dynamically adds the balloon memory. The kernel always places hot-added memory into the Normal zone however, so the system winds up with the balloon memory, and only the balloon memory, in the Normal zone. Since the balloon driver starts at, or very close to, its memory target, only a very small number of pages are made available, which results in a Normal memory zone that's tiny - only 9 managed pages on the instance I tested. You can read the /proc/zoneinfo file to find the number of managed pages in the Normal zone.
Then when the system encounters memory pressure (i.e. very little free memory left), it wakes up the kswapd daemon to start freeing memory. The kswapd daemon then tries to "balance" memory by "balancing" each zone - DMA, DMA32, and Normal zones. However, it's essentially impossible for it to free pages from the Normal zone, because there are so few pages that whenever one is freed, the next page allocation takes it (because pages are usually allocated from the Normal zone first), and kswapd winds up in a continuous cycle of trying to free pages from the Normal zone forever.
This is also why disabling the udev memory hotadd (see comment 69) works around the problem - it prevents the Xen balloon driver from adding/enabling any of the pages in the Normal zone, so kswapd never has to bother trying to balance it, and thus there's no problem.
This appears to be fixed by Mel Gorman's 34-commit patch series that changes kswapd memory balancing to "per node" instead of "per zone":
https:/
That's a rather large patchset to backport to the xenial kernel, but I'll give it a try.
| Changed in linux (Ubuntu): | |
| assignee: | nobody → Dan Streetman (ddstreet) |
| Dan Streetman (ddstreet) wrote : | #127 |
The patch series that fixes this is included in yakkety (if anyone reproduces this on a yakkety kernel, please let me know), so this only needs fixing in xenial.
|
|
#193 |
I detailed why this bug happens here:
https:/
this appears to be fixed by Mel Gorman's patch series to change memory reclaim from "per zone" to "per node":
https:/
So this bug should be fixed with the latest kernel.
| Dan Streetman (ddstreet) wrote : | #128 |
On review of the patch series, it's simply too large and complex to backport for this situation; it makes, and depends on, a rather large amount of change to the mm subsystem, and there are easier and smaller ways to work around this bug in the xenial kernel.
Specifically, a comparison of the Xen balloon driver vs. the virtio balloon driver shows an important difference; while the Xen balloon driver hot-adds memory as soon as it initializes, the virtio driver does not hot-add memory; it only adjusts its size to adjust the amount of free memory. Most importantly, the Xen balloon driver initially hot-adds memory but does not make any (except a very small amount) available for system use.
I'm looking at the Xen balloon driver to see how it can be changed to fix this bug.
|
|
#194 |
(In reply to Dan Streetman from comment #40)
> I detailed why this bug happens here:
> https:/
>
> So this bug should be fixed with the latest kernel.
Can you clarify, the link you mention seems to talk mainly about Xen. Do you think the latest kernel will fix it also for non-Xen machines?
|
|
#195 |
(In reply to mail+kernel-
> (In reply to Dan Streetman from comment #40)
> > I detailed why this bug happens here:
> > https:/
> >
> > So this bug should be fixed with the latest kernel.
>
> Can you clarify, the link you mention seems to talk mainly about Xen. Do you
> think the latest kernel will fix it also for non-Xen machines?
what does your /proc/zoneinfo look like? do you have a system with (approx) <= 4g and Normal zone with few managed pages?
|
|
#196 |
(In reply to Dan Streetman from comment #42)
> what does your /proc/zoneinfo look like? do you have a system with (approx)
> <= 4g and Normal zone with few managed pages?
My zoneinfo file right now looks like this: https:/
(I upgraded from 8 GB to 16 GB memory recently though, after I wrote comment #36.)
|
|
#197 |
(In reply to mail+kernel-
> (In reply to Dan Streetman from comment #42)
> > what does your /proc/zoneinfo look like? do you have a system with
> (approx)
> > <= 4g and Normal zone with few managed pages?
>
> My zoneinfo file right now looks like this:
> https:/
>
> (I upgraded from 8 GB to 16 GB memory recently though, after I wrote comment
> #36.)
That zoneinfo doesn't look like you're seeing the same problem, so if you are seeing consistent, sustained (not just transient) 100% cpu from kswapd, I think it's a different problem from what I described in comment 40.
| Changed in linux (Ubuntu Xenial): | |
| status: | New → Fix Committed |
| importance: | Undecided → High |
| assignee: | nobody → Dan Streetman (ddstreet) |
| Changed in linux (Ubuntu Yakkety): | |
| status: | Confirmed → Fix Committed |
| Changed in linux (Ubuntu Yakkety): | |
| status: | Fix Committed → Invalid |
| Launchpad Janitor (janitor) wrote : | #129 |
This bug was fixed in the package linux - 4.4.0-43.63
---------------
linux (4.4.0-43.63) xenial; urgency=low
[ Seth Forshee ]
* Release Tracking Bug
- LP: #1632375
* kswapd0 100% CPU usage (LP: #1518457)
- SAUCE: (no-up) If zone is so small that watermarks are the same, stop zone
balance.
-- Seth Forshee <email address hidden> Tue, 11 Oct 2016 07:54:56 -0500
| Changed in linux (Ubuntu Xenial): | |
| status: | Fix Committed → Fix Released |
|
|
#198 |
I'm assuming by latest kernel you mean 4.8? If so I'm looking forward to Arch pushing it through testing :)
| Seth Forshee (sforshee) wrote : | #130 |
This bug is awaiting verification that the kernel in -proposed solves the problem. Please test the kernel and update this bug with the results. If the problem is solved, change the tag 'verification-
If verification is not done by 5 working days from today, this fix will be dropped from the source code, and this bug will be closed.
See https:/
| tags: | added: verification-needed-yakkety |
| CaptSaltyJack (csjubuntu) wrote : | #131 |
Will we see this fix make it to 16.04 LTS?
| Felix Bünemann (felix-buenemann) wrote : | #132 |
The fix is already released in 16.04, make sure you have updated to linux-image 4.4.0-43.63 or later.
| PierreF (pierre-fersing) wrote : | #133 |
If the verification apply also on 16.04, it does fix the issue.
We had a server that triggered the bug at least once a day (I suspect unattended-upgrade run every morning to trigger it). Since the upgrade - 2 days and half ago - the server had no issue.
| Øystein Gisnås (oystein-gisnas) wrote : | #134 |
I have verified that the bug is fixed on 4.8.0-26.28 (yakkety), 4.4.0-43.63 (xenial) and 4.4.0-45.66 (xenial). Doing the same on 4.4.0-42.62 (xenial) reproduced the bug. All tests done on EC2 t2.small.
| tags: |
added: verification-done-yakkety removed: verification-needed-yakkety |
| Raniz (raniz-1) wrote : | #135 |
After upgrading to 4.4.0-45 from 4.4.0-21 the issue seems to have gone away.
| Launchpad Janitor (janitor) wrote : | #136 |
This bug was fixed in the package linux - 4.8.0-27.29
---------------
linux (4.8.0-27.29) yakkety; urgency=low
[ Seth Forshee ]
* Release Tracking Bug
- LP: #1635377
* proc_keys_show crash when reading /proc/keys (LP: #1634496)
- SAUCE: KEYS: ensure xbuf is large enough to fix buffer overflow in
proc_
* Revert "If zone is so small that watermarks are the same, stop zone balance"
in yakkety (LP: #1632894)
- Revert "UBUNTU: SAUCE: (no-up) If zone is so small that watermarks are the
same, stop zone balance."
* lts-yakkety 4.8 cannot mount lvm raid1 (LP: #1631298)
- SAUCE: (no-up) dm raid: fix compat_features validation
* kswapd0 100% CPU usage (LP: #1518457)
- SAUCE: (no-up) If zone is so small that watermarks are the same, stop zone
balance.
* [Trusty->Yakkety] powerpc/64: Fix incorrect return value from
__copy_
- SAUCE: (no-up) powerpc/64: Fix incorrect return value from
_
* Ubuntu 16.10: Oops panic in move_page_
memory_
- SAUCE: (no-up) powerpc/pseries: Fix stack corruption in htpe code
* Paths not failed properly when unmapping virtual FC ports in VIOS (using
ibmvfc) (LP: #1632116)
- scsi: ibmvfc: Fix I/O hang when port is not mapped
* [Ubuntu16.10]KV4.8: kernel livepatch config options are not set
(LP: #1626983)
- [Config] Enable live patching on powerpc/ppc64el
* CONFIG_AUFS_XATTR is not set (LP: #1557776)
- [Config] CONFIG_AUFS_XATTR=y
* Yakkety update to 4.8.1 stable release (LP: #1632445)
- arm64: debug: avoid resetting stepping state machine when TIF_SINGLESTEP
- Using BUG_ON() as an assert() is _never_ acceptable
- usb: misc: legousbtower: Fix NULL pointer deference
- Staging: fbtft: Fix bug in fbtft-core
- usb: usbip: vudc: fix left shift overflow
- USB: serial: cp210x: Add ID for a Juniper console
- Revert "usbtmc: convert to devm_kzalloc"
- ALSA: hda - Adding one more ALC255 pin definition for headset problem
- ALSA: hda - Fix headset mic detection problem for several Dell laptops
- ALSA: hda - Add the top speaker pin config for HP Spectre x360
- Linux 4.8.1
* PSL data cache should be flushed before resetting CAPI adapter
(LP: #1632049)
- cxl: Flush PSL cache before resetting the adapter
* thunder nic: avoid link delays due to RX_PACKET_DIS (LP: #1630038)
- net: thunderx: Don't set RX_PACKET_DIS while initializing
* crypto/vmx/p8_ghash memory corruption (LP: #1630970)
- crypto: ghash-generic - move common definitions to a new header file
- crypto: vmx - Fix memory corruption caused by p8_ghash
- crypto: vmx - Ensure ghash-generic is enabled
* arm64: SPCR console not autodetected (LP: #1630311)
- of/serial: move earlycon early_param handling to serial
- [Config] CONFIG_
- ACPI: parse SPCR and enable matching console
- ARM64: ACPI: enable ACPI_SPCR_TABLE
- serial: pl011: add console matching function
* include/
...
| Changed in linux (Ubuntu Yakkety): | |
| status: | Invalid → Fix Released |
| status: | Invalid → Fix Released |
| Luc Pi (oluc) wrote : | #138 |
> Dan Streetman (ddstreet) wrote on 2016-10-01: #127
>
> The patch series that fixes this is included in yakkety
> (if anyone reproduces this on a yakkety kernel, please let me know),
I can see it every now and then with Yakkety and linux 4.8.0-27.
Can you advice any action?
$ uname -a
Linux luc-MacBook 4.8.0-27-generic #29-Ubuntu SMP Thu Oct 20 21:01:44 UTC 2016 i686 i686 i686 GNU/Linux
$ lsb_release -a
Description: Ubuntu 16.10
Codename: yakkety
|
|
#199 |
I am having the same issue on Fedora 24 with kernel 4.8.6. So I guess it has not been pushed there, or it does not fix anything.
It is a huge job stopper as I need to transfer many files between two USB disks.
Kwapd0 appears on top of processes after a while, and slowly degrades overall performance until I have to hard reboot the machine in the middle of some transfer.
|
|
#200 |
My guess is Fedora didn't put the changes through or something, because 4.8 has DEFINITELY fixed it for me. I used to have to reboot about twice daily due to this, but ever since I upgraded to 4.8 it hasn't happened once.
|
|
#201 |
I'm on openSUSE with 4.8.8 and still have this issue.
| velis (jure-erznoznik-gmail) wrote : | #139 |
Following this thread I had the same issue, running stock 16.04 (xenial) with kernel 4.4.0-38.
I have upgraded the kernel to 4.8.10-040810 and the end result is the same but symptoms are a bit different:
note: 1GB of RAM, no swap at all
(old kernel)
with 50% of RAM in buffers / cache, kswapd0 took all the CPU it could (~75%). iostat was pretty much at 0% utilisation. server ground to a halt immediately when free ram expired without ever "eating into" the buffers / cache.
(new kernel)
again, with 50% of RAM in buffers / cache, kswapd0 no longer takes 100% CPU, but it still emerges to the top of the list in top as it still manages to take more then the other processes. For a difference, now ~75% cpu processes are *WA*iting. A second difference is that now, after free ram is consumed, for a while buffers / cache are also being reduced in favour of the RAM hungry app. However, even this goes only down to about 40 - 43% or RAM being used by buffers / cache.
Hopefully this is making at least some sense.
| Launchpad Janitor (janitor) wrote : | #140 |
This bug was fixed in the package linux - 4.8.0-30.32
---------------
linux (4.8.0-30.32) yakkety; urgency=low
* CVE-2016-8655 (LP: #1646318)
- packet: fix race condition in packet_set_ring
-- Brad Figg <email address hidden> Thu, 01 Dec 2016 08:02:53 -0800
| Changed in linux (Ubuntu): | |
| status: | Invalid → Fix Released |
|
|
#202 |
I'm on Debian with 4.8.7 and still have this issue.
| Dan Streetman (ddstreet) wrote : | #141 |
> I can see it every now and then with Yakkety and linux 4.8.0-27.
> Can you advice any action?
what do you mean by "every now and then"? you mean kswapd runs at 100% for a short time, occasionally? that's normal.
> kswapd0 no longer takes 100% CPU, but it still emerges to the top of the list in top as it still
> manages to take more then the other processes
this sounds like kswapd is just doing its job now. if you stop all your applications, does kswapd still take up cpu time indefinitely?
| Tuomo Sipola (tuomosipola) wrote : | #142 |
Running Ubuntu 16.10 Yakkety. Old 4.4.0-45-generic kernel works nicely. All the new 4.8.0 kernels eventually go berzerk with kswapd0, just today the newest 4.8.0-32-generic. Normal usage, just a couple of terminals, Chromium, Nautilus windows and Evince PDF documents open.
| Wilhelm Buchmueller (wilhelm-buchmueller) wrote : | #143 |
Running 4.8.13-
kswapd0 usage high while reading from /dev/sda (not mounted, internal SSD with 500+MB/s read).
After stop reading, kswapd0 usage is gone.
No Problem when reading from USB-HDD.
Problem with high-speed reading?
| Dan Streetman (ddstreet) wrote : | #144 |
This bug is fixed released already, any new problems should be opened in a new bug.
|
|
#203 |
4.8.13-
/dev/sda is Samsung SSD 850 EVO 250GB
swapoff -va
sysctl vm.drop_caches=3
Problem, causes always heavy kswapd0 load:
cat /dev/sda >> /dev/zero
hdparm -t /dev/sda
ddrescue /dev/sda /dev/zero -vf
hexdump /dev/sda
dd if=/dev/sda of=/dev/zero
etc.
No problem (read speed ~500MB/s, except hdparm ):
hdparm --direct -t /dev/sda
dd iflag=direct if=/dev/sda of=/dev/zero bs=1073741824
ddrescue --direct /dev/sda /dev/zero -vf -b 4096 -c 8192
|
|
#204 |
I am not sure if this is the same bug, but for me kswapd0 goes high-cpu following a page allocation failure in xhci_segment_alloc and I think that this has been occurring since moving to 4.8 on Fedora 24. I don't remember experiencing it before that. Currently on 4.8.15.
I normally boot with 3 or 4 USB 3.0 disks attached and, after the upgrade to 4.8.x noticed that kswapd0 was running at 100%. I went back to 4.7.x and no problem. Searches on this issue frequently referred to USB disks so I unplugged and rebooted.
If I unplug all of my USB 3.0 devices I get a normal boot, even with a USB weather station, keyboard, mouse. Sometimes, one or two USB 3.0 disks is OK too, If I boot with all of the USB 3.0 disks included, I get a kworker page allocation failure and after boot kswapd0 is high-cpu, usually split across 2-4 cores.
If I boot with two USB 3.0 disks and get a normal boot (no page allocation failure and normal kswapd) and then plug in a hub with the rest of the disks (and a USB 3.0 card reader) I get the page allocation failure at that point and kswapd0 goes high-cpu.
I have not looked at them all, but whenever I see kswapd0 high-cpu and I do look, there is the page allocation failure in the log.
The 'perf top' command seems to show different information from time to time but the top contenders are frequently 'shrink_
Makes me wonder if the xhci allocation failure is the trigger, and fails to clean up on the error exit path, and kswapd0 is just a hapless victim. There is a stack trace (on ubuntu kernel) of the page allocation failure in the dmesg attached to https:/
I have 19GiB free on a 24GiB machine so there should be no memory shortage to prompt swapping or the page allocation failure.
I had also noticed frequently that not all of my USB disks were mounted after boot and that I had to remove and reinsert a disk to use it. IIRC this affected my USB 2.0 disks too and from before the upgrade to 4.8 too.
|
|
#205 |
> Problem, causes always heavy kswapd0 load:
> cat /dev/sda >> /dev/zero
> hdparm -t /dev/sda
> ddrescue /dev/sda /dev/zero -vf
> hexdump /dev/sda
> dd if=/dev/sda of=/dev/zero
> etc.
of course those cause kswapd work, all those commands will fill your page cache and kswapd is responsible for clearing those pages out.
kswapd running isn't a problem, if it's doing work. kswapd running *without* doing work is the problem. When you stop running those commands, does kswapd catch up and stop using cpu? If so, that's normal. If not, and it never stops using cpu, that's the problem.
> No problem (read speed ~500MB/s, except hdparm ):
> hdparm --direct -t /dev/sda
> dd iflag=direct if=/dev/sda of=/dev/zero bs=1073741824
> ddrescue --direct /dev/sda /dev/zero -vf -b 4096 -c 8192
the difference is those commands bypass the page cache - so the page cache doesn't fill up and kswapd doesn't need to clear it out.
|
|
#206 |
> I am not sure if this is the same bug, but for me kswapd0 goes high-cpu
> following a page allocation failure in xhci_segment_alloc and I think that
> this has been occurring since moving to 4.8 on Fedora 24
from your dmesg, it certainly doesn't look like the same bug.
| Mathieu Perona (mathieu-perona-gmail) wrote : | #145 |
As of 2017-01-26, I experience this bug on two 16.10 boxes. This kswap0d behavior is 100% reproductible when I copy large files (more than c. 500 Mo) from or to a NTFS hard drive.
| Mathieu Perona (mathieu-perona-gmail) wrote : | #146 |
As a complement to my previous comment: both computers have a significant amount of RAM (4 and 8 Go respectively) and the swap partition is shown as not used by the system monitor.
| Dan Streetman (ddstreet) wrote : | #147 |
As a comment to those expecting that disabling swap will prevent kswapd from doing anything, that's incorrect. kswapd also is responsible for clearing out the page cache, so even with swap disabled you'll still see it doing work, especially during heavy IO that uses the page cache. For example, copying large files from fast drives. That's completely normal. What this bug is about, is kswapd trying over and over to do its normal work, but making no progress, so it continues to use 100% cpu while the rest of the system is doing nothing. That bug should be fixed now.
If anyone continues to see *this* bug - kswapd using 100% cpu while your system is doing nothing and kswapd never recovers - you can report it here, but you should also open a new bug and reference it in your comment (this bug is fixed and closed). However, if all you see is kswapd using cpu while you're doing things - especially file IO - that isn't this bug, and it probably isn't actually a bug at all.
| Simon West (d-simon-e) wrote : | #148 |
8 months on and one of my systems is exhibiting what would appear to be the same bug... it was running Ubuntu 17.04 happily and just got upgraded to 17.10 with today's updates. (Yeah... upgrade, not reinstall... not enough time to re-download all the Insync files!)
These were the first lines of `top` as the computer started going into slowdown:
PID USER PR NI VIRT RES SHR S %CPU %MEM TIME+ COMMAND
54 root 20 0 0 0 0 R 47.2 0.0 2:46.26 kswapd0
1678 tracey 20 0 3917924 139976 4 D 1.2 3.6 1:01.26 insync
kswapd0 went higher then it locked up.
I have a small swapfile, although the system is running on an SSD.
root@tracey-nnnn:~# swapon --show
NAME TYPE SIZE USED PRIO
/swapfile file 2G 498.5M -1
I have vm.swappiness=1 in /etc/sysctl.conf
This is memory when the system is running normally:
root@tracey-nnnn:~# free -h
total used free shared buff/cache available
Mem: 3.7G 2.2G 339M 998M 1.2G 392M
Swap: 2.0G 498M 1.5G
Suggestions please?
Frustrated of Lyme Regis
| Dan Streetman (ddstreet) wrote : | #149 |
this bug is fix released. please open a new bug.
note that you may just have been out of memory.
| Mathieu Perona (mathieu-perona-gmail) wrote : | #150 |
Dear Dan,
I am not sure you are mailing the right person. Anyway, the issue still
arises when copying large files from a FAT drive to an EXT one. kswapd uses
all available CPU power (but leaves much of the RAM unused) and copy
throughput declines.
Anyway, I solved the problem by transferring my external drive to an EXT4
filesystem, at the expense of interoperability.
Best
Le jeu. 26 oct. 2017 à 13:26, Dan Streetman <email address hidden> a
écrit :
> this bug is fix released. please open a new bug.
>
> note that you may just have been out of memory.
>
> --
> You received this bug notification because you are subscribed to the bug
> report.
> https:/
>
> Title:
> kswapd0 100% CPU usage
>
> Status in Linux:
> Unknown
> Status in linux package in Ubuntu:
> Fix Released
> Status in linux source package in Xenial:
> Fix Released
> Status in linux source package in Yakkety:
> Fix Released
>
> Bug description:
> As per bug 721896 and various others:
>
> I'm on an AWS t2.micro instance (Xeon E5-2670, 991MiB of memory).
> Occasionally (about once a day), kswapd0 falls into a busy loop and
> spins on 100% CPU usage indefinitely. This can be provoked by
> copying/writing large files (e.g. dding a 256MB file), but it happens
> occasionally otherwise. System memory usage (not including
> buffers/caches) currently sits at 36%, which is typical[1]. Initially
> I had no swap space configured; I've since tried enabling a 256MB swap
> file, but the problem continues to occur and no swap space is used.
> The system can be recovered with `echo 1 > /proc/sys/
>
> Happy to provide further information/take further debugging actions.
>
>
> [1] Full output from `free`:
> total used free shared buffers cached
> Mem: 1014936 483448 531488 28556 9756 112700
> -/+ buffers/cache: 360992 653944
> Swap: 262140 0 262140
>
> ProblemType: Bug
> DistroRelease: Ubuntu 15.10
> Package: linux-image-
> ProcVersionSign
> Uname: Linux 4.2.0-18-generic x86_64
> AlsaDevices:
> total 0
> crw-rw---- 1 root audio 116, 1 Nov 19 19:40 seq
> crw-rw---- 1 root audio 116, 33 Nov 19 19:40 timer
> AplayDevices: Error: [Errno 2] No such file or directory: 'aplay'
> ApportVersion: 2.19.1-0ubuntu5
> Architecture: amd64
> ArecordDevices: Error: [Errno 2] No such file or directory: 'arecord'
> AudioDevicesInUse: Error: command ['fuser', '-v', '/dev/snd/seq',
> '/dev/snd/timer'] failed with exit code 1:
> CRDA: N/A
> Date: Fri Nov 20 20:44:30 2015
> Ec2AMI: ami-1c552a76
> Ec2AMIManifest: (unknown)
> Ec2Availability
> Ec2InstanceType: t2.micro
> Ec2Kernel: unavailable
> Ec2Ramdisk: unavailable
> IwConfig: Error: [Errno 2] No such file or directory: 'iwconfig'
> Lsusb: Error: command ['lsusb'] failed with exit code 1: unable to
> initialize libusb: -99
> MachineType: Xen HVM domU
> PciMultimedia:
>
> ProcEnviron:
> TERM=screen
> PATH=(custom, no user)
> LANG=en_US....
| Dan Streetman (ddstreet) wrote : | #151 |
Mathieu,
I'm not mailing you, this is a public bug report, you subscribed yourself to this bug:
2017-01-26 10:14:29 Mathieu Perona bug added subscriber Mathieu Perona
| Mathieu Perona (mathieu-perona-gmail) wrote : | #152 |
Sorry !
Le jeu. 26 oct. 2017 à 14:55, Dan Streetman <email address hidden> a
écrit :
> Mathieu,
>
> I'm not mailing you, this is a public bug report, you subscribed
> yourself to this bug:
>
> 2017-01-26 10:14:29 Mathieu Perona bug added
> subscriber Mathieu Perona
>
> --
> You received this bug notification because you are subscribed to the bug
> report.
> https:/
>
> Title:
> kswapd0 100% CPU usage
>
> Status in Linux:
> Unknown
> Status in linux package in Ubuntu:
> Fix Released
> Status in linux source package in Xenial:
> Fix Released
> Status in linux source package in Yakkety:
> Fix Released
>
> Bug description:
> As per bug 721896 and various others:
>
> I'm on an AWS t2.micro instance (Xeon E5-2670, 991MiB of memory).
> Occasionally (about once a day), kswapd0 falls into a busy loop and
> spins on 100% CPU usage indefinitely. This can be provoked by
> copying/writing large files (e.g. dding a 256MB file), but it happens
> occasionally otherwise. System memory usage (not including
> buffers/caches) currently sits at 36%, which is typical[1]. Initially
> I had no swap space configured; I've since tried enabling a 256MB swap
> file, but the problem continues to occur and no swap space is used.
> The system can be recovered with `echo 1 > /proc/sys/
>
> Happy to provide further information/take further debugging actions.
>
>
> [1] Full output from `free`:
> total used free shared buffers cached
> Mem: 1014936 483448 531488 28556 9756 112700
> -/+ buffers/cache: 360992 653944
> Swap: 262140 0 262140
>
> ProblemType: Bug
> DistroRelease: Ubuntu 15.10
> Package: linux-image-
> ProcVersionSign
> Uname: Linux 4.2.0-18-generic x86_64
> AlsaDevices:
> total 0
> crw-rw---- 1 root audio 116, 1 Nov 19 19:40 seq
> crw-rw---- 1 root audio 116, 33 Nov 19 19:40 timer
> AplayDevices: Error: [Errno 2] No such file or directory: 'aplay'
> ApportVersion: 2.19.1-0ubuntu5
> Architecture: amd64
> ArecordDevices: Error: [Errno 2] No such file or directory: 'arecord'
> AudioDevicesInUse: Error: command ['fuser', '-v', '/dev/snd/seq',
> '/dev/snd/timer'] failed with exit code 1:
> CRDA: N/A
> Date: Fri Nov 20 20:44:30 2015
> Ec2AMI: ami-1c552a76
> Ec2AMIManifest: (unknown)
> Ec2Availability
> Ec2InstanceType: t2.micro
> Ec2Kernel: unavailable
> Ec2Ramdisk: unavailable
> IwConfig: Error: [Errno 2] No such file or directory: 'iwconfig'
> Lsusb: Error: command ['lsusb'] failed with exit code 1: unable to
> initialize libusb: -99
> MachineType: Xen HVM domU
> PciMultimedia:
>
> ProcEnviron:
> TERM=screen
> PATH=(custom, no user)
> LANG=en_US.UTF-8
> SHELL=/bin/bash
> ProcFB: 0 xen
> ProcKernelCmdLine: BOOT_IMAGE=
> root=UUID=
> console=ttyS0 net.ifnames=0
> RelatedPackageV
> linux-restricte
|
|
#207 |
(In reply to Dan Streetman from comment #52)
> of course those cause kswapd work, all those commands will fill your page
> cache and kswapd is responsible for clearing those pages out.
>
> kswapd running isn't a problem, if it's doing work. kswapd running
> *without* doing work is the problem. When you stop running those commands,
> does kswapd catch up and stop using cpu? If so, that's normal. If not, and
> it never stops using cpu, that's the problem.
but, why kswapd so aggressively write something to storage when no data to flush (swap not set)?
| Changed in linux: | |
| importance: | Unknown → Medium |
| status: | Unknown → Confirmed |
|
|
#208 |
I reproduced the bug on the most recent kernel. I have extracted sysctl, meminfo and dmesg logs: please see my comments and attachments on the same bug: https:/
I also wrote simple python script that eats ram and reproduces the bug 100% for me
| Petr Doležal (elkir) wrote : | #209 |
Recently got a new laptop with a fresh install of Ubuntu 18.04 and now updated to kernel 4.19.21-
It still happens even with 16 GB of memory and 4GB more in swap on SSD. What is more dangerous is now that laptop has hyperthreading it goes absolutely crazy and heats up insanely. At that point, the system is so frozen no commands can fix it as one never gets to write them. Restarting the machine with a button is the only option.
| tags: | added: cscc |
| JPT (j-p-t) wrote : | #210 |
Still not solved.
Linux 5.0.0-29-generic #31-Ubuntu SMP Thu Sep 12 13:05:32 UTC 2019 x86_64 x86_64 x86_64 GNU/Linux
This system has i5-9600K and 16 GB RAM, no swap.
This happens everytime I run a VirtualbBox VM.
The VM has got 4 GB RAM.
I updated my VMs to current default settings for Windows and reduced CPU count to 1.
This solved the issue until I ran video compression on the host system concurrently.
So the problem still happens when CPU usage is high and a VM is running.
This time I succeeded in rescuing the system avoiding a reboot.
I switched to console mode and waited a lot of time (like an hour) until I was able to kill VirtualBox.
What I saw was: kswapd0 was running crazy.
| Tobias (vallanmandrake) wrote (last edit ): | #211 |
Still not solved.
Bug happens on Fresh install of Kubuntu 21.04 with reccomended HDD distribution on modern Lapotp (Ryzen5, 5500U).
And on older Laptop (~2014) with Ubuntu 20.04 & 21.04, Kubuntu 21.04 and Lubuntu 20.04 & 20.10 & 21.04. (experienced often, sometimes every few hours) Kswapd0 process rapidly increases in CPU then uses all resources (no result after hours) necessating reboot.
Killing a high Ram process (in the few seconds till all CPU is taken) (p.e. Firefox) stops the Kswapd0 process.
Am willing to provide additional data / reformat old laptop for tests etc.
|
|
#212 |
Reproduced on latest centos kernel 3.10.0-1160.53
It's so strange that this keeps on happening I tried disabling swap and everything but it doesn't care. There's 100 GB free ram and yet it happens
|
|
#213 |
I'm working with CentOS Linux kernel version 3.10.0-1160.49.1 and I also noticed that kswapd0 runs for over 20 seconds and seem to cause a kernel panic. In examining the kswapd() code, it has an infinite loop. It can only break from this loop if the function, kthread_
Anyone have a comment?
|
|
#214 |
I believe this bug has be fixed in later versions of the Linux kernel. I tested kswapd0 by writing a C program that create a large memory map for a file. I then encapsulate the above C program to generate several thousand instances of the C program. My computer is running version 5.17 of the Linux kernel. The computer bogged down, but the kswapd0 did not have a problem.
I believe this bug should be closed.
|
|
#218 |
You can also look at what is pulling the input/output subsystem:
- display and accumulate only those altlinux and root user processes that pull I/O and update with a frequency of one second:
Code: [Select]
# iotop -d 1 -u altlinux -u root -o -a
Process activity statistics in iotop, in a live system with xfce+systemd:
Total DISK READ: 0.00 B/s | Total DISK WRITE: 1628.33 B/s
TID PRIO USER DISK READ DISK WRITE SWAPIN IO> COMMAND
3773 be/4 altlinux 0.00 B 4.75 M 0.00 % 0.63 % firefox-bin
4602 be/4 root 0.00 B 64.00 K 0.00 % 0.78 % [kworker/u2:22]
3948 be/4 root 0.00 B 0.00 B 0.00 % 0.10 % [kworker/0:0]
319 be/4 root 40.00 K 7.72 M 0.00 % 0.08 % systemd-journald
3760 be/4 altlinux 0.00 B 13.12 M 0.00 % 0.04 % firefox-bin
4856 be/4 root 0.00 B 0.00 B 0.00 % 0.36 % [kworker/0:1]
169 be/0 root 1912.00 K 0.00 B 0.00 % 0.04 % [loop0]
3810 be/4 altlinux 0.00 B 8.54 M 0.00 % 0.02 % firefox-bin
1146 be/4 altlinux 0.00 B 52.00 K 0.00 % 0.02 % xfconfd
3746 be/4 altlinux 0.00 B 1388.00 K 0.00 % 0.02 % firefox-bin
1178 be/4 root 0.00 B 212.00 K 0.00 % 0.02 % upowerd
878 be/4 root 4.00 K 68.00 K 0.00 % 0.01 % NetworkManager --no-daemon
936 be/4 root 0.00 B 20.00 K 0.00 % 0.00 % X :0 -auth /var/run/
1159 be/4 altlinux 104.00 K 24.00 K 0.00 % 0.00 % xfce4-panel
326 be/4 root 8.00 K 20.00 K 0.00 % 0.00 % systemd-udevd
1217 be/4 root 0.00 B 0.00 B 0.00 % 0.00 % udisksd --no-debug
1 be/4 root 0.00 B 4.00 K 0.00 % 0.00 % init https:/
1148 be/4 altlinux 0.00 B 24.00 K 0.00 % 0.00 % xfce4-session
1165 be/4 altlinux 0.00 B 4.00 K 0.00 % 0.00 % nm-applet
1261 be/4 altlinux 0.00 B 24.00 K 0.00 % 0.00 % wrapper /usr/lib/
3745 be/4 altlinux 0.00 B 3.36 M 0.00 % 0.00 % firefox-bin
3747 be/4 altlinux 0.00 B 32.00 K 0.00 % 0.00 % firefox-bin
3777 be/4 altlinux 0.00 B 9.54 M 0.00 % 0.00 % firefox-bin
| Changed in linux (Ubuntu): | |
| assignee: | Dan Streetman (ddstreet) → nobody |
| Changed in linux (Ubuntu Xenial): | |
| assignee: | Dan Streetman (ddstreet) → nobody |
| Changed in linux (Ubuntu Yakkety): | |
| assignee: | Dan Streetman (ddstreet) → nobody |
kswapd0 randomly load one core of CPU by 100%
Linux localhost 3.12.0-1-ARCH #1 SMP PREEMPT Wed Nov 6 09:06:27 CET 2013 x86_64 GNU/Linux
No swap enabled
Befor on same laptop was installed Ubuntu 12.04 and kernel 3.2 32-bit pae, and there is no such problem.
[root@localhost ~]# free -mh
total used free shared buffers cached
Mem: 3.8G 2.4G 1.3G 0B 150M 508M
-/+ buffers/cache: 1.8G 2.0G
Swap: 0B 0B 0B
[root@localhost ~]# cat /proc/meminfo
MemTotal: 3935792 kB
MemFree: 1381360 kB
Buffers: 154216 kB
Cached: 533096 kB
SwapCached: 0 kB
Active: 1958896 kB
Inactive: 438004 kB
Active(anon): 1740916 kB
Inactive(anon): 136292 kB
Active(file): 217980 kB
Inactive(file): 301712 kB
Unevictable: 0 kB
Mlocked: 0 kB
SwapTotal: 0 kB
SwapFree: 0 kB
Dirty: 2064 kB
Writeback: 0 kB
AnonPages: 1709628 kB
Mapped: 196696 kB
Shmem: 167620 kB
Slab: 81516 kB
SReclaimable: 61312 kB
SUnreclaim: 20204 kB
KernelStack: 1696 kB
PageTables: 13088 kB
NFS_Unstable: 0 kB
Bounce: 0 kB
WritebackTmp: 0 kB
CommitLimit: 1967896 kB
Committed_AS: 3498576 kB
VmallocTotal: 34359738367 kB
VmallocUsed: 361304 kB
VmallocChunk: 34359300731 kB
HardwareCorrupted: 0 kB
AnonHugePages: 157696 kB
HugePages_Total: 0
HugePages_Free: 0
HugePages_Rsvd: 0
HugePages_Surp: 0
Hugepagesize: 2048 kB
DirectMap4k: 18476 kB
DirectMap2M: 4059136 kB
And I can't kill it. I heared that it's not good idea, but just for lulz)