As per bug 721896 and various others:
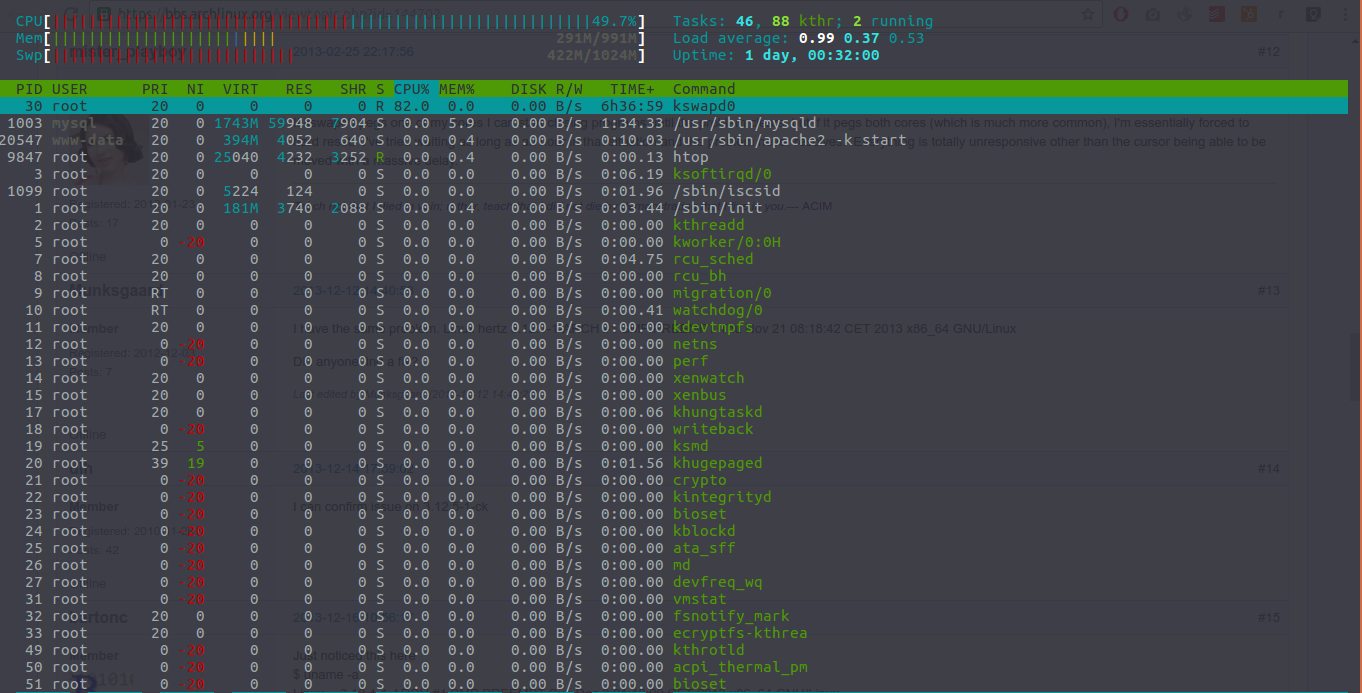
I'm on an AWS t2.micro instance (Xeon E5-2670, 991MiB of memory). Occasionally (about once a day), kswapd0 falls into a busy loop and spins on 100% CPU usage indefinitely. This can be provoked by copying/writing large files (e.g. dding a 256MB file), but it happens occasionally otherwise. System memory usage (not including buffers/caches) currently sits at 36%, which is typical[1]. Initially I had no swap space configured; I've since tried enabling a 256MB swap file, but the problem continues to occur and no swap space is used. The system can be recovered with `echo 1 > /proc/sys/vm/drop_caches`.
Happy to provide further information/take further debugging actions.
[1] Full output from `free`:
total used free shared buffers cached
Mem: 1014936 483448 531488 28556 9756 112700
-/+ buffers/cache: 360992 653944
Swap: 262140 0 262140
ProblemType: Bug
DistroRelease: Ubuntu 15.10
Package: linux-image-4.2.0-18-generic 4.2.0-18.22
ProcVersionSignature: Ubuntu 4.2.0-18.22-generic 4.2.3
Uname: Linux 4.2.0-18-generic x86_64
AlsaDevices:
total 0
crw-rw---- 1 root audio 116, 1 Nov 19 19:40 seq
crw-rw---- 1 root audio 116, 33 Nov 19 19:40 timer
AplayDevices: Error: [Errno 2] No such file or directory: 'aplay'
ApportVersion: 2.19.1-0ubuntu5
Architecture: amd64
ArecordDevices: Error: [Errno 2] No such file or directory: 'arecord'
AudioDevicesInUse: Error: command ['fuser', '-v', '/dev/snd/seq', '/dev/snd/timer'] failed with exit code 1:
CRDA: N/A
Date: Fri Nov 20 20:44:30 2015
Ec2AMI: ami-1c552a76
Ec2AMIManifest: (unknown)
Ec2AvailabilityZone: us-east-1d
Ec2InstanceType: t2.micro
Ec2Kernel: unavailable
Ec2Ramdisk: unavailable
IwConfig: Error: [Errno 2] No such file or directory: 'iwconfig'
Lsusb: Error: command ['lsusb'] failed with exit code 1: unable to initialize libusb: -99
MachineType: Xen HVM domU
PciMultimedia:
ProcEnviron:
TERM=screen
PATH=(custom, no user)
LANG=en_US.UTF-8
SHELL=/bin/bash
ProcFB: 0 xen
ProcKernelCmdLine: BOOT_IMAGE=/boot/vmlinuz-4.2.0-18-generic root=UUID=35bc01f4-4602-4823-976e-508edef899df ro console=tty1 console=ttyS0 net.ifnames=0
RelatedPackageVersions:
linux-restricted-modules-4.2.0-18-generic N/A
linux-backports-modules-4.2.0-18-generic N/A
linux-firmware N/A
RfKill: Error: [Errno 2] No such file or directory: 'rfkill'
SourcePackage: linux
UdevLog: Error: [Errno 2] No such file or directory: '/var/log/udev'
UpgradeStatus: No upgrade log present (probably fresh install)
dmi.bios.date: 05/06/2015
dmi.bios.vendor: Xen
dmi.bios.version: 4.2.amazon
dmi.chassis.type: 1
dmi.chassis.vendor: Xen
dmi.modalias: dmi:bvnXen:bvr4.2.amazon:bd05/06/2015:svnXen:pnHVMdomU:pvr4.2.amazon:cvnXen:ct1:cvr:
dmi.product.name: HVM domU
dmi.product.version: 4.2.amazon
dmi.sys.vendor: Xen


{kind=link}
{kind=link}
This change was made by a bot.