
[Hyper-V] Ubuntu 14.04.2 LTS Generation 2 SCSI Errors on VSS Based Backups
- Xenial (16.04)
- Bug #1470250
| Affects | Status | Importance | Assigned to | Milestone | |
|---|---|---|---|---|---|
| linux (Ubuntu) |
Fix Released
|
Critical
|
Unassigned | ||
| Trusty |
Won't Fix
|
High
|
Unassigned | ||
| Xenial |
Fix Released
|
Critical
|
Unassigned | ||
| Yakkety |
Fix Released
|
Critical
|
Unassigned | ||
| Zesty |
Fix Released
|
Critical
|
Unassigned | ||
Bug Description
Customers have reported running various versions of Ubuntu 14.04.2 LTS on Generation 2 Hyper-V Hosts. On a random Basis, the file system will be mounted Read-Only due to a "disk error" (which really isn't the case here). As a result, they must reboot the Ubuntu guest to get the file system to mount RW again.
The Error seen are the following:
Apr 30 00:02:01 balticnetworkst
Apr 30 00:02:01 balticnetworkst
Apr 30 00:02:01 balticnetworkst
Apr 30 01:23:26 balticnetworkst
Apr 30 01:23:26 balticnetworkst
Apr 30 01:23:26 balticnetworkst
Apr 30 01:23:26 balticnetworkst
Apr 30 01:23:26 balticnetworkst
This relates to the VSS "Windows Server Backup" process that kicks off at midnight on the host and finishes an hour and half later.
Yes, we do have hv_vss_daemon and hv_kvp_daemon running for the correct kernel version we have. We're currently running kernel version 3.13.0-49-generic #83 on one system and 3.16.0-34-generic #37 on the other. -- We see the same errors on both.
As a result, we've been hesitant to drop any more ubuntu guests on our 2012R2 hyper-v system because of this. We can stop the backup process and all is good, but we need nightly backups to image all of our VM's. All the windows guests have no issues of course. We also have some CentOS based guests running without issues from what we've seen.

| Joseph Salisbury (jsalisbury) wrote : | #1 |
| Changed in linux (Ubuntu): | |
| status: | New → In Progress |
| importance: | Undecided → Critical |
| Frederik Bosch (f-bosch) wrote : | #2 |
My latest report was that latest builds with patches are much more stable but are also not a complete fix for the problem. It is still there and occurs randomly. The error message is not changed. I have no real indication what causes the read-only state. During the latest RO state I noticed there was a IO peak at that time. However, the IO peak was just unpacking some files from a tar.gz.
| Joseph Salisbury (jsalisbury) wrote : | #3 |
Error message that happens when this bug occurs:
[154272.293488] sd 2:0:0:0: [storvsc] Sense Key : Unit Attention [current]
[154272.293508] sd 2:0:0:0: [storvsc] Add. Sense: Changed operating definition
[154272.293665] sd 2:0:0:0: Warning! Received an indication that the operating parameters on this target have changed. The Linux SCSI layer does not automatically adjust these parameters.
[154272.293671] blk_update_request: I/O error, dev sda, sector 201805560
[154272.293718] Aborting journal on device sda1-8.
[154272.314119] EXT4-fs error (device sda1): ext4_journal_
[154272.314154] EXT4-fs (sda1): Remounting filesystem read-only
| Joseph Salisbury (jsalisbury) wrote : | #4 |
@Frederik Bosch Can you post what kernel version you are currently using?
| Joshua R. Poulson (jrp) wrote : | #5 |
I believe he is running 14.04.2, which means at least the HWE kernel.
| Frederik Bosch (f-bosch) wrote : | #6 |
@jrp @jsalisbury I am using this kernel: http://
| Frederik Bosch (f-bosch) wrote : | #7 |
@jrp @jsalisbury I am using this kernel: http://
| Joseph Salisbury (jsalisbury) wrote : | #8 |
Prior comments regarding this issue can be found in bug 1445195
| Changed in linux (Ubuntu Vivid): | |
| status: | New → In Progress |
| Changed in linux (Ubuntu Utopic): | |
| status: | New → In Progress |
| Changed in linux (Ubuntu Trusty): | |
| status: | New → In Progress |
| Changed in linux (Ubuntu Vivid): | |
| importance: | Undecided → High |
| Changed in linux (Ubuntu Utopic): | |
| importance: | Undecided → High |
| Changed in linux (Ubuntu Trusty): | |
| importance: | Undecided → High |
| Changed in linux (Ubuntu Wily): | |
| importance: | Critical → High |
| Changed in linux (Ubuntu Vivid): | |
| assignee: | nobody → Joseph Salisbury (jsalisbury) |
| Changed in linux (Ubuntu Utopic): | |
| assignee: | nobody → Joseph Salisbury (jsalisbury) |
| Changed in linux (Ubuntu Trusty): | |
| assignee: | nobody → Joseph Salisbury (jsalisbury) |
| Joseph Salisbury (jsalisbury) wrote : | #9 |
The Wily kernel has been rebased to upstream 4.1, which has all the current Hyper-V commits in mainline. Can you give this test kernel a test to see if it still exhibits this issue, or if it is resolved.
If it still exhibits the issue, we know that a new fix is needed. If this test kernel fixes this issue, we know it is fixed upstream and we need to identify which commit(s) fix things.
The test kernel can be downloaded from:
http://
Thanks in advance!
| Frederik Bosch (f-bosch) wrote : | #10 |
@jsalisbury I did not find any new commits on this subject in the current kernel master (https:/
So testing this test kernel would mean I am testing whether another commit (not specifically for this issue) might have fixed this issue, right?
| Joseph Salisbury (jsalisbury) wrote : | #11 |
@Frederik, yes that is correct. This kernel basically has all HV related commits that are currently in mainline.
| Frederik Bosch (f-bosch) wrote : | #12 |
@jsalisbury I will start testing this week. However, I feel the latest reports were pretty clear: the issue is there. While I was the only one at first that still had problems, after a while more people reported (in bug 1441595) that the new build still contains the issue. In my opinion, it is now HyperV team's turn to come up with a final solution. Nevertheless, I want to contribute where possible. /cc @jrp
| Frederik Bosch (f-bosch) wrote : | #13 |
That should have been bug 1445195.
| Dustin (dander88) wrote : | #14 |
We have the same VSS Issues in 14.04 LTS but hyper v (2012) gen 1. Has this been seen before? We can reproduce the error on command.
Received an indication that the operating parameters on this target have changed. The Linux SCSI layer does not automatically adjust these parameters.
| Joseph Salisbury (jsalisbury) wrote : | #15 |
@Dustin it sounds like you have a reliable way to reproduce this bug? If so, can you list those steps here for others to try?
Also, if you can reproduce this, would it be possible for you to test the kernel posted in comment #9?
Thanks!
| ubuntu (h-lbuntu-2) wrote : | #16 |
On the other bug (1445195) somebody reported seeing the same error on Gen 1 devices. I wanted to report that we see the identical bug on both Gen 1 and Gen 2 devices. Frequency does not appear to be any different but I don't have precise data.
| Dustin (dander88) wrote : | #17 |
@Joseph - There are not too much, we use the backup program called ALTARO. It will produce this error about every 10 or so backups.
We are working on getting that new kernel into some test units. I will post results when we are done. Thanks for the follow up.
| Chris Valean (cvalean) wrote : | #18 |
Hi Dustin,
Some questions on the topic, my apologize if these got replied before or in other threads.
1. Is this repro using Windows Server Backup directly, and not through Altaro?
2. For the VM setup, is this a standard local vhdx on scsi controller 0 for a Gen2 VM for OS disk? Or there are any other disks attached to the VM?
3. Backup location - is this done to a separate local disk or where exactly?
4. VM and vm disk load - I/O - before I saw that there was only an archive untar, what is the general load or services running on the system at the time of the backup?
| John Wilkinson (cohn) wrote : | #19 |
@Joseph Salisbury Is there a specific subset of those .deb packages that need to be run, or are they all needed to patch the relevant bugs?
| Dustin (dander88) wrote : | #20 |
@Chris -
1- No Local Backup at all - All through Altaro
2 - Standard Local on Scsi 0
3- Sent to a local NAS
3 - I dont know the exact load that they currently have - I know that it is under 80% of system resources for sure. Not 100% on the services, I know MYSQL, other than that not sure.
| Dustin (dander88) wrote : | #21 |
After running the patches, we are still seeing the same error in the syslog. Options?
| Joseph Salisbury (jsalisbury) wrote : | #22 |
@Dustin, can you run "uname -a" to confirm your machine is running the latest Wily kernel built from the current mainline kernel?
| Joseph Salisbury (jsalisbury) wrote : | #23 |
@John WIlkinson, You should only need the linux-image and linux-image-extra .deb packages to install the latest kernel. The -headers .deb packages should not be needed.
| Frederik Bosch (f-bosch) wrote : | #24 |
@dander88 According to @jrp the message "Received an indication that the operating parameters on this target have changed. The Linux SCSI layer does not automatically adjust these parameters." is beneign. He mentioned that in bug 1445195.
Are you just seeing that message or do your systems also go into read-only mode? From my point of view the SCSI message has no significance to the read-only bug. The message also pops up with successful backups.
@h-lbuntu-2 What kind of bug do you mean? Also the SCSiI message? Or do you also have read-only problems?
@cohn I would install them all. Be aware you might have to ignore dependencies when you are on 14.04 and go to kernel 3.19, e.g. binutils. Run dpkg --ignore-
| Frederik Bosch (f-bosch) wrote : | #25 |
@cohn By the way, I have not installed the 4.x kernels yet. So I have no idea how many dependency problems you will run in to. Could you let me know?
| Dustin (dander88) wrote : | #26 |
@F-Bosch we did not enter the "read-only" mode with the one test we tried. I will keep a backup schedule going multiple times a day and see if it ever goes into read only mode. I will report back in a few days to let you know the results
| Dustin (dander88) wrote : | #27 |
So far so good after the kernal update. I have been backing up a test VM 4 times a day for almost 2 weeks. It has not gone into read only mode as of yet.
| Frederik Bosch (f-bosch) wrote : | #28 |
@dander88 That sounds great, but we had the same results for a test VPS machine. As indicated by @jrp before: it depends on your IO load if the machine goes into read-only. And test machines usually do not have that many IO load.
| Joseph Salisbury (jsalisbury) wrote : | #29 |
@Frederik, have you tested with the Wily kernel yet, posted in comment #9? The Wily kernel has since been rebased to 4.2, so testing of the latest kernel by applying the latest Wily updates would be great.
| ubuntu (h-lbuntu-2) wrote : | #30 |
Bug is still present in Vivid 3.19.0-26-generic.
Is there a workaround that avoids this problem? There's considerable pressure to move off of Hyper-V and I'd rather not do it.
[57055.788468] sd 0:0:0:0: [storvsc] Sense Key : Unit Attention [current]
[57055.788561] sd 0:0:0:0: [storvsc] Add. Sense: Changed operating definition
[57055.788704] sd 0:0:0:0: Warning! Received an indication that the operating parameters on this target have changed. The Linux SCSI layer does not automatically adjust these parameters.
[57055.788719] blk_update_request: I/O error, dev sda, sector 207053224
[57055.788924] Aborting journal on device sda2-8.
[57055.880744] EXT4-fs error (device sda2): ext4_journal_
[57055.880833] EXT4-fs (sda2): Remounting filesystem read-only
[57055.885165] sd 0:0:0:1: [storvsc] Sense Key : Unit Attention [current]
[57055.885269] sd 0:0:0:1: [storvsc] Add. Sense: Changed operating definition
[57055.885342] sd 0:0:0:1: Warning! Received an indication that the operating parameters on this target have changed. The Linux SCSI layer does not automatically adjust these parameters.
[57315.373166] sd 0:0:0:2: [storvsc] Sense Key : Unit Attention [current]
[57315.373230] sd 0:0:0:2: [storvsc] Add. Sense: Changed operating definition
[57315.373379] sd 0:0:0:2: Warning! Received an indication that the operating parameters on this target have changed. The Linux SCSI layer does not automatically adjust these parameters.
Linux db003 3.19.0-26-generic #28-Ubuntu SMP Tue Aug 11 14:16:32 UTC 2015 x86_64 x86_64 x86_64 GNU/Linux
| ubuntu (h-lbuntu-2) wrote : | #31 |
To add to comment #30 I posted, the read-only bug continues to occur on both Generation 1 and Generation 2 VMs.
| Joseph Salisbury (jsalisbury) wrote : | #32 |
@ubuntu
Is it possible for you to test the latest Wily kernel? The Wily kernel has been rebased to the upstream 4.2 kernel, so it should have all the latest Hyper-V updates in mainline.
The Wily kernel can be downloaded from:
https:/
| ubuntu (h-lbuntu-2) wrote : | #33 |
@Joseph
Thank you. I upgraded the production server that is most often errors out with the Wily kernel you referenced above and will report back Please be patient, an individual VM can go several days without the error.
| Frederik Bosch (f-bosch) wrote : | #34 |
Unfortunately, I did not have had time to test Willy kernels. But the other 3.x stable kernels are still contain the problem.
| Joshua R. Poulson (jrp) wrote : | #35 |
We're getting ready for a new round of storvsc fixes that correspond to LIS 4.0.11 we'll have to see if that improves things further.
| Frederik Bosch (f-bosch) wrote : | #36 |
@jrp Thanks for that, I am happy to hear there is still being worked on. Let me know if there is a build that I can test
@h-lbuntu-2 How are your results with Willy kernels?
| ubuntu (h-lbuntu-2) wrote : | #37 |
Just wanted to report that I installed the Wily Kernel on Sept 3rd and the VM's ran without errors until yesterday. The errors are different then before but doing the same thing:
blk_update_request: I/O error, dev sda, sector 206963000
Aborting journal on device sda2-8
EXT4-fs errors (device sda2): ext4_journal_
EXT4-fs (sda2): Remounting filesystem read-only
| The Fold (stuart-luscombe) wrote : | #38 |
I am experiencing this same issue when backing up a 14.04 LTS Gen 1 VM using Veeam. The error seems to occur when the VSS snapshots are being taken. The error did not occur until I had followed Microsoft's instructions on packages to install for Ubuntu (https:/
| Frederik Bosch (f-bosch) wrote : | #39 |
What do you mean with: did not occur until you followed those instructions? You mean without the daemons everything was fine?
| Frederik Bosch (f-bosch) wrote : | #40 |
A little remark that still has no answer yet: what are the Ubuntu specifics that cause this issue? In the 10 months we have these machines running: many crashes for Ubuntu with VSS snapshots while the CentOS machines have had no crash at all. Maybe @jsalisbury has a explanation for this?
| Joseph Salisbury (jsalisbury) wrote : | #41 |
We are currently awaiting the patches posted in comment #35.
Can you post the specific CentOS kernel version you are using?
| Frederik Bosch (f-bosch) wrote : | #42 |
@jsalisbury uname -a for the CentOS machines is: Linux host.name 3.10.0-
The technet link you posted contains the following quote: "As a result, we've been hesitant to drop any more ubuntu guests on our 2012R2 hyper-v system because of this. We can stop the backup process and all is good, but we need nightly backups to image all of our VM's. All the windows guests have no issues of course. We also have some CentOS based guests running without issues from what we've seen."
So I am not the only one that is seeing this behaviour.
| The Fold (stuart-luscombe) wrote : | #43 |
@f-bosch (#39)
I had been able to carry out backups on the VM prior to installing the daemons but I was not able to produce full file indexes and my Hyper-V monitoring software would complain about integration services not being enabled.
| Frederik Bosch (f-bosch) wrote : | #44 |
@stuart-luscombe So if I understand correctly, the reason why you installed the daemons was to get full file indexes and no complaints by monitoring software. However, the downside is that the VMs started crashing during backups after the install? More importantly, can you confirm there was no problem with backups before installing the daemons?
| The Fold (stuart-luscombe) wrote : | #45 |
- Veeam Backup status before and after installing Hyper-V tools Edit (152.0 KiB, image/png)
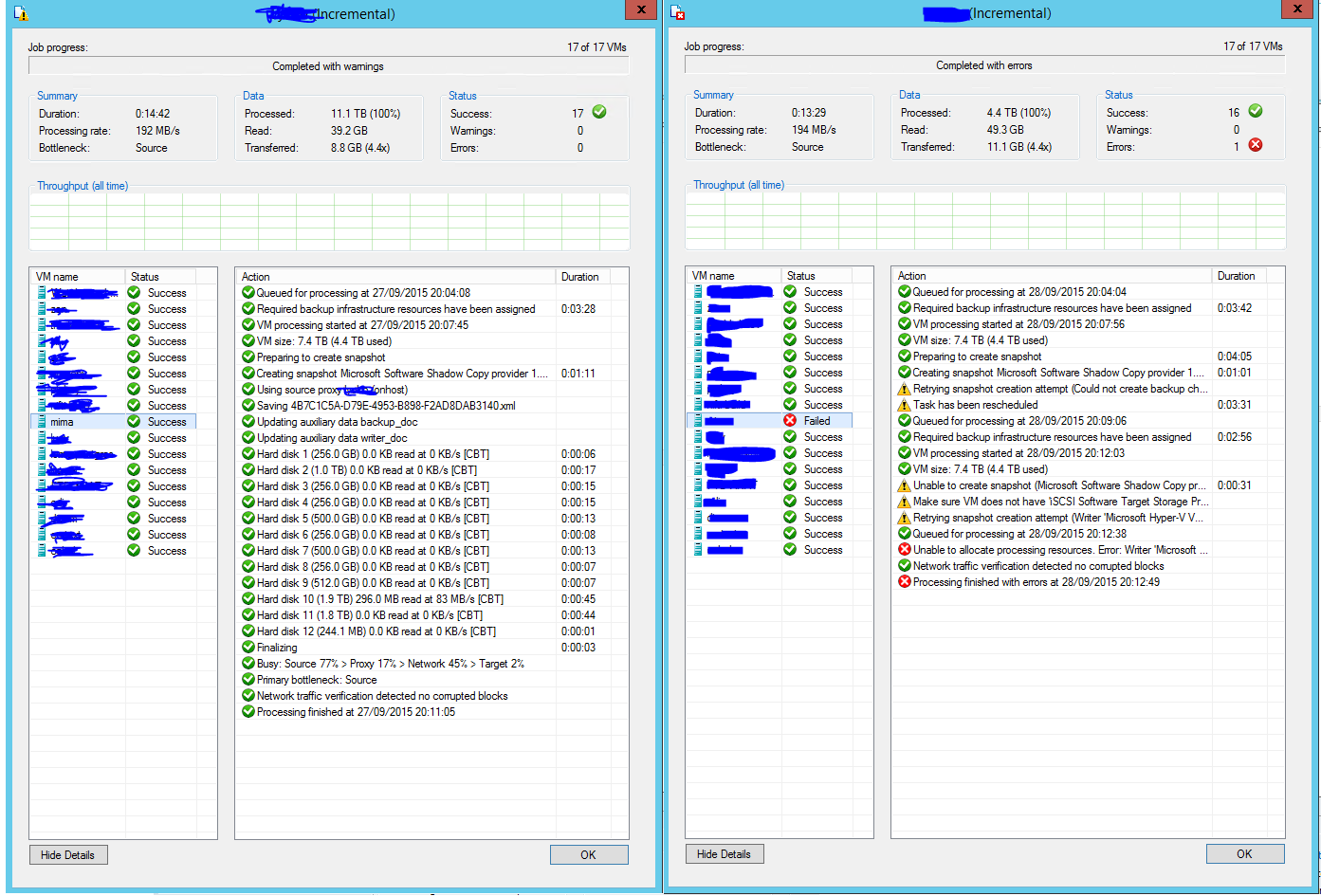{kind=link}
@f-bosch That's correct.
I just checked back through my backup logs and the VM was backing up without error prior to following the technet instructions. I've attached a grab of the status windows for both jobs.
| Frederik Bosch (f-bosch) wrote : | #46 |
@stuart-luscombe That is interesting. So if we combine both our observations, then my conclusion is: there must be something in the hyper v daemons. And one the things to look at is where the Ubuntu daemons might differ from the CentOS daemons. Maybe @jsalisbury knows if there is any difference between the two? And also why are they different?
| ubuntu (h-lbuntu-2) wrote : | #47 |
Sorry for the long delay in posting results but I did want to share what we've learned.
1) The failures happen during the VSS Snapshot/checkpoint creation process. You can reproduce the errors by doing manual VSS snapshots.
2) The heavier the VM load, especially I/O, the more likely the error will occur.
3) Every kernel posted (including the Willy) share the same problem - differences were not significant between them.
4) During snapshot creation, even RHEL hits a bump. There's a small delay in response times but nothing that causes errors. Installing LIS 4.0 doesn't make a difference.
Unfortunately, I can't follow-up with further testing. After figuring this out we cancelled the migration to Hyper-V and invested further in our VMware infrastructure. :( Thanks!
| Joseph Salisbury (jsalisbury) wrote : | #48 |
I built an Ubuntu kernel based on 3.10, so it is the same base kernel version as CentOS posted in comment #42. If possible, can this kernel be tested to see if this issue is due to a regression introduced after 3.10?
The test kernel can be downloaded from:
http://
Thanks in advance!
| Paula Crismaru (pcrismaru) wrote : | #49 |
- icalog.txt Edit (17.0 KiB, text/plain)
I tested the kernel from #48 and it's not booting. I am attaching the log.
| Joseph Salisbury (jsalisbury) wrote : | #50 |
I'll see if I can figured out why the 3.10 based kernel doesn't boot. However, it may just be easier to test the Precise kernel, which is 3.2 based.
The latest Precise kernel can be downloaded from:
https:/
| Frederik Bosch (f-bosch) wrote : Re: [Bug 1470250] Re: [Hyper-V] Ubuntu 14.04.2 LTS Generation 2 SCSI Errors on VSS Based Backups | #51 |
Since I was on holidays, I will give this a try in next two weeks. Thanks for the effort @jalisbury.
> On 20 Nov 2015, at 15:06, Joseph Salisbury <email address hidden> wrote:
>
> I'll see if I can figured out why the 3.10 based kernel doesn't boot.
> However, it may just be easier to test the Precise kernel, which is 3.2
> based.
>
> The latest Precise kernel can be downloaded from:
> https:/
>
> --
> You received this bug notification because you are subscribed to the bug
> report.
> https:/
>
> Title:
> [Hyper-V] Ubuntu 14.04.2 LTS Generation 2 SCSI Errors on VSS Based
> Backups
>
> Status in linux package in Ubuntu:
> In Progress
> Status in linux source package in Trusty:
> In Progress
> Status in linux source package in Utopic:
> In Progress
> Status in linux source package in Vivid:
> In Progress
> Status in linux source package in Wily:
> In Progress
>
> Bug description:
> Customers have reported running various versions of Ubuntu 14.04.2 LTS
> on Generation 2 Hyper-V Hosts. On a random Basis, the file system
> will be mounted Read-Only due to a "disk error" (which really isn't
> the case here). As a result, they must reboot the Ubuntu guest to
> get the file system to mount RW again.
>
> The Error seen are the following:
> Apr 30 00:02:01 balticnetworkst
> Apr 30 00:02:01 balticnetworkst
> Apr 30 00:02:01 balticnetworkst
> Apr 30 01:23:26 balticnetworkst
> Apr 30 01:23:26 balticnetworkst
> Apr 30 01:23:26 balticnetworkst
> Apr 30 01:23:26 balticnetworkst
> Apr 30 01:23:26 balticnetworkst
>
> This relates to the VSS "Windows Server Backup" process that kicks off at midnight on the host and finishes an hour and half later.
> Yes, we do have hv_vss_daemon and hv_kvp_daemon running for the correct kernel version we have. We're currently running kernel version 3.13.0-49-generic #83 on one system and 3.16.0-34-generic #37 on the other. -- We see the same errors on both.
> As a result, we've been hesitant to drop any more ubuntu guests on our 2012R2 hyper-v system because of this. We can stop the backup process and all is good, but we need nightly backups to image all of our VM'...
| Michele Primavera (michyprima) wrote : | #52 |
I'm on 15.10 and experiencing this problem. Windows Server 2012 r2
I'm available to test if needed
| Michele Primavera (michyprima) wrote : | #53 |
I can confirm the kernel from #50 does not boot
| Frederik Bosch (f-bosch) wrote : | #54 |
This problem started more than a year ago, I decided together with my hoster to look at alternatives. Backup is the only thing that is causing problems for us with HyperV. The problem is two fold. First, the read-only state machines get into when generating the backup. Second, the read/write spike we see during a backup.
While this topic is focussed on the backups, the latter (spikes) is more and more causing problems. The more data getting on the disk, the higher the spikes are. Http requests that usually take < 100 ms are causing multiple seconds. More specifically, requests that involve write operations tend to have these characteristics. The read-only already made us reduce the amount of backups, because we want to decrease the risk of downtime. Now, with this (new) problem, it is almost impossible that a client does not suffer from a backup. That situation is wrong.
Since, it is so hard to debug (impossible for us to replicate behaviour on a test machine) and it is hard to tell when the problem will be solved, we decided, after a year, to look at alternatives. Nonetheless, thanks for the help we got here. That is much appreciated.
| Joseph Salisbury (jsalisbury) wrote : | #55 |
@Michele, can you confirm that you installed both the linux-image and linux-image-extra .deb packages from the link I posted in #50?
| Michele Primavera (michyprima) wrote : | #56 |
@Joseph Yes, I did, but it does not get past the "loading ramdisk" message
as @Frederik says, this is a problem which could really kill ubuntu's usage on servers vm. I refused to move from ubuntu because I like it a lot, but I also refuse to increment my backup intervals. Almost every morning I need to fsck one of the vm because they go readonly
| Joseph Salisbury (jsalisbury) wrote : | #57 |
I'm now able to reproduce this bug on demand. It takes just under an hour to reproduce. I'm going to to try to reproduce a few more times to make sure it's consistent. If the reproduce is consistent, I'll list all the steps necessary.
Basically I'm using the tiotest benchmark from tiobench. The last supported version of tiotest for Ubuntu was in Precise, but the Precise version works fine on Wily, Vivid and Trusty. If the reproducer is consistent, I'll post a script with all the arguments to produce the correct IO pattern, if anyone else wants to test.
Now that I can reproduce this bug, I can run some of my own tests to try and figure out what is happening.
| Dexuan Cui (decui) wrote : | #58 |
@f-bosch Hi Frederik, we're really sorry that this backup-
The good news is: in #57, it looks Joseph found a reliable way to reproduce the issue within 1 hour. Joseph, after you confirm the reliable way, can you please share the detailed exact steps -- these are very important for us to debug the issue.
BTW, it looks the issue is Ubuntu-specific (CentOS doesn't have the issue according to Bug Description).
| Dexuan Cui (decui) wrote : | #59 |
@f-bosch Hi Frederik, about the second issue you mentioned ("The more data getting on the disk, the higher the spikes are...requests that involve write operations tend to have these characteristics") in #54, it looks there is a storage I/O performance downgrade somehow.
Do you think if it's related to the backup issue?
If not, do you think if we needs special I/O patters to trigger the perf downgrade?
| Frederik Bosch (f-bosch) wrote : | #60 |
@decui @jsalisbury That is indeed good news. Since we did not make any changes to our platform yet, we can help to test possible fixes. There were also some questions.
1. Occurrence of the issue: with the fixes of bug #1445195 the amount of read-only errors reduced drastically. But it is still there. We are making backups two times a week on three Ubuntu machines, and read-only occurs I believe once a month. And when a machine goes read-only, it is always just one machine, not all three. This situation requires us to create backups during working days because then we are able to restart machines immediately, hence causing little downtime.
2. Specificness of the issue: it is indeed a Ubuntu only problem, at least for us. In our Hyper-V cluster we have four virtual machines, three Ubuntu, one CentOS. The latter never suffered from the read-only problem.
3. IO-spike issue: you are correct that we have a I/O performance downgrade. And I now for sure it is related to backups. During a week we never have any I/O problems, only those exactly two times a week when we create backups. This downgrade came up recently, at least we are feeling the downgrade now. The cause might be that more and more disk space is getting occupied. Or that was a (kernel) update that is causing this issue. But my guess (and it is really a guess) is that is caused by the disk space and therefore the amount of data to backup.
Regarding our system. Since the fixes for bug #1445195 were released, we switched back to the latest 3.13 kernel in our production environments. But if I need to switch kernel to help fixing the bug, I think that would be no problem. Luckily we can now, with the work of @jsalisbury, do this without problems on a testing machine. Thank you for the work so far already!
| Dexuan Cui (decui) wrote : | #61 |
Frederik, Thanks for the new information!
About the I/O perf downgrade:
1. I don't think more occupied disk space should harm the perf so greatly (http resopnse time: from <100ms to several seconds).
2. The perf downgrade appeared recently but the backup issue appeared long long ago. Why do you think the downgrade is related to the backup issue?
| Frederik Bosch (f-bosch) wrote : | #62 |
@decui Regarding downgrade, I think I might not have been clear on this. The downgrade occurs only when there are backups running. Our performance otherwise is great. This (new) problem is not necessarily related to this specific issue, but more to backups on Hyper-V in general. Nonetheless, as I stated earlier, the problem is limiting us (even further) when and how many backups we are creating. This is far from an idealistic situation.
As I said, the cause of this problem might be occupied disk space. We have not changed anything else on our platform or setup, other than running the usual apt-get upgrades. Further, please see comment #47 where another user made a similar comment regarding performance downgrade. Maybe it is better if I create a separate bug report for this issue. Finally, regarding the downgrade issue, I am also prepared to provide access to our machines to employees of Microsoft and Ubuntu, if required.
| Joseph Salisbury (jsalisbury) wrote : | #63 |
| Joseph Salisbury (jsalisbury) wrote : | #64 |
I confirmed that the reproduce is repeatable. I can reproduce the bug within 30 to 60 minutes. The bug can be reproduce with the following steps:
1. Create a Virtual machine with 1 cpu and 2048M of memory.
2. Install Ubuntu on the VM. I installed 15.10(Wily).
3. Install the linux-cloud-tools package to get the VSS Snapshot daemon:
'sudo apt-get update'
'sudo apt-get install linux-cloud-tools'
4. Create a backup schedule for this VM to run every 30 minutes. In the advance settings I set the VSS Settings to "VSS copy Backup". I also configured the backup to backup to it's own hard disk. The machine I'm using only has two hard disks. One dedicated to Windows Server 2012 R2 and now the other for backups.
5. Download the tiobench .deb file from:
http://
6. Install tiobench with 'sudo dpkg -i tiobench_
7. Download the wrapper script that runs tiotest with the right IO pattern from bug report:
https:/
8. Create a working directory for tiotest in the same directory where the run_tiotest.sh script was saved and will be run from:
'mkdir tiotest-
9.Ensure run_tiotest.sh script is executable:
'chmod 755 run_tiotest.sh'
10. Start tiotest by running wrapper script: ./run_tiotest.sh
The bug will is reproduce when one of the backups is running. To speed things up, you could also try running "Backup once", otherwise just wait for the backups to start on their own.
The wrapper script is starting three instances of tiotest with different block sizes. My test machine has only once hard disk, so three instances of tiotest will cause the disk to be 60% to 100% utilized. This can be seen with iostat, which you can get by installing the sysstat package. If your test machine has more than once disk, more instances of tiotest may be needed in the wrapper script to increase the IO load.
Just let me know if none of the steps are clear. Now that I can reproduce the bug, I'll dig deeper and see if this is caused by a specific kernel.
| Joseph Salisbury (jsalisbury) wrote : | #66 |
Unfortunately, the 4.3 Xenial kernel eventually did hit this bug, it just took longer. I'll continue to investigate.
| Dexuan Cui (decui) wrote : | #67 |
Thanks @f-bosch for your clarification in #62. So my understanding is: the (temporary) I/O downgrade during the period of backup might be caused by the fact the disk space has been almost used up (?) recently, but it also might be somehow related to the backup. Let's focus on the backup issue at present.
Thanks @jsalisbury for the detailed test steps & script!
I suppose the result in #66 implies a real issue, which can't be fixed by the patches mentioned in bug 1519917. We're going to further investigate the issue too with the help of your test script.
| Frederik Bosch (f-bosch) wrote : | #68 |
@decui Correct, ceteris paribus, the only changes were more of the same (disk space) and some package changes through apt-get update (Ubuntu 14.04 LTS). My guess is that the downgrade is related to one of the two. But I agree, let's postpone this one, until the read-only bug is fixed. Afterwards, I will upgrade my production kernels to the latest stable 4.x kernel with the patch applied (I just read that the HWE kernel for 14.04 is going to 4.x in January anyhow). Then the performance might be different after all.
| Joseph Salisbury (jsalisbury) wrote : | #69 |
- run_tiotest_V2.sh Edit (323 bytes, text/x-sh)
If you let the wrapper script run long enough, it will eventually fill up the hard disk. This is because tiotest does not remove it's working files when it finishes. I just added a line after the wait to clean up the working directory. I would suggest using this new version of the script, which is attached.
| Dexuan Cui (decui) wrote : | #70 |
@f-bosch @jsalisbury
I can reproduce the issue consistently within 5~6 hours with a Ubuntu 15.10 VM.
In /var/log/syslog, several minutes before the file system is remounted as read-only, the hv_vss_daemon has stopped working: the daemon just always hangs on the poll() , not receiving freeze/thaw commands from the hv_utils driver at all.
I guess there might be a race condition in the hv_utils.ko driver, so the commands from the host are not received properly, or not forwarded to the daemon properly, so the daemon isn't be woken up.
Trying to track it down.
BTW, Since Ubuntu 15.04's code of the hv_utils driver and the daemon is the same as the upstream Linux, I think the upstream should have the same issue.
BTW, the below message looks like a benign warning -- I get this every time the backup begins, but I think it has nothing to do with the issue here:
[ 967.339810] sd 2:0:0:0: [storvsc] Sense Key : Unit Attention [current]
[ 967.339891] sd 2:0:0:0: [storvsc] Add. Sense: Changed operating definition
[ 967.340111] sd 2:0:0:0: Warning! Received an indication that the operating parameters on this target have changed. The Linux SCSI layer does not automa
| Dexuan Cui (decui) wrote : | #71 |
> "BTW, Since Ubuntu 15.04's "
typo.. 15.04 -> 15.10.
| Dexuan Cui (decui) wrote : | #72 |
I suspect the race condition may be in vss_on_msg() with the non-thread-safe variable vss_transaction
And I guess the below patch may have fixed the issue (the patch hasn't be in the upstream yet):
http://
I can only test the patch tomorrow. So it would be great if somebody can help to test the patch today, at your conveniement. Or, just wait my result. :-)
| no longer affects: | linux (Ubuntu Utopic) |
| Dexuan Cui (decui) wrote : | #73 |
The patch mentioned in #72 can't help -- still bad luck. :-(
But I can confirm: before the issue happens, somehow athe host doesn't send us freeze/thaw commands any longer.
we need further debugging...
| Srećko Jurić-Kavelj (jksrecko) wrote : | #74 |
Just wanted to chip in, we experienced the same problem twice now on a 12.04 LTS Gen 1 VM. Unlike situation described in comment #38, we haven't installed any daemons for the guest OS. Last time it happened, we could definitely correlate it to the Avamar (VSS based) backup. At the time, we were running kernel 3.13.0-68-generic #111~precise1-
| Michele Primavera (michyprima) wrote : | #75 |
I honestly just went the easy way doing that:
while true; do
mount | grep "sda1 on / type ext4 (ro" > /dev/null
if (($? == 0)); then
fsck -y /dev/sda1
reboot
fi
sleep 60
done
not the best practice for sure, but...
| Dexuan Cui (decui) wrote : | #76 |
My update:
It looks the issue is somehow related to the backup, but I tend to think there is a bug somewhere in the storvsc driver code -- it's very hard to track it down because before the ext4 read-only issue happens, the ext4 file system may have been somewhat corrupted.
| Joshua R. Poulson (jrp) wrote : | #77 |
We should consider the following upstream storvsc commits to see if they improve the situation:
storvsc_drv.c : commit 3209f9d780d137c
storvsc_drv.c : commit 81988a0e6b031bc
storvsc_drv.c : commit 8cf308e1225f5f9
| Joseph Salisbury (jsalisbury) wrote : | #78 |
I built a Wily test kernel with those three patches. The patches also required three prerequisite commits, so the test kernel has the following six commits:
4246a0b6 block: add a bi_error field to struct bio
54efd50b block: make generic_
03100aad block: Replace SG_GAPS with new queue limits mask
8cf308e storvsc: Don't set the SRB_FLAGS_
81988a0 storvsc: get rid of bounce buffer
3209f9d scsi: storvsc: Fix a bug in the handling of SRB status flags
The test kernel can be downloaded from:
http://
I'll see if I can still reproduce the bug with this kernel. I put it up for download, in case you want to test it as well, Dexuan.
| Frederik Bosch (f-bosch) wrote : | #79 |
If those commits could just be fixes for the problem we are having, that would be a really good start of 2016!
| Joseph Salisbury (jsalisbury) wrote : | #80 |
The test kernel I built in comment #78 is failing to boot. I'm going to review my backports and build another test kernel. I'll post a link to it here shortly.
| Frederik Bosch (f-bosch) wrote : | #81 |
Is there anything I can do to help? After @jsalisbury posted the method to reproduce the issue and there was a sign of commitment by @decui, we decided to postpone our decision of moving away from Hyper-V.
Now we have yet again the general feeling that this issue will not be solved soon. While I can totally understand that other things have higher priority than this, I cannot understand the lack of communication. It would be at least kind to let people know what they can expect. Is it really going to last one full year to have this bug solved?
Generally, I am not the kind of guy that puts pressure on open source projects, but this is so frustrating. The costs of this bug are too high. If the importance is "High", why do I feel that this everything but important? Still hope to see a real solution any time soon.
| Michael (lauwersm) wrote : | #82 |
Hi all,
I've been following this bugreport for the past 6 months since I have the same problem on a backup server.
Running the latest Debian on a Hyper-V host. During the night there are several rsync backups going on. The issue only happens maybe once every 3 or 4 weeks because there's not much load on this server. The filesystem goes in ro mode and it has to be rebooted to get it working again. The same symptoms as have been described here several times...
Since jsalisbury has now a script to create the needed load to reproduce the error within hours, I can always get a separate test VM running with Debian or Ubuntu to test further possible fixes if wanted.
Just thought I'd post this, in the hope that people will continue looking for a solution... There are plenty of people with this problem it seems!
| Dexuan Cui (decui) wrote : | #83 |
Sorry, I was moved to another project so I couldn't debug the issue with full-time.
Hi Joshua R. Poulson (jrp), can you please find more resource for this bug?
My previous debugging made me think the root cause might be in the storvsc driver code, but unluckily I'm not an expert in that area. :-(
Recently there are some storvsc fixes posted in LKML and some of them haven't been accepted in the upstream kernel.
I think I can re-try the bug when all of the recent fixes are in the upstream to see if the situation will change.
| Frederik Bosch (f-bosch) wrote : | #84 |
Thanks @lauwersm and @decui. Our comments seem to have no effect at all. Yesterday was a read-only day again. Just two weeks after the previous one. So now it happens two times a month, which is 2 out of 8 backups. This is just too often, too expensive in labour and really unworkable.
Also, the write latency is extraordinary. Yesterday some data import was busy (over the network) when the backup started. Took more than 3 hours to complete. After backup was finished, I started the import again, just to see the difference. Took just 45 minutes. I would be more than happy to show an engineer our problem.
Maybe someone knows how to soft reboot a machine when in read-only state? This could help reducing the pain. But I really really want to urge getting a final solution. The problem was issued at April 30. My report at the Microsoft forum was at May 8, and that was after 40 days of problems already. So this bugging us for almost 10 months.
| Joshua R. Poulson (jrp) wrote : | #85 |
@f-bosch, @lauwersm, we appreciate your patience. We've looked into storvsc and vss and have been trying to reproduce the problem, and while we seem to have lowered the occurrence of the problem, have not eliminated it.
However, since the last storvsc update, we have fixed a number of issues in the 3.19 and 4.2 kernels. If not for a rushed CVE, those kernels would be GA at this point, but they are going into -proposed for release this weekend.
Since you are on 14.04, I recommend testing on the lts-wily kernels, especially after the update goes out.
# apt-get install --install-
(and reboot)
This will move you to the 4.2 kernel, and after the latest update goes out, you will be running Hyper-V components from the 4.3 upstream kernel.
On the next point release of 14.04, the plan is to switch the recommended kernel to lts-wily anyway, so you are just getting ahead of the rush a little.
| Joshua R. Poulson (jrp) wrote : | #86 |
Just checking, did we pick up
commit a689d2510f188e7
Dexuan had suggested something similar earlier, and it went into wily via 4.2 and the 4.3 rebase.
| Frederik Bosch (f-bosch) wrote : | #87 |
@jrp Could you confirm that if I upgrade my machines today to the wily kernels that there are (probably) many improvements to this issue? At this moment I have the vivid kernels installed.
| Joseph Salisbury (jsalisbury) wrote : | #88 |
Commit a689d2510 was cc'd to stable, but it was not picked up for Vivid yet. It may not get picked up in time before Vivid goes EOL.
I'm going to see if this issues can still be reproduced with the latest 4.5 mainline kernel.
| Joshua R. Poulson (jrp) wrote : | #89 |
@f-bosch A number of storage fixes went into the wily kernels that are not in vivid, so it potentially fixes your problem. We have difficulty reproducing and I'm getting more folks internally to look into this bug as well.
| Frederik Bosch (f-bosch) wrote : | #90 |
@jrp Thanks, then I will upgrade any time soon, great to hear that you have extra people to help solving!
| Frederik Bosch (f-bosch) wrote : | #91 |
Just upgraded to 4.2.0-27-generic #32~14.04.1-Ubuntu SMP Fri Jan 22 15:32:26 UTC 2016 x86_64 x86_64 x86_64 GNU/Linux. Let's see what happens.
| Frederik Bosch (f-bosch) wrote : | #92 |
- mtab and fstab Edit (1.0 KiB, text/plain)
First backup failed immediately. We are noticing two more things.
First, the failed mount of today fails more often than other mounts. It is not the mount of the OS, but a second added disk (mounted in /dev/sdb1). I have attached the output for /etc/mtab and /etc/fstab of the specific machine that failed. Maybe it helps.
Secondly, backups always switch to read-only at almost the same time: near the end of the backup. I cannot say exactly when, but our backups usually take 4 hours. And failures are always (approx) within the last half hour.
| Herman verschooten (herman-j) wrote : Re: [Bug 1470250] [Hyper-V] Ubuntu 14.04.2 LTS Generation 2 SCSI Errors on VSS Based Backups | #93 |
- Schermafbeelding 2016-02-09 om 10.11.01.png Edit (51.1 KiB, image/png; name="Schermafbeelding 2016-02-09 om 10.11.01.png")
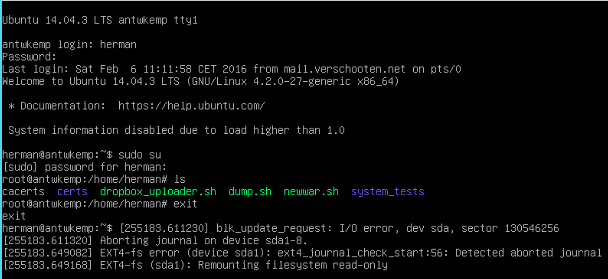{kind=link}
I upgraded a 12.04 LTS to 14.04LTS this weekend and then applied the wily kernel update as mentioned in your mail.
But I had it go read/only again this morning.
[cid:<email address hidden>]
I have attached a screen print, if you need more, please let me know.
Herman
Op 26 jan. 2016, om 19:48 heeft Joshua R. Poulson <<email address hidden>
@f-bosch, @lauwersm, we appreciate your patience. We've looked into
storvsc and vss and have been trying to reproduce the problem, and while
we seem to have lowered the occurrence of the problem, have not
eliminated it.
However, since the last storvsc update, we have fixed a number of issues
in the 3.19 and 4.2 kernels. If not for a rushed CVE, those kernels
would be GA at this point, but they are going into -proposed for release
this weekend.
Since you are on 14.04, I recommend testing on the lts-wily kernels,
especially after the update goes out.
# apt-get install --install-
tools-virtual-
(and reboot)
This will move you to the 4.2 kernel, and after the latest update goes
out, you will be running Hyper-V components from the 4.3 upstream
kernel.
On the next point release of 14.04, the plan is to switch the
recommended kernel to lts-wily anyway, so you are just getting ahead of
the rush a little.
--
You received this bug notification because you are subscribed to the bug
report.
https:/
Title:
[Hyper-V] Ubuntu 14.04.2 LTS Generation 2 SCSI Errors on VSS Based
Backups
Status in linux package in Ubuntu:
In Progress
Status in linux source package in Trusty:
In Progress
Status in linux source package in Vivid:
In Progress
Status in linux source package in Wily:
In Progress
Bug description:
Customers have reported running various versions of Ubuntu 14.04.2 LTS
on Generation 2 Hyper-V Hosts. On a random Basis, the file system
will be mounted Read-Only due to a "disk error" (which really isn't
the case here). As a result, they must reboot the Ubuntu guest to
get the file system to mount RW again.
The Error seen are the following:
Apr 30 00:02:01 balticnetworkst
Apr 30 00:02:01 balticnetworkst
Apr 30 00:02:01 balticnetworkst
Apr 30 01:23:26 balticnetworkst
Apr 30 01:23:26 balticnetworkst
Apr 30 01:23:26 balticnetworkst
Apr 30 01:23:26 balticnetworkst
Apr 30 01:23:26 balticn...
| Frederik Bosch (f-bosch) wrote : | #94 |
@jrp Does it matter to install -virtual packages? I have never done that. Should I?
| Joshua R. Poulson (jrp) wrote : | #95 |
-virtual kernels have less unnecessary device drivers, so they are smaller. You won't miss anything important on Hyper-V by running the virtual kernels.
| Frederik Bosch (f-bosch) wrote : | #96 |
Thanks @jrp. Then the Wily kernel I installed did not help. Should 4.2.0-27 have the patches you were talking about?
| Emsi (trash1-z) wrote : | #97 |
No luck with 4.2.0-27
# uname -a
Linux xxx 4.2.0-27-generic #32-Ubuntu SMP Fri Jan 22 04:49:08 UTC 2016 x86_64 x86_64 x86_64 GNU/Linux
Just got this few days ago:
[Tue Feb 9 00:00:56 2016] sd 2:0:0:0: [storvsc] Sense Key : Unit Attention [current]
[Tue Feb 9 00:00:56 2016] sd 2:0:0:0: [storvsc] Add. Sense: Changed operating definition
[Tue Feb 9 00:00:56 2016] sd 2:0:0:0: Warning! Received an indication that the operating parameters on this target have changed. The Linux SCSI layer does not automa
[Tue Feb 9 00:01:36 2016] sd 2:0:0:0: [storvsc] Sense Key : Unit Attention [current]
[Tue Feb 9 00:01:36 2016] sd 2:0:0:0: [storvsc] Add. Sense: Changed operating definition
[Tue Feb 9 00:01:36 2016] sd 2:0:0:0: Warning! Received an indication that the operating parameters on this target have changed. The Linux SCSI layer does not automa
[Tue Feb 9 00:01:36 2016] blk_update_request: I/O error, dev sda, sector 1075632
[Tue Feb 9 00:01:36 2016] Aborting journal on device sda1-8.
[Tue Feb 9 00:01:36 2016] EXT4-fs error (device sda1): ext4_journal_
[Tue Feb 9 00:01:36 2016] EXT4-fs (sda1): Remounting filesystem read-only
[Wed Feb 10 00:02:49 2016] EXT4-fs (sda1): error count since last fsck: 2
[Wed Feb 10 00:02:49 2016] EXT4-fs (sda1): initial error at time 1454972496: ext4_journal_
[Wed Feb 10 00:02:49 2016] EXT4-fs (sda1): last error at time 1454972496: ext4_journal_
[Thu Feb 11 00:04:37 2016] EXT4-fs (sda1): error count since last fsck: 2
[Thu Feb 11 00:04:37 2016] EXT4-fs (sda1): initial error at time 1454972496: ext4_journal_
[Thu Feb 11 00:04:37 2016] EXT4-fs (sda1): last error at time 1454972496: ext4_journal_
[Fri Feb 12 00:06:24 2016] EXT4-fs (sda1): error count since last fsck: 2
[Fri Feb 12 00:06:24 2016] EXT4-fs (sda1): initial error at time 1454972496: ext4_journal_
[Fri Feb 12 00:06:24 2016] EXT4-fs (sda1): last error at time 1454972496: ext4_journal_
I ended with completely corrupted fs. fsck ended in all files in lost+found and garbled filenames.
| Frederik Bosch (f-bosch) wrote : | #98 |
@trash1-z Completely corrupted fs? That is not good. How long are you chasing this bug? Was everything ok (except for the read-only problems) before the upgrade to 4.2.0-27? Because, then I might downgrade my OS to 3.19 which was working fine.
| Frederik Bosch (f-bosch) wrote : | #99 |
@trash1-z Was it still corrupted after the reboot?
| Emsi (trash1-z) wrote : | #100 |
Actually I got this on 3 VMs on my Azure Pack. One 15.10 and two 14.04.03.
On 15.10 I tried to fsck the root fs before reboot. What could go wrong as fs is already read-only I thought.
Here is the session:
~# touch /oioi
touch: cannot touch '/oioi': Read-only file system
~# fsck / <--- At this point it corrupted everything already.
fsck from util-linux 2.26.2
e2fsck 1.42.12 (29-Aug-2014)
cloudimg-rootfs: recovering journal
fsck.ext4: Bad magic number in super-block while trying to re-open cloudimg-rootfs
cloudimg-rootfs: ********** WARNING: Filesystem still has errors **********
~# fsck -f /
fsck from util-linux 2.26.2
fsck.ext4: Unable to resolve 'UUID=5370f2f3-
~# ls -la /
total 0
After reboot grub said it cannot find FS so I booted it from another HDD and fcsked from that. It reported a lot of errors but rendered the FS as explained before - everything in lost+found.
On 14.04 I rebooted without fsck. After boot it said that FS i corrupted so I can Skip mounting it (what root?) or try Manualy fix it. So I pressed the M but it looked like it's frozen.
Luckily I restored all VMs from the backup. Yes, the very same backup that actually triggered the issue as we found it's 100% correlated that the corruption happens when the backup job starts on HV.
| Joshua R. Poulson (jrp) wrote : | #101 |
@f-bosch Yes, 4.2.0-27 is up to date with upstream linux-next Hyper-V support up to the GA 4.3 kernel. We will continue to investigate.
| Christoffer (christoffer-b) wrote : | #102 |
I have same error with Ubuntu 14.04 LTS (3.19) on Hyper-V 2012 R2 Generation 1 VM. I have now upgrade to 4.2.0-27 and will see if the server have same error.
I used "apt-get install --install-
| Frederik Bosch (f-bosch) wrote : | #103 |
Upgrading the kernel does not help this issue. Moreover, the upgrade gives new issues. For the third time now, the network of one of the Ubuntu VMs suddenly goes down. As so it seems. There is nothing in /var/log/syslog that indicates that the VM has a problem. It is continuing its work. But from the outside the VM is unreachable. This was a problem we never had before the upgrade. There were no significant other changes. I am downgrading my machines back to Vivid.
| Anders Sandblad (arune) wrote : | #104 |
We upgrade all our machines to Wily kernel over a week ago and no issues so far. Less clutter in the logs also due to newer integration services.
Make sure you installed the packages linux-tools-
| Frederik Bosch (f-bosch) wrote : | #105 |
- sudo dpkg -l |grep linux-* Edit (2.3 KiB, text/plain)
@arune See attached my list of installed packages. That is correct, right? My running kernel is (uname -a) Linux VPS-Web-
[hv_vmbus_con]
/usr/lib/
/usr/lib/
/usr/lib/
That should be correct, right?
| Anders Sandblad (arune) wrote : | #106 |
That should be correct (I'm no expert though).
| Emsi (trash1-z) wrote : | #107 |
@F-Bosch: Regarding the link going down I experienced that too. I correlated it with IPv6. When I disabled IPv6 on the interface the problem went away. Previously the more data I sent over ipv6 the sooner it broke. No logs whatsoever. Migrating the machine to another host restored the connectivity without rebooting the guest.
| Frederik Bosch (f-bosch) wrote : | #108 |
@trash1-z, thanks just disabled it. let's see what happens.
| Frederik Bosch (f-bosch) wrote : | #109 |
Just discovered in the CHANGELOG (http://
| Emsi (trash1-z) wrote : | #110 |
I'm on the following since Feb 20:
Linux XXX-Linux 4.2.0-30-generic #35-Ubuntu SMP Fri Feb 19 13:52:26
It still reports Add. Sense:
[Wed Feb 24 00:01:01 2016] sd 2:0:0:0: [storvsc] Sense Key : Unit Attention [current]
[Wed Feb 24 00:01:01 2016] sd 2:0:0:0: [storvsc] Add. Sense: Changed operating definition
[Wed Feb 24 00:01:01 2016] sd 2:0:0:0: Warning! Received an indication that the operating parameters on this target have changed. The Linux SCSI layer does not automa
[Wed Feb 24 00:01:31 2016] sd 2:0:0:0: [storvsc] Sense Key : Unit Attention [current]
[Wed Feb 24 00:01:31 2016] sd 2:0:0:0: [storvsc] Add. Sense: Changed operating definition
[Wed Feb 24 00:01:31 2016] sd 2:0:0:0: Warning! Received an indication that the operating parameters on this target have changed. The Linux SCSI layer does not automa
On the other hand I experienced the very same crash on Debian with 4.3.0-0.
| Frederik Bosch (f-bosch) wrote : | #111 |
@trash1-z Earlier reports indicate that that is not an error. The message is benign.
| Herman verschooten (herman-j) wrote : | #112 |
I get the following error when trying to install the wily kernel.
apt-get install --install-
Pakketlijsten worden ingelezen... Klaar
Boom van vereisten wordt opgebouwd
De status informatie wordt gelezen... Klaar
De volgende extra pakketten zullen geïnstalleerd worden:
linux-
linux-
linux-
De volgende NIEUWE pakketten zullen geïnstalleerd worden:
linux-
linux-
linux-
linux-
linux-
0 pakketten opgewaardeerd, 9 pakketten nieuw geïnstalleerd, 0 te verwijderen en 0 niet opgewaardeerd.
Er moeten 0 B/75,2 kB aan archieven opgehaald worden.
Door deze operatie zal er 886 kB extra schijfruimte gebruikt worden.
Wilt u doorgaan? [J/n] j
Selecting previously unselected package linux-cloud-
(Database inlezen ... 128801 files and directories currently installed.)
Preparing to unpack .../linux-
Unpacking linux-cloud-
Selecting previously unselected package linux-lts-
Preparing to unpack .../linux-
Unpacking linux-lts-
Selecting previously unselected package linux-cloud-
Preparing to unpack .../linux-
Unpacking linux-cloud-
Selecting previously unselected package linux-cloud-
Preparing to unpack .../linux-
Unpacking linux-cloud-
Selecting previously unselected package linux-headers-
Preparing to unpack .../linux-
Unpacking linux-headers-
Selecting previously unselected package linux-headers-
Preparing to unpack .../linux-
Unpacking linux-headers-
Selecting previously unselected package linux-image-
Preparing to unpack .../linux-
Unpacking linux-image-
Selecting previously unselected package linux-tools-
Preparing to unpack .../linux-
Unpacking linux-tools-
Selecting previously unselected package linux-virtual-
Preparing to unpack .../linux-
Unpacking linux-virtual-
...
| Emsi (trash1-z) wrote : | #113 |
@f-bosch: The message is an early warning. Even on the latest 4.2.0-30 it just forecasts the imminent failure:
[Sat Feb 27 00:01:08 2016] sd 2:0:0:0: [storvsc] Sense Key : Unit Attention [current]
[Sat Feb 27 00:01:08 2016] sd 2:0:0:0: [storvsc] Add. Sense: Changed operating definition
[Sat Feb 27 00:01:08 2016] sd 2:0:0:0: Warning! Received an indication that the operating parameters on this target have changed. The Linux SCSI layer does not automa
[Sat Feb 27 00:01:48 2016] sd 2:0:0:0: [storvsc] Sense Key : Unit Attention [current]
[Sat Feb 27 00:01:48 2016] sd 2:0:0:0: [storvsc] Add. Sense: Changed operating definition
[Sat Feb 27 00:01:48 2016] sd 2:0:0:0: Warning! Received an indication that the operating parameters on this target have changed. The Linux SCSI layer does not automa
[Sat Feb 27 00:01:48 2016] blk_update_request: I/O error, dev sda, sector 1058512
[Sat Feb 27 00:01:48 2016] Aborting journal on device sda1-8.
[Sat Feb 27 00:01:50 2016] EXT4-fs error (device sda1): ext4_journal_
[Sat Feb 27 00:01:50 2016] EXT4-fs (sda1): Remounting filesystem read-only
[Sun Feb 28 00:06:47 2016] EXT4-fs (sda1): error count since last fsck: 2
[Sun Feb 28 00:06:47 2016] EXT4-fs (sda1): initial error at time 1456527709: ext4_journal_
[Sun Feb 28 00:06:47 2016] EXT4-fs (sda1): last error at time 1456527710: ext4_journal_
[Mon Feb 29 00:08:35 2016] EXT4-fs (sda1): error count since last fsck: 2
[Mon Feb 29 00:08:35 2016] EXT4-fs (sda1): initial error at time 1456527709: ext4_journal_
[Mon Feb 29 00:08:35 2016] EXT4-fs (sda1): last error at time 1456527710: ext4_journal_
[Mon Feb 29 09:56:24 2016] sd 2:0:0:0: [storvsc] Sense Key : Unit Attention [current]
[Mon Feb 29 09:56:24 2016] sd 2:0:0:0: [storvsc] Add. Sense: Changed operating definition
[Mon Feb 29 09:56:24 2016] sd 2:0:0:0: Warning! Received an indication that the operating parameters on this target have changed. The Linux SCSI layer does not automa
# uname -a
Linux xxx-Linux 4.2.0-30-generic #35-Ubuntu SMP Fri Feb 19 13:52:26 UTC 2016 x86_64 x86_64 x86_64 GNU/Linux
| Frederik Bosch (f-bosch) wrote : | #114 |
@trash1-z I also see that message when a backup succeeds. Just like I see it when a backup fails.
| Joshua R. Poulson (jrp) wrote : | #115 |
A few more upstream commits to make sure are present:
drivers/hv/
2d0c3b5a... "hv: utils: Invoke the poll function after handshake" (could be the smoking gun here)
ed9ba608... "hv: vss: run only on support host versions" (I think we got this one in another bug)
3cace4a61... "hv: utils: run polling callback always in interrupt context" (We probably got this one as a prereq)
| Joshua R. Poulson (jrp) wrote : | #116 |
That's drivers/
| Alex Ng (alexng-v) wrote : | #117 |
In addition to what @jrp mentioned, I would also add:
b9830d120cbe155
| Frederik Bosch (f-bosch) wrote : | #118 |
@jrp @alexng-v Great that we have more improvements! Were you already able to to not see any more crashes during backup while using the script created by @jsalisbury?
| Joseph Salisbury (jsalisbury) wrote : | #119 |
Xenial already contains the three commits Josh posted in comment #115.
I built a Xenial test kernel with commit b9830d120, which was mentioned in commet #117. This test kernel can be downloaded from:
http://
I'll also test this kernel in my environment. If these commits fix the but, I'll submit them all for SRU.
| Frederik Bosch (f-bosch) wrote : | #120 |
@jsalisbury That is great, thanks. Now I can go testing for sure, but I think the first confirmation we need is that there is no more crash when your script to reproduce the issue is used.
Maybe @jrp can tell us what the reason why he thinks they found the smoking gun. If he can indeed confirm there is no more issue with the script, then I will go testing the build kernels.
| Alex Ng (alexng-v) wrote : | #121 |
While we're not completely certain this is the smoking gun, I've observed that in the logs being posted here that there are no freeze/thaw operations taking place when the issue occurs. The commits that @jrp identified, fix messaging between the VSS utility driver and the host; and will hopefully ensure expected freeze/thawing of the filesystem during backup.
In our internal testing with the latest Linux-next kernel (which contains these commits) we were unable to hit this issue using scripts from @jsalisbury.
We look forward to hearing back from the testing.
| Frederik Bosch (f-bosch) wrote : | #122 |
@alexng-v Thanks for the quick reply: that sounds good! I will let you know what our experiences are.
| Joseph Salisbury (jsalisbury) wrote : | #123 |
I am also in the process of testing now. I will post an update with my results.
| Joseph Salisbury (jsalisbury) wrote : | #124 |
The test kernel is looking promising so far. The reproducer has been running for six hours now. I'll let it run for a few days to ensure the bug does not return.
| Joseph Salisbury (jsalisbury) wrote : | #125 |
Unfortunately the file system went read only again. It took much longer this time, around 9 hours.
| Joseph Salisbury (jsalisbury) wrote : | #126 |
I'll perform the same testing with the latest Linux-next kernel.
| Emsi (trash1-z) wrote : | #127 |
Lo luck here :( Even though I have the hv_vss_daemon that logs FREEZE/THAW I experienced crashes:
Mar 15 10:36:38 emsi-02 Hyper-V VSS: VSS: op=FREEZE: succeeded
Mar 15 10:36:38 emsi-02 kernel: [320343.560935] sd 2:0:0:0: [storvsc] Sense Key : Unit Attention [current]
Mar 15 10:36:38 emsi-02 kernel: [320343.560949] sd 2:0:0:0: [storvsc] Add. Sense: Changed operating definition
Mar 15 10:36:38 emsi-02 kernel: [320343.560958] sd 2:0:0:0: Warning! Received an indication that the operating parameters on this target have changed. The Linux SCSI layer does not automatically adjust these parameters.
Mar 15 10:36:38 emsi-02 Hyper-V VSS: VSS: op=THAW: succeeded
Mar 15 10:37:08 emsi-02 kernel: [320373.536208] sd 2:0:0:0: [storvsc] Sense Key : Unit Attention [current]
Mar 15 10:37:08 emsi-02 kernel: [320373.536222] sd 2:0:0:0: [storvsc] Add. Sense: Changed operating definition
Mar 15 10:37:08 emsi-02 kernel: [320373.536287] sd 2:0:0:0: Warning! Received an indication that the operating parameters on thi
and then later on:
[Wed Mar 16 10:06:45 2016] sd 2:0:0:0: [storvsc] Sense Key : Unit Attention [current]
[Wed Mar 16 10:06:45 2016] sd 2:0:0:0: [storvsc] Add. Sense: Changed operating definition
[Wed Mar 16 10:06:45 2016] sd 2:0:0:0: Warning! Received an indication that the operating parameters on this target have changed. The Linux SCSI layer does not automatically adjust these parameters.
[Wed Mar 16 10:08:12 2016] sd 2:0:0:0: [storvsc] Sense Key : Unit Attention [current]
[Wed Mar 16 10:08:12 2016] sd 2:0:0:0: [storvsc] Add. Sense: Changed operating definition
[Wed Mar 16 10:08:12 2016] sd 2:0:0:0: Warning! Received an indication that the operating parameters on this target have changed. The Linux SCSI layer does not automatically adjust these parameters.
[Wed Mar 16 10:08:12 2016] blk_update_request: I/O error, dev sda, sector 1061736
[Wed Mar 16 10:08:12 2016] Aborting journal on device sda1-8.
[Wed Mar 16 10:08:12 2016] EXT4-fs error (device sda1): ext4_journal_
[Wed Mar 16 10:08:12 2016] EXT4-fs error (device sda1): ext4_journal_
[Wed Mar 16 10:08:12 2016] EXT4-fs (sda1): Remounting filesystem read-only
[Wed Mar 16 10:08:12 2016] EXT4-fs error (device sda1): ext4_journal_
[Wed Mar 16 10:08:12 2016] EXT4-fs error (device sda1): ext4_journal_
[Wed Mar 16 10:08:12 2016] Detected aborted journal
[Wed Mar 16 10:08:12 2016] EXT4-fs error (device sda1) in ext4_writepages
| Emsi (trash1-z) wrote : | #128 |
I also found someone reporting the issue on RedHat:
https:/
From my tests it looked like Centos kernels are not affected but above report casts some shadow on that assumption. It might be that the buggy code was integrated into RH kernels as well.
| Emsi (trash1-z) wrote : | #129 |
It looks like there is a race condition and the corruption occurs when the FREEZE happens to late. No wonder as it's happening from userland.
Mar 16 15:06:49 emsi-02 kernel: [422953.038989] sd 2:0:0:0: [storvsc] Sense Key : Unit Attention [current]
Mar 16 15:06:49 emsi-02 kernel: [422953.039003] sd 2:0:0:0: [storvsc] Add. Sense: Changed operating definition
Mar 16 15:06:49 emsi-02 kernel: [422953.039058] sd 2:0:0:0: Warning! Received an indication that the operating parameters on this target have changed. The Linux SCSI layer does not automatically adjust these parameters.
Mar 16 15:06:49 emsi-02 kernel: [422953.039063] blk_update_request: I/O error, dev sda, sector 0
Mar 16 15:06:49 emsi-02 Hyper-V VSS: VSS: op=FREEZE: succeeded
Mar 16 15:06:49 emsi-02 kernel: [422953.072223] sd 2:0:0:0: [storvsc] Sense Key : Unit Attention [current]
Mar 16 15:06:49 emsi-02 kernel: [422953.072235] sd 2:0:0:0: [storvsc] Add. Sense: Changed operating definition
Mar 16 15:06:49 emsi-02 kernel: [422953.072242] sd 2:0:0:0: Warning! Received an indication that the operating parameters on this target have changed. The Linux SCSI layer does not automatically adjust these parameters.
Mar 16 15:06:49 emsi-02 Hyper-V VSS: VSS: op=THAW: succeeded
| Joseph Salisbury (jsalisbury) wrote : | #130 |
In comment #125, I was testing the four suggested patches against Xenial. I'll also test them against Wily and post an update. Then I'll test the upstream -next kernel.
| Joseph Salisbury (jsalisbury) wrote : | #131 |
I built a Wily test kernel with the four requested patches.
This test kernel can be downloaded from:
http://
I' m testing this kernel now and will report back with results.
| Joseph Salisbury (jsalisbury) wrote : | #132 |
The Wily test kernel is still under test. I also built a Xenial test kernel with all the Hyper-V patches currently in upstream linux-next. I will test that kernel next, but if others want to test it, it is available from:
http://
| Joseph Salisbury (jsalisbury) wrote : | #133 |
Unfortunately the file system went read only again while testing the Wily test kernel with the four patches. I will test the linux-next test kernel, which includes all patches for upstream linux-next.
| Joseph Salisbury (jsalisbury) wrote : | #134 |
Testing of the upstream -next kernel also resulted in the filesystem going read only.
| Alex Ng (alexng-v) wrote : | #135 |
Thanks for testing this.
We will continue looking at this internally. It's possible that the issue's with the storage drivers.
| Emsi (trash1-z) wrote : | #136 |
It's a regression. Anyone knows the last working kernel version?
It might be easier to find the breaking change.
| Frederik Bosch (f-bosch) wrote : | #137 |
@trash1-z No, I believe that was never posted. Though we do know people with 12.04 were hit too. However, I did post the version of my CentOS machine that was never hit by the bug (to date), while all my Ubuntu were hit frequently. I started with kernel 3.13. The kernel version of this CentOS machine was (and still is): 3.10.0-
| Joseph Salisbury (jsalisbury) wrote : | #138 |
@Frederik Bosch, thanks for the reminder. This issue has not been seen on CentOS based on the 3.10 kernel. However, it has been seen on 12.04(Precise), which is based on the 3.2 kernel. That might indicate that the issue is not in the kernel bits, but maybe in the VSS bits. Are you using the same Windows 2012 R2 server to perform the backups? Is the version of the hv_vss daemon the same on CentoOS where you don't see the issue and on Ubuntu where you do see this bug?
| Frederik Bosch (f-bosch) wrote : | #139 |
@jsalisbury The Windows Version is the same. Regarding the hv_vss_daemon I am using the latest recommended version of the operating system. For Ubuntu that means I am installing tools and cloud tools. For CentOS I am using hypervvssd.x86_64 0-0.26.
| Joseph Salisbury (jsalisbury) wrote : | #140 |
I setup a CentOS 7 VM and have the reproducer script running on it now. We should know if CentOS with the 3.10 kernel also exhibits this bug shortly.
| Joshua R. Poulson (jrp) wrote : | #141 |
If testing on CentOS, it would be interesting to see if there's a reproduction with LIS 4.0.11 or 4.1 (just released) which are much closer in VSS bits to the Ubuntu versions than the CentOS built-in LIS.
| Joseph Salisbury (jsalisbury) wrote : | #142 |
I've been running the test script on CentOS 7 now for almost 20 hours. I can usually reproduce the bug in 8-9 hours, so it may be safe to say the bug cannot be reproduced with CentOS 7.
I'm going to let the test run for a couple more hours, then I'll try the other LIS versions suggested by Josh.
| Joseph Salisbury (jsalisbury) wrote : | #143 |
I tested CentOS 7 with LIS 4.0.11 overnight, and it also did not exhibit the bug. I will test LIS 4.1 next.
| Joseph Salisbury (jsalisbury) wrote : | #144 |
I tested CentOS 7 with LIS 4.1 over the weekend, and it also did not exhibit the bug. This might indicate a regression introduced after the v3.10 kernel, or maybe that CentOS 7 has a distro specific fix that is not in Ubuntu yet.
I'll try some newer kernels on CentOS and some older kernels on Ubuntu to try to narrow this down further.
| Frederik Bosch (f-bosch) wrote : | #145 |
@jsalisbury Thanks for the work already. It's good new information to have. We are getting closer with finding the exact cause of the issue. I am sure we will find it any time soon now!
| Emsi (trash1-z) wrote : | #146 |
Now I got much more verbose error:
[Wed Mar 30 11:38:59 2016] NMI watchdog: BUG: soft lockup - CPU#1 stuck for 25s! [init:1321]
[Wed Mar 30 11:38:59 2016] Modules linked in: btrfs(E) xor(E) raid6_pq(E) ufs(E) qnx4(E) hfsplus(E) hfs(E) minix(E) ntfs(E) msdos(E) jfs(E) xfs(E) libcrc32c(E) xt_nat xt_tcpudp veth xt_conntrack ipt_MASQUERADE nf_nat_
[Wed Mar 30 11:38:59 2016] CPU: 1 PID: 1321 Comm: init Tainted: G E 4.2.0-30-generic #35-Ubuntu
[Wed Mar 30 11:38:59 2016] Hardware name: Microsoft Corporation Virtual Machine/Virtual Machine, BIOS 090006 05/23/2012
[Wed Mar 30 11:38:59 2016] task: ffff88003585b700 ti: ffff8800f3bb0000 task.ti: ffff8800f3bb0000
[Wed Mar 30 11:38:59 2016] RIP: 0010:[<
[Wed Mar 30 11:38:59 2016] RSP: 0018:ffff880102
[Wed Mar 30 11:38:59 2016] RAX: 00000000ffffffff RBX: 0000000000000000 RCX: 00000000ffffffff
[Wed Mar 30 11:38:59 2016] RDX: ffff8800ee0ea400 RSI: 0000000000000020 RDI: ffff8800f08221c0
[Wed Mar 30 11:38:59 2016] RBP: ffff880102643c18 R08: 00000000000003c0 R09: ffff8800ee0ea400
[Wed Mar 30 11:38:59 2016] R10: 0000000000000003 R11: 0000000000000004 R12: ffff880102643b78
[Wed Mar 30 11:38:59 2016] R13: ffffffff817f4a9b R14: ffff880102643c18 R15: 0000000000000600
[Wed Mar 30 11:38:59 2016] FS: 00007ffa15ff980
[Wed Mar 30 11:38:59 2016] CS: 0010 DS: 0000 ES: 0000 CR0: 0000000080050033
[Wed Mar 30 11:38:59 2016] CR2: 00007f1407ee4000 CR3: 0000000035929000 CR4: 00000000001406e0
[Wed Mar 30 11:38:59 2016] Stack:
[Wed Mar 30 11:38:59 2016] 0000000000000500 ffff88010115c000 ffff880102643c58 ffffffff816d7615
[Wed Mar 30 11:38:59 2016] 00000000000003ff ffff88010115c000 ffff880102643d38 ffffc90001b70c78
[Wed Mar 30 11:38:59 2016] ffff880035158400 ffff880102660a48 ffff880102643ca8 ffffffffc012fbae
[Wed Mar 30 11:38:59 2016] Call Trace:
[Wed Mar 30 11:38:59 2016] <IRQ>
[Wed Mar 30 11:38:59 2016] [<ffffffff816d7
[Wed Mar 30 11:38:59 2016] [<ffffffffc012f
[Wed Mar 30 11:38:59 2016] [<ffffffffc0131
[Wed Mar 30 11:38:59 2016] [<ffffffffc001e
[Wed Mar 30 11:38:59 2016] [<ffffffffc012f
[Wed Mar 30 11:38:59 2016] [<ffffffffc001d
[Wed Mar 30 11:38:59 2016] [<ffffffffc0130
[Wed Mar 30 11:38:59 2016] [<ffffffff810ab
[Wed Mar 30 11:38:59 2016] [<f...
| Joseph Salisbury (jsalisbury) wrote : | #147 |
I have some promising news. I've been going through and building/testing some older Ubuntu kernels. I think I found the last version that does not exhibit the bug: 3.13.0-16.36
I've been testing it for 12 hours without hitting the bug. I'll test it for a little while longer to be sure it's good. If it is, I'll start a kernel bisect and identify the offending commit. I see a couple that stick out in the git log, but more testing is needed.
I'll post additional updates shortly.
| Joseph Salisbury (jsalisbury) wrote : | #148 |
The 3.13.0-17 kernel ran for 24 hours without hitting the bug. We know that the 3.13.0-49 kernel exhibits the bug. So my next test will be with the 3.13.0-32.56 kernel to try and narrow down the version further.
| Joseph Salisbury (jsalisbury) wrote : | #149 |
I actually just tested the 3.13.0-35 kernel and not -32. It DID exhibit the bug. I'll next test the 3.13.0-26 kernel. Current results are:
3.13.0-16 - GOOD
3.13.0-17 - GOOD
3.13.0-26 - TESTING NEXT
3.13.0-35 - BAD
3.13.0-49 - BAD
| Emsi (trash1-z) wrote : | #150 |
Which ubuntu version are you using for tests? 14.04? How about vss daemon, kvp daemon? Have you installed them? Which version and package have you used? Are you using crash consistent or application consistent backups (with VSS support in the Guest Linux)?
I'd like to independently repeat your tests to confirm the results yet I need to replicate your environment.
| Joseph Salisbury (jsalisbury) wrote : | #151 |
I'm using a Wily 15.10 Gen2 guest has the base OS. The vss/kvp daemon are the versions that come in linux-tools and packed for that particular kernel being tested.
To test a particular kernel, you need to go to the Launchpad download page for a particular version/arch. Then download an install four .deb packages for that kernel. With dpkg -i from a termina, install the linux-image, linux-image-extra, linux-tools and linux-tools-generic .deb packages.
For example to test 3.13.0-17, I went to the URL:
https:/
Then downloaded these four .deb packages:
1. linux-image-
2. linux-image-
3. linux-tools-
4. linux-tools-
All of the Trusty kernels are available for download from:
https:/
You just need to select a particular version, then select the architecture on the next page, under 'Builds'.
| Joseph Salisbury (jsalisbury) wrote : | #152 |
3.13.0-26 is Good, testing 3.13.0-30 next.
| Alex Ng (alexng-v) wrote : | #153 |
Thanks for going through this testing.
Based on your results, I looked at the Hyper-V related commits in http://
From reviewing these commits, there doesn't seem to be an obvious culprit. But it's possible that anyone of the following could affect storage driver behavior. Looking forward to seeing what you uncover in your bisect.
- a61e9104ea3b183
- c8c38b34f579036
| Joseph Salisbury (jsalisbury) wrote : | #154 |
I'll continue to provide updates. Sorry the bisect is taking a long time. It requires at least 8 hours of testing for each test kernel, to be sure it does not have the bug.
On a positive not, when a kernel is bad, it usually fails within two hours, which allows me to kick off the next test quicker. However, I'd just rather not assume a kernel is good if it runs for longer than two hours.
| Dominik (dominik.) wrote : | #155 |
Take your time. I'm incredibly thankful that somebody is taking care of this. This bug already cost me a substantial amount of time and so far I found no way of fixing it (except using an old kernel).
| Joseph Salisbury (jsalisbury) wrote : | #156 |
3.13.0-30 - GOOD, testing 3.13.0-32 next.
| Joseph Salisbury (jsalisbury) wrote : | #157 |
3.13.0-32 is good after 15 hours. I'm going to let it run 24 hours to be sure, since it's the weekend. We're getting closer.
| Joseph Salisbury (jsalisbury) wrote : | #158 |
3.13.0-32 - GOOD, testing 3.13.0-34 next.
Current test results:
3.13.0-16 - GOOD
3.13.0-17 - GOOD
3.13.0-26 - GOOD
3.13.0-30 - GOOD
3.13.0-32 - GOOD
3.13.0-34 - TESTING
3.13.0-35 - BAD
3.13.0-49 - BAD
| Joseph Salisbury (jsalisbury) wrote : | #159 |
I tested 3.13.0-34 for 24 hours and it did not exhibit the bug. This would indicate the bug was introduce between -34 and -35. There are only three commits between these two versions:
c8c38b3 Drivers: hv: vmbus: Fix a bug in the channel callback dispatch code
7af024a hv: use correct order when freeing monitor_pages
6ad4874 Drivers: hv: balloon: Ensure pressure reports are posted regularly
None are storage specific and stick out as the cause. It could have possible been caused by either of the connection commits. I think the only way to be sure is to bisect between -34 and -35 specifically against the drivers/hv directory. This would only require two bisect tests, then a final test with the suspect commit reverted. I'll do this next and post the results.
| Joseph Salisbury (jsalisbury) wrote : | #160 |
Commit 6ad4874 is good. Now testing commit 7af024a.
| Alex Ng (alexng-v) wrote : | #161 |
Thanks for the update @jsalisbury.
7af024a isn't likely to be the cause, as that commit only changes behavior during VMBus shutdown (i.e. when we cleanup VMBus during guest shutdown).
This leads me to think that commit c8c38b3 is more likely to be a factor. Nonetheless, I'll withhold further comment until we see results from testing commit 7af024a.
| Joseph Salisbury (jsalisbury) wrote : | #162 |
Hi Alex,
Indeed, commit 7af024a did not hit the bug. I'm testing up to commit c8c38b3 now. It's the last change in drivers/hv, so it should be the commit that introduced the regression.
If it does not hit the bug, I'll have to bisect further up the tree.
| Changed in linux (Ubuntu Xenial): | |
| importance: | High → Critical |
| Joseph Salisbury (jsalisbury) wrote : | #163 |
Interesting, it looks like commit c8c38b3 is good as well. I'm going to have to bisect outside of drivers/hv.
| Joseph Salisbury (jsalisbury) wrote : | #164 |
I also see a few virtio changes between -34 and -35:
4c56763 virtio-scsi: fix various bad behavior on aborted requests
2a821e5 virtio-scsi: avoid cancelling uninitialized work items
3c50c21 block: virtio_blk: don't hold spin lock during world switch
I'm going to perform a full bisect against all changes to be sure we find the correct commit that caused this. In parallel, I'll build and test a kernel with those prior 3 commits reverted as a quick test.
| Joseph Salisbury (jsalisbury) wrote : | #165 |
I tested a test kernel with a revert of the three commits listed in comment #164. The test failed within an hour, so none of those commits caused the regression.
I'm starting a full bisect at this point and should have results over the next couple of days.
| Joseph Salisbury (jsalisbury) wrote : | #166 |
Current status of bisect:
0a985c5524 GOOD
4c48c359ba GOOD
5044635f00 BAD
00a5771c11 TESTING
About five more test kernels to go.
| Alex Ng (alexng-v) wrote : | #167 |
Hi Joseph,
Any updates on the bisect?
| Joseph Salisbury (jsalisbury) wrote : | #168 |
Yes, the bisect ended in a really strange results. I reported this commit as the cause:
commit c01fac1c77a0022
Author: Felix Fietkau <email address hidden>
Date: Wed Jul 23 15:40:54 2014 +0200
ath9k: fix aggregation session lockup
I'm not really sure how a wireless driver could cause this. Even stranger is I build a 3.13.0-35 kernel with this commit reverted, and I'm unable to reproduce the bug. If anyone else wants to test that kernel, it can be downloaded from:
http://
I'm now testing Wily and Xenial kernels with the commit reverted as well to ensure a revert fixes those kernels as well.
If anyone else wants to test those kernels, then can be downloaded from:
Trusty: http://
WIly: http://
Xenial: http://
If that commit is indeed the cause of the bug, we should do some more investigation to understand what is happening. I'll post my testing results of the other kernels within two days.
| Alex Ng (alexng-v) wrote : | #169 |
I'm also going to try reverting this commit on a 4.2.0-27 kernel that I was able to see this issue on; and see if I can repro it there as well.
| Joseph Salisbury (jsalisbury) wrote : | #170 |
If it fixes the issue for you, well I'll be even more blown away.
| Frederik Bosch (f-bosch) wrote : | #171 |
For the information, this is the commit https:/
| Joakim Plate (elupus) wrote : Re: [Bug 1470250] Re: [Hyper-V] Ubuntu 14.04.2 LTS Generation 2 SCSI Errors on VSS Based Backups | #172 |
If it indeed is the triggering commit. Comparing two memory map file for
the kernel with and without the commit, could show off its a compilation
issue.
On Apr 14, 2016 09:21, "Frederik Bosch" <email address hidden> wrote:
> For the information, this is the commit
>
> https:/
> .
> It would indeed make no sense at all when this would cause the thing.
> How would the backup procedure even touch those lines of code?
>
> --
> You received this bug notification because you are subscribed to the bug
> report.
> https:/
>
> Title:
> [Hyper-V] Ubuntu 14.04.2 LTS Generation 2 SCSI Errors on VSS Based
> Backups
>
> Status in linux package in Ubuntu:
> In Progress
> Status in linux source package in Trusty:
> In Progress
> Status in linux source package in Vivid:
> In Progress
> Status in linux source package in Wily:
> In Progress
> Status in linux source package in Xenial:
> In Progress
>
> Bug description:
> Customers have reported running various versions of Ubuntu 14.04.2 LTS
> on Generation 2 Hyper-V Hosts. On a random Basis, the file system
> will be mounted Read-Only due to a "disk error" (which really isn't
> the case here). As a result, they must reboot the Ubuntu guest to
> get the file system to mount RW again.
>
> The Error seen are the following:
> Apr 30 00:02:01 balticnetworkst
> Sense Key : Unit Attention [current]
> Apr 30 00:02:01 balticnetworkst
> Add. Sense: Changed operating definition
> Apr 30 00:02:01 balticnetworkst
> 0:0:0:0: Warning! Received an indication that the operating parameters on
> this target have changed. The Linux SCSI layer does not automatically
> adjust these parameters.
> Apr 30 01:23:26 balticnetworkst
> hv_storvsc vmbus_0_4: cmd 0x2a scsi status 0x2 srb status 0x82
> Apr 30 01:23:26 balticnetworkst
> hv_storvsc vmbus_0_4: stor pkt ffff88006eb6c700 autosense data valid - len
> 18
> Apr 30 01:23:26 balticnetworkst
> Sense Key : Unit Attention [current]
> Apr 30 01:23:26 balticnetworkst
> Add. Sense: Changed operating definition
> Apr 30 01:23:26 balticnetworkst
> 0:0:0:0: Warning! Received an indication that the operating parameters on
> this target have changed. The Linux SCSI layer does not automatically
> adjust these parameters.
>
> This relates to the VSS "Windows Server Backup" process that kicks off
> at midnight on the host and finishes an hour and half later.
> Yes, we do have hv_vss_daemon and hv_kvp_daemon running for the correct
> kernel version we have. We're currently running kernel version
> 3.13.0-49-generic #83 on one system and 3.16.0-34-generic #37 on the other.
> -- We see the same errors on both.
> As a result, we've been hesitant to drop any more ubuntu guests on our
> 2012R2 hyper-v system because of this. We can stop the backup process and
> ...
| Emsi (trash1-z) wrote : | #173 |
Bad news.
I tried to replicate the test results on my own.
I downloaded and installed the first kernel marked as good:
# uname -a
Linux backup-01 3.13.0-32-generic #57-Ubuntu SMP Tue Jul 15 03:51:08 UTC 2014 x86_64 x86_64 x86_64 GNU/Linux
I performed the tiobench and simultaneity the backup.
At first it looked like the is no corruption as nothing worrying was reported in the dmesg. Unfortunately the OS behavior indicates that the there is at least memory corruption:
root@backup-01:~# dpkg-reconfigure --frontend noninteractive tzdata
Can't load '/usr/lib/
at /usr/lib/
Compilation failed in require at /usr/lib/
BEGIN failed--compilation aborted at /usr/lib/
Compilation failed in require at /usr/lib/
BEGIN failed--compilation aborted at /usr/lib/
Compilation failed in require at /usr/lib/
BEGIN failed--compilation aborted at /usr/lib/
Compilation failed in require at /usr/share/
Compilation failed in require at /usr/share/
BEGIN failed--compilation aborted at /usr/share/
Compilation failed in require at /usr/share/
BEGIN failed--compilation aborted at /usr/share/
Compilation failed in require at /usr/share/
BEGIN failed--compilation aborted at /usr/share/
Compilation failed in require at /usr/share/
Compilation failed in require at /usr/share/
BEGIN failed--compilation aborted at /usr/share/
Compilation failed in require at /usr/sbin/
BEGIN failed--compilation aborted at /usr/sbin/
I observed some random segfaults as well:
[ 7773.234696] tiotest[15052]: segfault at 0 ip 000000000040183e sp 00007f2ed15a3f00 error 4 in tiotest[
[ 7774.185489] apt-get[15073]: segfault at ffffffffffffffff ip 00007f2568a3bbfb sp 00007fff52a88840 error 5 in libapt-
After reboot it suddenly started to work:
# dpkg-reconfigure --frontend noninteractive tzdata
Current default time zone: 'SystemV/CST6CDT'
Local time is now: Thu Apr 14 07:06:20 CDT 2016.
Universal Time is now: Thu Apr 14 12:06:20 UTC 2016.
That suggests that we're dealing with memory corruption bug that eventually leads to fs corruption.
| Joseph Salisbury (jsalisbury) wrote : | #174 |
@emsi, if this is the case, it might indicate the strange commit reported by the bisect. I might have to go through the bisect again and ensure the good results were in fact good.
| Joseph Salisbury (jsalisbury) wrote : | #175 |
The Xenail and Trusty test kernels with commit c01fac1c77 reverted still exhibits the bug. I'm going to go through the bisect again and test for longer each step.
| HyperVLinux (rainer-schmitt) wrote : | #176 |
Good to see that you guys already try to solve this issue. We are working with an onprem HyperV Guest that hosts 3 Ubuntu Servers. After every weekend we run some Backups on this VM's, well known that we must check the Filesystem from our Ubuntus after the backups are finished. If you need add. Informations about our VM Structure and our Ubuntu Hosts drop me a line.
| Joseph Salisbury (jsalisbury) wrote : | #177 |
I was able to reproduce the bug with one of the steps in the bisect that was marked good. That particular commit took 35 hours to reproduce. This is what sent the bisect off track.
I'm testing again, but this time giving each test in the bisect at least 36 hours to run. I should have an update shortly.
| Emsi (trash1-z) wrote : | #178 |
What's your VSS snapshot frequency? Increasing it you can shorten the tests as the problem should appear earlier.
I'm doing the snapshot every 15 minutes. Just snapshots, no need to do a full backup. In my case a snapshot made for any reason (branching, moving to different host etc.) was causing the issue with similar probability.
| faulpeltz (mg-h) wrote : | #179 |
I managed to break a test VM in 10-15min with minimal Ubuntu installs (wily/xenial) by spamming wbadmin calls ( backing up only this single VM) in a loop.. using PowerShell to create and delete snapshots in a loop seems to have the same effect
However, after some time Hyper-V (and VSS) complained about broken writers and refused to backup any more VMs on the server until a VMM service restart..
In a normal environment the issue took weeks of regular daily backups to manifest...
| Joseph Salisbury (jsalisbury) wrote : | #180 |
My backup interval is every 30 minutes. I've run tests against 3.13.0-34 for 48 hours now without reproducing the bug, so that should be the first 'good' kernel for the bisect.
@faulpeltz, is it possible for you to list the steps you are using or attach the PowerShell script to the bug?
| Joseph Salisbury (jsalisbury) wrote : | #181 |
Current results of second bisect:
3.13.0-34 - GOOD
da1674843 - BAD
adbb4e646 - TESTING
The test kernel for commit adbb4e646 as the tip is available here:
http://
I'll let this test run for 36 hours or until it exhibits the bug. I'll also look into using snapshots to try and reproduce the bug faster.
| faulpeltz (mg-h) wrote : | #182 |
For the backup stress test I really just used:
:start
wbadmin start backup -quiet -backupTarget:
goto start
In our case the VM server did not run anything else and the Ubuntu guest was a minmal install, so the loop took only a couple of minutes, and the backup target was a local share (which was only created for the test)
Snapshots can be made using Powershell with:
CheckPoint-VM -ComputerName $HyperVHost -Name $VirtualMachine -Snapshotname $Snapshot
I managed to crash my test VM once (just ran it manually a couple of times) with the snapshots, but didnt try again because the backup method seemed to work well.
For i/o load inside the guest I used bonnie++ with a file size of 512MB and 10 threads
| Joseph Salisbury (jsalisbury) wrote : | #183 |
Thanks for the suggestions @faulpeltz and @Emsi. I was using the Windows Server Backup GUI, which allowed me a maximum of 30 minutes backup intervals.
I now have a Powershell script to kick of one backup after another:
$i=1
while($true)
{
"######
"Starting backup $i"
"######
wbadmin start backup -quiet -backupTarget:
"######
"Finished backup $i"
"######
$i++
}
I'm re-running the test that took 35 hours to reproduce the bug(Commit da1674843 as tip of tree). I hope it causes the bug to trigger much faster. If it does, I'll use this method for testing.
If it still takes a considerable amount of time to reproduce, I'll investigate the snapeshot only method as suggested by @Emsi.
| faulpeltz (mg-h) wrote : | #184 |
We have been running the da1674843 test kernel on another hyper-v server (an older test machine), as well as 4.4.0_21 for comparison; the test kernel failed after 14h the 4.4.0_21 after 9h.
This takes much longer than on the original server (which was a 2-CPU 20-Core 256GB RAM machine), but we can use this machine to run test kernels on if help is still needed.
| Alex Ng (alexng-v) wrote : | #185 |
Any updates on whether adbb4e646 test kernel is able to repro this issue?
In any case, if we can get a next test kernel to try, I can help try repro on it as well.
| faulpeltz (mg-h) wrote : | #186 |
Oops I actually meant adbb4e646 .. The one provided in post #181 as a download
| Joseph Salisbury (jsalisbury) wrote : | #187 |
I wasn't able to reproduce the bug using the test kernel with commit da1674843 as the tip and Powershell as the backup client(Using the scripts posted in #182).
I am able to reproduce the bug with that kernel using the Windows Server Backup GUI, it just took 35 hours.
I'm going to keep using Windows Server Backup to get through the bisect. I'll continue to post the current test kernel in here during the bisect. That way others can test in parallel. We can mark a kernel 'BAD' as soon as we hit the bug and move onto the next kernel, but we can't mark a kernel 'GOOD' until we are sure it really is good.
Per comment #186, I'm going to mark kernel adbb4e646 as bad and build/test the next kernel. I'll post a link to the test kernel here as soon as it is built.
| Joseph Salisbury (jsalisbury) wrote : | #188 |
I built the next test kernel up to commit:
586fbce
I'll test this kernel next. It can also be downloaded from here if others want to test:
http://
| faulpeltz (mg-h) wrote : | #189 |
586fbce failed for me after 28 hours
It would be nice if we could have packages for maybe 2 further versions in the bisect (the current one + good/fail one), so we can run new builds back to back.
| Joseph Salisbury (jsalisbury) wrote : | #190 |
Thanks for the update. The test of the kernel on my system is still running, so it's great you could reproduce the bug faster.
I built the next kernel up to commit:
83215219
It can be downloaded from:
http://
I'll see if there is a way to build predicted kernels to test.
| Joakim Plate (elupus) wrote : | #191 |
Some interesting additional observations. I'm running kernel 4.2.0-35 on 15.10 ubuntu. Last night it hung with readonly system ala- this report. What was interesting was that the machine that hung was NOT included in the backups run on the host system. The host hypervisor does run backups on other virtual hosts, as well as some subdirectories on the same physical disk where the virtual machines vhdx file reside, but not on the now hung virtual machine.
Even thou it's not included in the backup, it will still FREEZE and THAW using the VSS service on the virtual machine. Thus it's not even safe to exclude the machines from backup.
I was able to recover the machine after a reboot after a automatic fsk correction.
| Frederik Bosch (f-bosch) wrote : | #192 |
@elupus This is in line with our observations. Our guess is that the change to a read-only state occurs during/just befor/just after a FREEZE and/or THAW.
| faulpeltz (mg-h) wrote : | #193 |
We observed that as well.
The issue can occur just by creating a volume shadow copy of the volume the Hyper-V disk is stored on (with the Hyper-V VSS writer)
Started running build 83215219 in the meantime.
I also thought about experimenting with creating shadow copies (volatile, with writers) directly in a loop using a diskshadow script
| faulpeltz (mg-h) wrote : | #194 |
8321521963a dead after 19 hours
| Joseph Salisbury (jsalisbury) wrote : | #195 |
I built the next test kernel up to commit:
5e6cf71
I'll test this kernel next. It can also be downloaded from here if others want to test:
http://
| faulpeltz (mg-h) wrote : | #196 |
5e6cf71 crashed after 12 hours
until the next build is available I will let it churn on 3.13.0-34.60 just to make sure its stable
there are only 26 commits in 3402ec8..5e6cf71
| Joseph Salisbury (jsalisbury) wrote : | #197 |
The next kernel is building. It would be good for you to confirm 3.13.0-34.60 is actually good, so we know the bisect is going in the right direction.
| Joseph Salisbury (jsalisbury) wrote : | #198 |
I built the next test kernel up to commit:
dfbdac2e
The test kernel can be downloaded from:
http://
It's probably best to ensure you don't hit the bug with 3.13.0-34.60 first, then test this next kernel.
| Alex Ng (alexng-v) wrote : | #199 |
Don't think this has been asked before, but has anyone had a repro when backups were turned off? Or does this only happen when backups are enabled?
I'm verifying this on my own as well, but if this happens regardless of whether backup is enabled/disabled; then it'll help us narrow down the cause further to either a storage issue (more likely) or a VSS backup issue.
| Frederik Bosch (f-bosch) wrote : | #200 |
@alexng-v I only had this while doing backups. Also, in the initial post on MS Technet refers to it as a backup problem: https:/
| faulpeltz (mg-h) wrote : | #201 |
I did not explicitly test for that, but on our production server the issue went away completely
But we can definitely try that, 48 hours of I/O torture should rule out any non-VSS related issues
| Emsi (trash1-z) wrote : | #202 |
I experienced it during migration and other means involving snapshots.
| Joseph Salisbury (jsalisbury) wrote : | #203 |
@faulpeltz,
I am continuing to test the next test kernel up to commit:
dfbdac2e
Are you testing 3.13.0-34.60 or would you be wiling to do that? Just to confirm it does not contain the bug and the bisect was started at the correct versions.
| faulpeltz (mg-h) wrote : | #204 |
@jsalisbury
We have 3.13.0-34.60 already running for about 22hours straight, no problems yet, as well as dfbdac2e, which also runs fine for now.
I'll just keep it running for a few days
Also, unfortunately, our result for 5e6cf71 might be invalid because the test machine ran out of disk space on the host because of excessive snapshot disks piling up. I had to add a delay of a couple of minutes after each backup to prevent this from happening, this caused basically the same error (kernel error message, readonly remount, disk i/o hang) as the real crash
So if things are stable with those two versions I will rerun 5e6cf71 and 83215219 to make sure the result can be trusted
You already tested a kernel with 6ad4874 reverted, right? Are we sure this is not the culprit?
@emsi
We experienced that too, but weirdly trying to crash it by creating snapshots in a loop only caused one crash on one machine and wasnt reproducible any more
| Joseph Salisbury (jsalisbury) wrote : | #205 |
@faulpeltz,
Yes, I did test a kernel with commit 6ad4874. I tried this before starting the bisect since it looked suspect.
I'm still testing dfbdac2e as well and will let it run for another 24 hours.
| Alex Ng (alexng-v) wrote : | #206 |
To help see if this is an issue in the hv_storvsc driver; I took the storvsc driver code from 3.13.0-34.60 (presumably a good build) and applied it to the 4.2.0-27 kernel (presumably a bad build). Ran tiobench with backups and was able to repro after about 48 hours.
This implies that either:
1) The bad commit is not in the hv_storvsc driver.
2) 3.13.0-34 is not a good build as we previously thought. I'll wait to hear if other people can repro this issue on 3.13.0-34.
The storvsc driver code I took for this snapshot => http://
| Alex Ng (alexng-v) wrote : | #207 |
Also, to add one other thing. There were a bunch of commits made upstream to the storvsc driver in the last few months.
Can we try them out to see if they have any impact on this issue? In particular:
1) 81988a0e6b031bc
2) 3209f9d780d137c
3) 03996f2064a5c5b
| faulpeltz (mg-h) wrote : | #208 |
both 3.13.0-34.60 and dfbdac2e running for 48 hours, no issues, both now have gone through 260 backup cycles
i will keep them running for now
| Joseph Salisbury (jsalisbury) wrote : | #209 |
I've also been running dfbdac2e for 48 hours without hitting the bug.
I don't think bad commit is in the hv_storvsc driver or any HV specific code. I'm not sure how to explain that yet. I tested a kernel with all the HV related commits(c8c38b3, 7af024a and 6ad4874) reverted and the bug still happened.
The current test results indicate the bad commit is somewhere in between dfbdac2 and 5e6cf71 or maybe 83215219 per comment #204.
There are two HV commit in that range is:
7af024a hv: use correct order when freeing monitor_pages
Drivers: hv: balloon: Ensure pressure reports are posted regularly
However, reverting those commits have already been tested as bad.
There are three ext4 commits in that range, which may be related:
265dabe ext4: fix wrong assert in ext4_mb_
d4d2e7e ext4: fix zeroing of page during writeback
cd4842f4 ext4: fix data integrity sync in ordered mode
@faulpeltz, I'm going to mark commit dfbdac2e as good and start on the next kernel. Can you test 5e6cf71 and/or 83215219 to confirm they are bad.
| Joseph Salisbury (jsalisbury) wrote : | #210 |
I'm actually going to build a test kernel with those three ext4 commits reverted and test that. That will allow us to test in parallel and ensure if 5e6cf71 and 83215219 were in fact bad.
| Joseph Salisbury (jsalisbury) wrote : | #211 |
If 5e6cf71 ends up being good, that put's one of the ext4 commits in the suspect range:
cd4842f4 ext4: fix data integrity sync in ordered mode
| Frederik Bosch (f-bosch) wrote : | #212 |
@jsalisbury I would not be surprised by that. It would explain the pain in finding the cause of this bug. Its outside of any of our scopes. Moreover, when you read the commit message (https:/
| Joseph Salisbury (jsalisbury) wrote : | #213 |
I also plan on building a test kernel with just commit cd4842f4 reverted. It's not straight forward because a later xfs commit started using a function added by this commit(
I think the easiest thing for testing and confirming this is the bad commit is to just drop the xfs commit as well, for now. If cd4842f4 ends up being the bad commit, we can also address the xfs dependency with the patch authors and ext4 maintainers.
| Joseph Salisbury (jsalisbury) wrote : | #214 |
I have a test kernel with commit cd4842f4(1c8349a17 in mainline) reverted. It can be downloaded from:
http://
Like I mentioned in the last comment, there is a later xfs commit which depended on commit 1c8349a17 for set_page_
0d085a5 xfs: ensure WB_SYNC_ALL writeback handles partial pages correctly
I also reverted that xfs commit in this test kernel. I'm going to test this kernel to see if it exhibits the bug and if commit 1c8349a17 is the culprit.
| Changed in linux (Ubuntu Xenial): | |
| importance: | Critical → High |
| importance: | High → Critical |
| faulpeltz (mg-h) wrote : | #215 |
I stopped running 3.13.0-34.60 and dfbdac2e after nearly 90 hours and 500 backups with no issues
Started re-running 5e6cf71 and 83215219
If 83215219 is bad, I will run the kernel with cd4842f4 reverted
| Joseph Salisbury (jsalisbury) wrote : | #216 |
I have been testing the kernel with commit cd4842f4(1c8349a17 in mainline) reverted for three days now without hitting the bug. It's looking very promising that commit cd4842f4 is what introduced this bug.
I'll continue to test this kernel for a few more days to ensure it's stable. It would be great if you could test it when you get a chance as well, @faulpeltz.
| Frederik Bosch (f-bosch) wrote : | #217 |
@jsalisbury Maybe you can also create a 4.2.0 kernel with cd4842f4 reverted. Then I can test one.
| Joseph Salisbury (jsalisbury) wrote : | #218 |
That is a good idea, Frederik. I'll build test kernel for all the other releases and post a link to them shortly.
| Joseph Salisbury (jsalisbury) wrote : | #219 |
There is now a 4.2 based Wily test kernel available here:
http://
| faulpeltz (mg-h) wrote : | #220 |
From 4.2.0-35-generic (lp1470250Commi
[ 7016.076017] sd 2:0:0:0: [storvsc] Sense Key : Unit Attention [current]
[ 7016.076062] sd 2:0:0:0: [storvsc] Add. Sense: Changed operating definition
[ 7016.076262] sd 2:0:0:0: Warning! Received an indication that the operating parameters on this target have changed. The Linux SCSI layer does not automa
[ 7016.076274] blk_update_request: I/O error, dev sda, sector 13010136
[ 7016.078164] Aborting journal on device sda1-8.
[ 7016.081118] EXT4-fs error (device sda1): ext4_journal_
[ 7016.082388] EXT4-fs (sda1): Remounting filesystem read-only
From 3.13.0-85-generic (lp1470250Commi
[43345.090297] hv_storvsc vmbus_0_1: cmd 0x35 scsi status 0x2 srb status 0x82
[43345.090327] hv_storvsc vmbus_0_1: stor pkt ffff8800a8d46c28 autosense data valid - len 18
[43345.090334] storvsc: Sense Key : Unit Attention [current]
[43345.090353] storvsc: Add. Sense: Changed operating definition
[43345.090439] sd 2:0:0:0: Warning! Received an indication that the operating parameters on this target have changed. The Linux SCSI layer does not automatically adjust these parameters.
[43345.090445] end_request: I/O error, dev sda, sector 13093264
[43345.091035] Aborting journal on device sda1-8.
[43345.092966] EXT4-fs error (device sda1): ext4_journal_
[43345.093468] EXT4-fs (sda1): Remounting filesystem read-only
| Joseph Salisbury (jsalisbury) wrote : | #221 |
Hmm, I still have not hit the bug with the test kernel that has 1c8349a17 reverted. It's a good thing we have multiple testers, thanks so much, faulpeltz.
For this bug, it's probably best to just finish up with the bisect to identify the exact commit without any guessing.
@faulpeltz, were you able to test and get results for 5e6cf71 and 83215219? If so, I'll update the bisect and build the next test kernel.
| faulpeltz (mg-h) wrote : | #222 |
@jsalisbury, I moved back to testing only a single machine at a given time,
currently 5e6cf71 is running for ~6 hours, 83215219 is up next
we had 5e6cf71 and 83215219 running at the same time without any issues for 24 hours *but* the problem seems to be easier to reproduce with only one machine running
for the other two builds from #220 I tried to rule out any other potential causes; there was nothing suspicious on the Hyper-V host this time at the time of failure
another thought, did anyone experience the crash with a file system other than ext4?
| Joseph Salisbury (jsalisbury) wrote : | #223 |
That is a good idea about testing a file system other than ext4.
There are two other ext4 commits in the bisect range we are testing. It would require 8321521 to be Good for it to be either of these:
265dabe ext4: fix wrong assert in ext4_mb_
d4d2e7e ext4: fix zeroing of page during writeback
I'll await your test results before building the next kernel. I'm going to look at my test script and see why it is taking so long for me to reproduce the bug. I did lower the number of io threads in tiotest because it was making the system almost unusable due to the io load, but maybe that is what's needed to reproduce the bug.
While your testing, I'll go ahead and setup some guests with a filesystem other than ext4 and test.
| tcmbackwards (tcmbackwards) wrote : | #224 |
I had corruption with btrfs months ago with the same iSCSI errors in hyperv. At the time I thought it was btrfs instability with docker overlays but changing to ext4 didn't help. I get the same errors everyone else in this thread has reported with ext4.
| tcmbackwards (tcmbackwards) wrote : | #225 |
Let me clarify, I am using hyper-v and I got the same SCSI errors, not iSCSI. The SCSI errors were the same kernel errors about changing operating parameters.
| Benjamin Ihrig (benjamin-ihrig) wrote : | #226 |
First of all thanks for your effort guys (sorry, I cannot really help you out, I am a Java Developer and not into Ubuntu Kernel)!
I do experience these problems with a Hyper-V environment I operate for a volunteer fire departement.
I am not sure about the following fact, but testing around made it reasonable. My VMs (Ubuntu 14.04) were more likely to get into read-only state if the backup takes very long. When I backup only a few VMs, I usually have the problem very infrequently. If I backup more (or all) VMs, the problem occurs nearly at every backup.
Not sure if this helps indicating the problem, but maybe makes it easier to reproduce the bug, maybe by increasing the size of the disks (or even the used space).
| faulpeltz (mg-h) wrote : | #227 |
5e6cf71 still good after 26 hours, switching to 8321521 next, if that turns out good it might be good idea to re-test 586fbce as well or we can continue the bisect
@jsalisbury
were you able to reproduce the crash on the kernels with 1c8349a17 reverted?
@benjamin-ihrig
on one of our production servers (with ~80 VMs running) I could initially reproduce the crash in 10-15mins just by running a few backups of this single VM (which for the test VM on the beefy machine took <1m) but I don't really want to use this machine for such extended experiments
on a second, smaller server with fewer VMs running, it was still reproducible, on the test machine it takes from hours to a day to appear. Generally the issue is a bit cagey..
| Joseph Salisbury (jsalisbury) wrote : | #228 |
I'm still testing 1c8349a17 now. I increased the number of I/O threads to increase the change of triggering the bug. It's been running for almost 24 hours now. I'll let it run for up to 36 hours with this I/O load.
I agree that if 8321521 does turn out good, we would want to test 586fbce again to be sure about our results.
| faulpeltz (mg-h) wrote : | #229 |
8321521 is good after 40 hours, moving to 586fbce
| faulpeltz (mg-h) wrote : | #230 |
586fbce still running after 26 hours, I will keep it running over the weekend
As far as is can tell, the previous 586fbce run might have been affected by the same issue as the other two versions (5e6cf71/8321521). I do have more confidence in the newer runs, but it would be good if multiple people could repro the positive as well as the negative results
From the state of my tests the problem might be in the 586fbce..37a954a range
We could continue the bisect there (@ 6e60642), although I'm not 100% sure that my results are correct
| faulpeltz (mg-h) wrote : | #231 |
@jsalisbury:
As an update to my latest post:
I re-ran a few even older builds on the weekend:
adbb4e646 - good after 40hours (bad before, might have been another victim of the disk filling up, I think I might have screwed up this run too)
da1674843 - bad after 8 hours (consistent with previous tests)
4c48c359b - currently running, but seems good so far (16hours+, would be consistent with your result)
So, the 4c48c359b.
d215f91 scsi: handle flush errors properly
This adds/changes error handling for SCSI non-block commands; as a guess this might either be overzealous in handling an error from hv or the error just silently happened but was ignored?
| Joseph Salisbury (jsalisbury) wrote : | #232 |
I tested a kernel with commit d215f91 reverted, and it unfortunately hit the bug.
At least the range of commits is getting smaller. I'll restart the bisect between 4c48c359b.
| Joseph Salisbury (jsalisbury) wrote : | #233 |
I started the next bisect between 4c48c359b and da1674843. The first test kernel is built up to the commit:
95d118176516b3a
Can you test this kernel? It can be downloaded from:
http://
| faulpeltz (mg-h) wrote : | #234 |
4c48c359b is still good after 27 hours, starting on 95d1181
If I hit the error I will re-run it immediately to make sure its bad
| faulpeltz (mg-h) wrote : | #235 |
95d1181 is still good after 25 hours, will keep it running for another 10 or so
| faulpeltz (mg-h) wrote : | #236 |
95d1181 good after 38 hours
| Joseph Salisbury (jsalisbury) wrote : | #237 |
I built the next test kernel up to commit:
bb3becb
The test kernel can be downloaded from:
http://
For some reason, I'm now unable to reproduce the bug, even with old kernels that failed before. I'm going to investigate why that is.
| ubuntu (h-lbuntu-2) wrote : | #238 |
FYI, When I did the analysis of this last year I found a couple of additional key data points that may help with reproducing the error. I reported them at the time but they're well buried by now.
1) Timing of the bug appears to be load related. I found that generating the error could take minutes, hours, days or even weeks, depending on load. To generate the error faster, try putting significant I/O and CPU load on the Hyper-V server, especially I/O. I don't have my notes in front of me but I recall that I/O load had the highest influence.
2) RHEL / CentOS is not immune, it just manifests differently. On RHEL/CentOS, at the same time as Ubuntu generates the file system error, RHEL/CentOS will have a large (400ms - ~5000ms) latency in I/O. On RHEL/CentOS it's just that no file system error occurs.
Hope that helps.
| faulpeltz (mg-h) wrote : | #239 |
bb3becb good after 38 hours
| faulpeltz (mg-h) wrote : | #240 |
bb3becb good after 86 hours
I stopped the test run for now
| Joseph Salisbury (jsalisbury) wrote : | #241 |
I built the next test kernel up to commit:
488347f3f
The test kernel can be downloaded from:
http://
| faulpeltz (mg-h) wrote : | #242 |
488347f3f is good after 48 hours
| Dino (dino.m) wrote : | #243 |
Hi everybody. I came here through the link in the Microsoft Technet Forum. We also have these problems under Hyper-V on a Windows Server 2012R2, but with a Debian Jessie 3.16.0-4. We also use Altaro Hyper-V Backup, and once or twice a week after the backup we have to repair the file system. An older Ubuntu VM just works fine.
I just wanted to post this here to let you know about that this isn't only ubuntu related. Unfortunately I couldn't find any bug report regarding debian. This thread here is the only one I could find.
So I just wanted to let you know.
| Joshua R. Poulson (jrp) wrote : | #244 |
@dino.m Indeed, since the 3.16 kernel in Jessie shares a common heritage with the 3.16 Ubuntu Utopic kernel it may indeed have the same problem. However, until we find root cause it is difficult to carry the search elsewhere. Since we're talking Jessie, are you having similar difficulties with the backports kernel?
| faulpeltz (mg-h) wrote : | #245 |
@Dino
Yes we could also reproduce the issue on Jessie (3.16) and I've also seen it in testing/unstable, too
@jsalisbury
Assuming the bisect is correct this time, d215f91 seems the only likely suspect
Which kernel version did you test with this commit reverted?
Maybe some of the later merges reintroduced some of the code/behavior originially in d215f91?
| Joseph Salisbury (jsalisbury) wrote : | #246 |
I built the next test kernel up to commit:
a1dd8c87
The test kernel can be downloaded from:
http://
I agree, the only commit in the current range that is suspect is:
d215f91
I may have bad testing with that commit reverted, so I'll build another test kernel with it reverted. We can then test on kernel with it reverted and continue with the bisect at the same time.
| Joakim Plate (elupus) wrote : | #247 |
I can see a possible issue with that commit. For an invalid sense value, sense_deferred with remain 0. and thus trigger the special logic.
From the rest of the code sense_deferred seem to only be valid in the case when sense_valid, but that is not checked.
Given the large amount of invalid sense output from hyper-v virtual machines, they would be very likely to trigger that exact code path.
| Joseph Salisbury (jsalisbury) wrote : | #248 |
I built a Trusty test kernel with commit d215f91 reverted. The test kernel can be downloaded from:
http://
I don't recall if I reverted that commit in a Trusty test kernel or in Xenial, so you may be correct. A merge after 3.13 may re-introduce the logic added by that commit. We can investigate further for the newer kernels if we find reverting d215f91 in Trusty works.
| faulpeltz (mg-h) wrote : | #249 |
a1dd8c87 failed after 70(!) hours (VSS backups started to fail after 17 hours or so, but the file system was remounted read-only after 70 hours total)
Another observation, something which h I also noticed in previous "bad" runs:
Also almost instantly after starting backups, there were I/O errors on "/dev/sda sector 0" logged, with no obvious/immediate consequential failures, but the first I/O error on a non-zero sector caused a fs remount. Those errors were not in the good runs (or at least they weren't logged :P )
started run on d215f91-reverted
| Dino (dino.m) wrote : | #250 |
Sorry for the late reply
@jrp: I haven't tested with backports kernel and I can't test it on the production machines.
We also have an old VM with Ubuntu 12.04.5 LTS which works fine and without any issues. Maybe you guys can check the differences between this version and today's version.
| Emsi (trash1-z) wrote : | #251 |
Are you aware of the fact that I have reported errors with 3.13.0-32-generic?
| faulpeltz (mg-h) wrote : | #252 |
d215f91-reverted stable for 90 hours
| Joseph Salisbury (jsalisbury) wrote : | #253 |
@faulpeltz, that is a positive sign. I'll build test kernels with this commit reverted in all the other kernels as well for testing. I'll post links shortly.
| Joseph Salisbury (jsalisbury) wrote : | #254 |
However, what is worrying is commit d215f91 was introduced in Ubuntu-
@Emsi, would it be possible for you to test the kernel posted in comment #248?
| Joseph Salisbury (jsalisbury) wrote : | #255 |
I built Wily and Xenial test kernels with commit 89fb4cd reverted(Same as commit d215f91 in Trusty). The test kernels can be downloaded from:
Wily: http://
Xenial: http://
| Emsi (trash1-z) wrote : | #256 |
I'm having difficulties installing those packages on trusty.
I run into:
linux-
BTW: by default in cloud image there are following packages installed:
# dpkg -l | grep 3.19.0
ii linux-image-
ii linux-image-
ii linux-lts-
I'm wondering about linux-lts-
| Frederik Bosch (f-bosch) wrote : | #257 |
@emsi I had that problem too, you should ignore the binutils upgrade. I had a look at the CHANGELOG of binutils and there is no significant change. So the installation should continue although there is a dependency mismatch. I cannot recall exactly what I fix the mismatch.
| Emsi (trash1-z) wrote : | #258 |
Testing...
| faulpeltz (mg-h) wrote : | #259 |
No luck with the Xenial kernel (4.4.0-22), I could repro the crash 2 times (after a couple of hours each). Testing the Wily kernel next.
Here is the relevant part of the logs (both crashes produced near identical logs):
Jun 07 20:19:44 muchcrash02 kernel: sd 2:0:0:0: Device offlined - not ready after error recovery
Jun 07 20:19:44 muchcrash02 kernel: sd 2:0:0:0: [sda] tag#73 FAILED Result: hostbyte=DID_OK driverbyte=
Jun 07 20:19:44 muchcrash02 kernel: sd 2:0:0:0: [sda] tag#73 CDB: Write(10) 2a 00 01 16 6c 00 00 04 00 00
Jun 07 20:19:44 muchcrash02 kernel: blk_update_request: I/O error, dev sda, sector 18246656
Jun 07 20:19:44 muchcrash02 kernel: sd 2:0:0:0: rejecting I/O to offline device
Jun 07 20:19:44 muchcrash02 kernel: sd 2:0:0:0: [sda] killing request
Jun 07 20:19:44 muchcrash02 kernel: sd 2:0:0:0: rejecting I/O to offline device
Jun 07 20:19:44 muchcrash02 kernel: sd 2:0:0:0: [sda] FAILED Result: hostbyte=
Jun 07 20:19:44 muchcrash02 kernel: sd 2:0:0:0: [sda] CDB: Write(10) 2a 00 01 17 60 00 00 04 00 00
Jun 07 20:19:44 muchcrash02 kernel: blk_update_request: I/O error, dev sda, sector 18309120
Jun 07 20:19:44 muchcrash02 kernel: EXT4-fs warning (device sda1): ext4_end_bio:329: I/O error -5 writing to inode 921923 (offset 234881024 size 8388608 starting block 2288896)
Jun 07 20:19:44 muchcrash02 kernel: Buffer I/O error on device sda1, logical block 2288384
..
Jun 07 20:19:44 muchcrash02 kernel: Buffer I/O error on device sda1, logical block 2288393
Jun 07 20:19:44 muchcrash02 kernel: sd 2:0:0:0: rejecting I/O to offline device
| faulpeltz (mg-h) wrote : | #260 |
4.2.0-36-
| Joseph Salisbury (jsalisbury) wrote : | #261 |
@faulpeltz, so per you testing it looks like:
3.13 based kernel with dfbdac2e(Same commit as 89fb4cd, but using the Trusty SHA1) reverted fixes the bug.
4.2 based kernel with 89fb4cd reverted still exhibits the bug.
4.4 based kernel with 89fb4cd reverted still exhibits the bug.
This does seem to indicate that a merge or patch after 3.13 is re-introduce the logic added by commit dfbdac2e.
I directly compared trusty commit dfbdac2e and mainline commit 89fb4cd to confirm they are exactly the same. They only differ in the commit message.
Just to clarify, trusty is using a different SHA1 than the wily and xenial kernels because commit 89fb4cd1f was added to mainline in v3.16.
So it seems we are getting much closer, but further code inspection is needed to find the logic that is doing similar things in the 4.2 and 4.4 kernels. I'll dig in and see what I can find.
| faulpeltz (mg-h) wrote : | #262 |
@jsalisbury
Yes I can confirm that. Both 4.X kernels were run twice to make sure the crash is reproducible, and the 3.13 which seems stable ran for a long time.
| Emsi (trash1-z) wrote : | #263 |
Good news.
# uname -a
Linux backup-02 3.13.0-86-generic #131~lp1470250C
It is running since Jun 7 16:30:10 and still no crash.
The only issue is that integration with VMM went awry and the hostname is reported as: getaddrinfo failed: 0xfffffffe Name or service not known.
In the meantime I run 39.19.0-59 on the same cluster and it crashed twice (though vmm integration is OK).
| Emsi (trash1-z) wrote : | #264 |
Keep in mind tough that I suggested that it might be some kind of memory corruption bug and the filesystem corruption might be just manifestation. I experiences different problems on 3.13.0-32-generic (random crashes and so on) thet were related to snapshoting. I guess the vmm integration is made through hv_kvp_daemon so something is rotten in the state of Denmark.
| Joseph Salisbury (jsalisbury) wrote : | #265 |
Thanks for the update, @Emsi. I'll be traveling for the next 24 hours or so. That will give me some time to focus on the diffs between 3.13 and 4.2 and newer with that commit reverted. I'll post my findings here.
| Joseph Salisbury (jsalisbury) wrote : | #266 |
There are quite a few commits that may also need to be reverted from 3.13 to the 4.2 kernel. There is nothing evident that commit 89fb4cd1f does that can be easily identified the the Wily and newer code.
It may be best to narrow down the specific kernel version that contains the second offending commit. To start, I build a Utopic(3.16) based kernel with commit 89fb4cd1f reverted. Can you test this kernel to see if it still exhibits the bug? It can be downloaded from:
http://
| faulpeltz (mg-h) wrote : | #267 |
The 3.19.0-61-generic you posted failed after 2 hours (currently re-running)
Also, isn't this 3.19 a vivid kernel?
sd 2:0:0:0: Device offlined - not ready after error recovery
sd 2:0:0:0: [sda] FAILED Result: hostbyte=DID_OK driverbyte=
sd 2:0:0:0: [sda] CDB:
Write(10): 2a 00 00 a1 cc 00 00 04 00 00
blk_update_request: I/O error, dev sda, sector 10603520
EXT4-fs warning (device sda1): ext4_end_bio:317: I/O error -5 writing to inode 928070 (offset 704643072 size 8388608 starting block 1325568)
Buffer I/O error on device sda1, logical block 1325184
..
Buffer I/O error on device sda1, logical block 1325193
sd 2:0:0:0: rejecting I/O to offline device
sd 2:0:0:0: [sda] killing request
sd 2:0:0:0: rejecting I/O to offline device
EXT4-fs warning (device sda1): ext4_end_bio:317: I/O error -5 writing to inode 928070 (offset 721420288 size 8388608 starting block 1330048)
| Joseph Salisbury (jsalisbury) wrote : | #268 |
@faulpeltz, yes sorry that test kernel was for vivid. Thanks for testing an narrowing it down further.
I did build a Utopic 3.16 based kernel now. It has commit 89fb4cd1f7 reverted. It can be downloaded from:
http://
Can you give this one a test. It should narrow down the commits further.
| faulpeltz (mg-h) wrote : | #269 |
The second run of the 3.19 vivid kernel crashed after 16 hours
The Utopic kernel (3.16) crashed after 23 hours (first run), restarting
| Tommy Eriksen (toe-x) wrote : | #270 |
Hi,
Do we have any kind of pattern on this yet? I have (so far) 4 VMs exhibiting this behaviour constantly - but out of maybe 200 Ubuntu VMs on Hyper-V.
Problem is it's a production environment and I can't easily test different versions (as it requires proposing changes for each machine I want to update) - so would it be possible for you (who've had more testing time) to direct me to one of the 14.04 compatible kernels that you've had success with?
Thanks a lot in advance,
Tommy
| Joseph Salisbury (jsalisbury) wrote : | #271 |
@faulpeltz, thanks again for testing. We're getting closer to narrowing down the second commit that needs to be reverted. I took a look of commits between 3.13 and 3.16. One sticks out as a possibility: bc85dc5. I built a Utopic test kernel with commits 89fb4cd and bc85dc5 reverted. The test kernel can be downloaded from:
http://
Can you give this test kernel a try? If it fails, we can bisect down the commits between 3.13 and 3.16.
| faulpeltz (mg-h) wrote : | #272 |
@jsalisbury: started testing 3.16 "double revert"
| faulpeltz (mg-h) wrote : | #273 |
Unfortunately, it failed after 21 hours
BTW we are at 240TB written on our test server :P
| Joseph Salisbury (jsalisbury) wrote : | #274 |
I built one more test kernel with 11 of the commits between 3.13 and 3.16 reverted. Can you test this kernel to see if one of this commits is the second issue? It can be downloaded from:
http://
| faulpeltz (mg-h) wrote : | #275 |
@jsalisbury:
Your newest build is now at ~35hours without any issues; will keep it running over the weekend
Could you maybe post the commits you reverted?
| faulpeltz (mg-h) wrote : | #276 |
.. and it failed :(
| Emsi (trash1-z) wrote : | #277 |
http://
(sry, couldnt' resist it :)
{kind=link}
| Joseph Salisbury (jsalisbury) wrote : | #278 |
I'm working on building a test kernel with all of the commits to scsi_lib.c between v3.13 and 3.16 reverted. Some of the commits need to be backported, but I should have a test kernel shortly.
| Joseph Salisbury (jsalisbury) wrote : | #279 |
Ok, I built one more test kernel with all of the commits to scsi_lib.c between v3.13 and 3.16 reverted. The list of commits reverted are:
39460b Revert "scsi: handle command allocation failure in scsi_reset_
9ab4c8d Revert "fix regression in SCSI_IOCTL_
53bad98 Revert "[SCSI] Add timeout to avoid infinite command retry"
db3519f Revert "[SCSI] do not manipulate device reference counts in scsi_get/
73a18ef Revert "block: remove struct request buffer member"
e113519 Revert "scsi: explicitly release bidi buffers"
d499c5c Revert "block: add blk_rq_
a6007d4 Revert "Fix uses of dma_max_pfn() when converting to a limiting address"
5cff82a Revert "[SCSI] avoid taking host_lock in scsi_run_queue unless nessecary"
5b26bad Revert "[SCSI] remove a useless get/put_device pair in scsi_request_fn"
391dd86 Revert "[SCSI] remove a useless get/put_device pair in scsi_next_command"
0ea6db9 Revert "[SCSI] remove a useless get/put_device pair in scsi_requeue_
8269e93 Revert "scsi: Make sure cmd_flags are 64-bit"
f24f671 Revert "[SCSI] don't reference freed command in scsi_init_sgtable"
13408dd Revert "[SCSI] don't reference freed command in scsi_prep_return"
bfa085e Revert "[SCSI] Fix command result state propagation"
fd5c3b0 Revert "scsi: remove scsi_end_request"
cb70e5e Revert "scsi: reintroduce scsi_driver.
440599c Revert "scsi: handle flush errors properly"
The test kernel can be downloaded from:
http://
If this test kernel still has the issue, we will have to first revert 89fb4cd then bisect again between 3.13 and 3.16.
| faulpeltz (mg-h) wrote : | #280 |
Unfortunately, it failed after a few hours. Trying to repro the crash a second time.
| faulpeltz (mg-h) wrote : | #281 |
And it crashed again after 10 hours..
Another thing: I looked at the timing of the (most recent) crashes a bit and it seems like they always happen after the backup has completed, when its merging back the backup checkpoint disk (which can be quite large under heavy I/O)
| Frederik Bosch (f-bosch) wrote : | #282 |
@faulpeltz I confirm the timing. I was never as specific as you are now. I already mentioned earlier that it always happens towards the end of the backup. I would not be surprised if the crash happens during the merge.
| Joseph Salisbury (jsalisbury) wrote : | #283 |
Thanks again for testing! It seems like we now need to perform another round of bisecting between 3.13 and 3.16 since reverting all the commits mentioned in comment #279 did not resolve the bug.
So what we need to do is revert 89fb4cd before each step on the bisect. I'll get started on building the first kernel now. We first need to find out if this second offending commit was introduced in 3.14 or 3.15. I'll post a test kernel shortly.
| Joseph Salisbury (jsalisbury) wrote : | #284 |
I built a 3.15 based kernel, which can be downloaded from:
http://
Can you give this kernel a test? It never had commit 89fb4cd applied, so it did not need to be reverted.
| faulpeltz (mg-h) wrote : | #285 |
Started run on 3.15, but there were no cloud tools in your build, so I used the linux-cloud-tools from 3.16.0-76 (jus copied the hv_* daemons over)
| faulpeltz (mg-h) wrote : | #286 |
Crashed after 30 and 12 hours.
| Joseph Salisbury (jsalisbury) wrote : | #287 |
It's looking like the second bad commit came in the 3.14 or 3.15 kernel. Can you test the following two mainline kernels:
3.15-rc1: http://
3.14 final: http://
These won't have hte cloud tools built, but you should be able to use the 3.16 version like you used in comment #285. Let me know if you can't, and I'll see if I can build them.
| faulpeltz (mg-h) wrote : | #288 |
Both crashed, 3.15rc1 after about 20h, 3.14 only after 66h
I am starting to wonder if it might be a good idea to run the good(?) 3.13.0-86(+revert) kernel for a week or two to make sure its actually good.
| Joseph Salisbury (jsalisbury) wrote : | #289 |
That would be a great test. I will also be out next week, so it would be good timing for a week long run. The reverted test kernel can be downloaded from:
http://
Before starting that test, can you test the upstream v3.14-rc1 kernel? It is available from:
http://
| faulpeltz (mg-h) wrote : | #290 |
Started run on 3.14-rc1
| faulpeltz (mg-h) wrote : | #291 |
3.14rc crashed after 3.14-rc1
However isn't the crash to be expected in all the mainline kernels >=3.14 since d215f91 has not been reverted in them?
| faulpeltz (mg-h) wrote : | #292 |
i meant crashed after 12 hours *g*
| Joseph Salisbury (jsalisbury) wrote : | #293 |
@faulpeltz, were you able to run the test kernel with d215f91 reverted for a long duration, like a week?
| faulpeltz (mg-h) wrote : | #294 |
Unfortunately it crashed after about 80 hours.
I am currently running 4c48c35 from the original bisect (95h+)
But things seem increasingly random at this point.
I tweaked the IO load on the host and guest machine and it seems the crashes are now reproducible a bit faster, but I think we might need a few ideas on how to force the crashes.
I already tried creating and deleting machine snapshots in a loop but that didn't do anything.
| Joseph Salisbury (jsalisbury) wrote : | #295 |
The Trusty test kernel with d215f91 reverted failed after 80 hours? That is the kernel that can be downloaded from here:
http://
| faulpeltz (mg-h) wrote : | #296 |
Unfortunately, yes. I did not find any evidence of other Hyper-V/Host related problems.
I will try to repro the crash at least once to be sure.
| Joseph Salisbury (jsalisbury) wrote : | #297 |
The test kernel I built an post in comment #295 was Ubuntu-
I wonder if it could be that the second bad commit is actually between 3.13.0-35.61 and 3.13.0-86.131.
Can you continue to run 4c48c35 from the original bisect and see if it is good for a long period?
As another test to see if there is a second bad commit added later in Trusty 3.13, I can build a 3.13.0-35.62 kernel with d215f91 reverted.
| Joseph Salisbury (jsalisbury) wrote : | #298 |
I built a 3.13.0-35.62 kernel with d215f91 reverted. It is available here:
http://
Can you test this kernel when you have a chance? If it runs past the 80 hour mark, I'd say let it run for a week if you can.
| faulpeltz (mg-h) wrote : | #299 |
Update (no real results yet)
I tried to improve on the test cycle by stopping the hyper-v backup immediately after it has begun, then waiting until the delta disks have been merged back (rinse and repeat)
It took some time to get stable but it seems to have a 6-7x speedup compared to the original variant.
Currently running various kernels, unfortunately we have to rebuild parts of our test environment because it seems like cheap SSDs dont like 600TB writen to them...
| Tommy Eriksen (toe-x) wrote : | #300 |
Hi Guys,
Any news on the testing? We have an increasingly large number of servers failing after their backup run; it is getting a bit critical, unfortunately.
Thanks a lot,
Tommy
| Frederik Bosch (f-bosch) wrote : | #301 |
@Tommy Eriksen, I believe the current status is that we have no idea. Every time when I think we are getting close on the cause of the problem, there comes proof that it is not the cause of the problems. For us it already critical for months.
We are in the middle of moving our systems. I know @jsalisbury is doing the best he can and @faulpeltz is doing his best effort too, but the truth is that we are nowhere. It can still take months for the issue to be solved.
Sorry for this message, but I think we should be clear on this. This problem can only be solved with extra (testing) manpower.
| faulpeltz (mg-h) wrote : | #302 |
Currently re-running a few test kernels.
Current results:
3.13.0-35-generic #62-Commitd215f
3.13.0-34-generic #61 @4c48c359b: GOOD
3.13.0-34-generic #61 @95d1181: GOOD
| Joseph Salisbury (jsalisbury) wrote : | #303 |
@faulpeltz, so it sounds like we can confirm the latest commit to pass in 3.13.0-34 is 95d1181?
If that is the case, it might be worthwhile for me to build a test kernel with d215f91 as tip of the tree and a second kernel with 71425a9 as the tip. Just let me know if you could test those two additional kernels and I'll build them.
In addition, the v4.8-rc1 mainline kernel is now available. There is always the change, that this bug was fixed there and we can "Reverse" bisect. 4.8-rc1 is available here:
| faulpeltz (mg-h) wrote : | #304 |
@jsalisbury: Yes, as far as I can trust my results
Currently running 488347f (which is reasonably close to 71425a9)
If the current one doesnt fail I would test d215f91 next, then 71425a9 and the 4.8rc1 mainline
| faulpeltz (mg-h) wrote : | #305 |
488347f seems stable after 25h
4.8-rc1 crashed/hung after ~7h, but I didnt have the 4.8 cloud tools (using the 4.4 ones),
@jsalisbury: maybe you could build those?
| Joseph Salisbury (jsalisbury) wrote : | #306 |
@faulpeltz, I created athe tools and uploaded them to:
http://
| faulpeltz (mg-h) wrote : | #307 |
unfortunately still the same problem using the v4.8 tools
(on 4.4 and up it doesnt remount the filesystem read-only, it just hangs on any write operation)
dmesg output:
[30626.788513] hv_utils: VSS: timeout waiting for daemon to reply
[30627.100164] hv_utils: VSS: Transaction not active
[30813.152039] INFO: task rs:main Q:Reg:1765 blocked for more than 120 seconds.
[30813.152569] Not tainted 4.8.0-040800rc1
[30813.153094] "echo 0 > /proc/sys/
[30813.153627] rs:main Q:Reg D ffff8b44c2657fc0 0 1765 1 0x00000000
[30813.153630] ffff8b44c14d0300 ffff8b44b2b2e9c0 00000000854a7bc8 ffff8b44b14a8000
[30813.153631] ffff8b44b14a7e78 ffff8b44ae46c2c8 ffffffffffffffff ffff8b44ae46c2e0
[30813.153632] ffff8b44b14a7e10 ffffffff94215131 ffff8b44b2b2e9c0 ffffffff94217a8a
[30813.153633] Call Trace:
[30813.153637] [<ffffffff94215
[30813.153639] [<ffffffff94217
[30813.153640] [<ffffffff93f4c
[30813.153642] [<ffffffff93cc8
[30813.153644] [<ffffffff93e12
[30813.153645] [<ffffffff93e0f
[30813.153646] [<ffffffff93e10
[30813.153647] [<ffffffff94219
(repeats every 120 seconds)
| Alex Ng (alexng-v) wrote : | #308 |
Might be worth trying this patchset: https:/
The first patch in the set addresses some issues with VSS that would cause it to take a long time to initiate backup (and even may timeout).
The second patch is not necessary (but will need VSS daemon to be replaced if you choose to apply it).
| Joseph Salisbury (jsalisbury) wrote : | #309 |
I built a v4.8-rc2 test kernel with the first patch Alex mentions in comment #308. Can this kernel be tested to see if it still exhibits the bug?
The test kernel can be downloaded from:
http://
Alex, do you think we need the second patch for testing of this particular bug?
| faulpeltz (mg-h) wrote : | #310 |
v4.8-rc2 (with patch 1/2 from #308) failed after 18h :(
With the first patch applied, the VSS daemon decides to quit, but a THAW is missing after the FREEZE there are the usual syscall timeouts afterwards
kernel: sd 2:0:0:0: [storvsc] Add. Sense: Changed operating definition
kernel: sd 2:0:0:0: Warning! Received an indication that the operating parameters on this target have changed. The Linux SCSI layer does not automa
kernel: hv_utils: VSS: timeout waiting for daemon to reply
kernel: hv_utils: VSS: Transaction not active
systemd[1]: hv-vss-
unknown[2966]: Hyper-V VSS: VSS: op=FREEZE: succeeded
systemd[1]: hv-vss-
unknown[2966]: Hyper-V VSS: write failed; error: 22 Invalid argument
systemd[1]: hv-vss-
kernel: hv_utils: VSS: failed to communicate to the daemon: -22
| Alex Ng (alexng-v) wrote : | #311 |
One reason you may see the timeout messages is due to having a mismatch between the user-space hv_vss_daemon version and the kernel version.
Can you rebuild the user-space hv_vss_daemon under the source tree's tools/hv directory and replace the one provided that's provided in Ubuntu by default?
| Alex Ng (alexng-v) wrote : | #312 |
And in response to Joseph's comment #309, the second patch shouldn't be required as it's related to a feature introduced in Windows Server 2016 (I'm assuming you folks are testing in Windows Server 2012 R2).
| faulpeltz (mg-h) wrote : | #313 |
- Experimental fix/workaround for hv_vss_daemon (based on 4.4.0-34) Edit (1.1 KiB, text/plain)
I spent some time investigating our issue further.
As far as I can tell, the main issue is that ioctl(FIFREEZE) can take a long time when running VSS backups, and the default timeout is 10s.
This is very noticeable under load, with rare peaks of >5s seen, so 10s seem plausible
If the timeout is hit in the kernel module, the hv_vss_daemon doesnt recover and quits, with the FS still frozen.
This fixes some HV VSS daemon behavior where it doesnt recover on a write failed if the previous request timed out (e.g. THAW takes too long)
We are currently running this patch including @AlexNg 's patch (1 of 2) in the usual backup loop
We already hit the bug at least 5 times, which causes the VSS backup to fail, but subsequent backups work without problems, and the guest systems continue to work normally
| Frederik Bosch (f-bosch) wrote : | #314 |
@faulpletz Do you mean with "and the guest systems continue to work normally" that the guest does not have any read-only problems any more with your patch?
| faulpeltz (mg-h) wrote : | #315 |
@Frederik: yes, as far as I have seen. The file systems are still frozen between FREEZE and THAW, which in the case of timeouts, is >10s, I have seen about 30s in some of our error cases. But they do recover.
I only tried the patched 4.4.0-34 version for now, though
Some testing would be appreciated by everyone here I think :)
The kernel version I tried is ubuntu-xenial 4.4.0-34 with @alexng patch 1/2 from #308 and my patch
| tags: | added: patch |
| Joseph Salisbury (jsalisbury) wrote : | #316 |
@faulpeltz, that is great work creating the new patch. I'll build test kernels for all releases with the first patch from Alex and your patch posted in comment #313.
| Joseph Salisbury (jsalisbury) wrote : | #317 |
I built a Xenial test kernel with the first patch from Alex and the patch from faulpeltz. The test kernel can be downloaded from:
http://
A little backporting is needed to get the patches to apply to Trusty, but I'll also post that kernel shortly.
| Joshua R. Poulson (jrp) wrote : | #318 |
| Emsi (trash1-z) wrote : | #319 |
It looks like it does the trick! Already over 90h of testing with tiobench and it works like a charm!
Usually it took less than 4h (several at best) to crash.
| Joseph Salisbury (jsalisbury) wrote : | #320 |
@Emsi, that is great news. Is this with the kernel that includes both the patch from Alex and the one from faulpeltz, which was posted in comment #317?
| Emsi (trash1-z) wrote : | #321 |
Yes.
Linux backup-01 4.4.0-36-generic #55~lp1470250Pa
Another 24h and no crash.
| Emsi (trash1-z) wrote : | #322 |
I'm really looking forward to test the path on trusty.
| Joseph Salisbury (jsalisbury) wrote : | #323 |
I backported the patch from faulpeltz to trusty and built a test kernel. The test kernel can be downloaded from:
http://
Can you give this kernel a test?
| Jason (jasef) wrote : | #324 |
I'd love to. Can you advise how I do that? I'm a good typist, but cut n paste is so much better!
| Joseph Salisbury (jsalisbury) wrote : | #325 |
You can install the .deb packages by using the dpkg command from a terminal. For example:
sudo dpkg -i linux-image-
| Jason (jasef) wrote : | #326 |
- Ubuntu Error 4c.png Edit (74.0 KiB, image/png)
{kind=link}
I was able to patch the kernel, however the fault still exists. I'm uncertain if issue is related to VSS, but in ballpark (see screenshots). Ubuntu 16.04.1 on same server smooth as silk.
| Emsi (trash1-z) wrote : | #327 |
The xenial kernel works like a charm since the patch. Great work! :)
I'm using application consistent backup (the Hyper-V signals snapshot to the guest OS) rather than crash consistent (snapshoting without informing the guest). The Hyper-h integration services in the guest are required for that (I'm using ubuntu cloud images that are preloaded with that).
I'll test the trusty patches now.
| Joshua R. Poulson (jrp) wrote : | #328 |
@trash1-z,
Application-
Hyper-V integration services is integrated into the Ubuntu kernel through our collaboration with Canonical, and is quite up to date in Xenial.
| Joshua R. Poulson (jrp) wrote : | #329 |
Er, not "filesystem system" but "filesystem consistent".
| faulpeltz (mg-h) wrote : | #330 |
We moved some machines back to their regular backup schedule with the new kernel, no problems so far
| Joseph Salisbury (jsalisbury) wrote : | #331 |
@faulpeltz, have had a chance to test the Trusty kernel, posted in comment #323? That kernel only has your patch and not Alex's. It would be good to know if both are needed.
| Emsi (trash1-z) wrote : | #332 |
Over 24h of trusty tests under heavy load and so good so far.
IMHO the kernel patch should suffice. I don't see "trying to recover VSS connection" messages neither on 16.04 kernel nor 14.04.
| Emsi (trash1-z) wrote : | #333 |
No luck with 14.04. After couple of days two test machines restarted unexpectedly at the very same moment. I sustepct kernel crash but the virtual console is gone and nothing was logged.
On the other hand the xenial machine is working for weeks now without any issues.
| Joseph Salisbury (jsalisbury) wrote : | #334 |
Thanks for the update. I'll rebuild the 14.04 test kernel, but this time with both patches. That is what the Xenial test kernel has.
| Joseph Salisbury (jsalisbury) wrote : | #335 |
I'm still working on getting a Trusty test kernel build with both patches. Alexs' patch is requiring some prereq commits to work with Trusty. I should have a test kernel ready shortly.
| Emsi (trash1-z) wrote : | #336 |
Thank you for the update. I'm staying tuned :)
| no longer affects: | linux (Ubuntu Wily) |
| no longer affects: | linux (Ubuntu Vivid) |
| Joseph Salisbury (jsalisbury) wrote : | #337 |
There should be a Trusty test kernel soon. I've had to identify 13 prereq commits to get the two patches to apply and build properly.
For Xenial and newer, there has been positive test results from Emsi and faulpeltz with Alexs' patch and the one from faulpeltz. Are we comfortable with submitting an SRU request for those two patches, or do we think more testing is required.
| Alex Ng (alexng-v) wrote : | #338 |
Hi @faulpeltz,
A few questions/comments about your patch:
1) Can you submit your patch to the upstream kernel?
2) Under load, were you able to measure how long the FIFREEZE operation took before it succeeded? I'm trying to see if we can increase the timeout of the kernel driver before it hits the error condition that you encountered.
Thanks,
Alex
| faulpeltz (mg-h) wrote : | #339 |
@Alex
1) Yes, but I might need some help with that. Which list/maintainer should I submit it to?
2) On our test machine, with both the hyper-v host as well as the guest under heavy i/o load, it was a few hundred ms but with high variance and spiking (quite often) in to the 2-4s range, with some extreme values being 10s and more.
I assume that this varies a lot with regards to the test hardware, especially storage.
With light load (but not idle) this was well in the <100ms range but with occasional spikes.
Another thing I noticed was that the freeze operation often took a lot longer (but not always) when triggered directly by the vss daemon through a host backup and not just from a standalone test program which just called FREEZE/THAW in a loop.
| Alex Ng (alexng-v) wrote : | #340 |
Thanks @faulpeltz for the info.
I sent you a private message with the list of maintainers to send the patch (trying to avoid pasting it here in case spam bots can go through this archive).
| Joseph Salisbury (jsalisbury) wrote : | #341 |
I was able to backport the two patches to Trusty. It required quite a few prerequisite commits. The following commits were backported to a Trusty test kernel:
f9cc88d lp1470250: patch from faulpeltz
6f3e8a2 Drivers: hv: utils: Continue to poll VSS channel after handling requests.
725a85d Drivers: hv: utils: fix a race on userspace daemons registration
a0c12c6 Drivers: hv: kvp: fix IP Failover
51fea7d Drivers: hv: utils: Invoke the poll function after handshake
42fb309 Drivers: hv: utils: run polling callback always in interrupt context
505de58 Drivers: hv: fcopy: full handshake support
2ec9789 Drivers: hv: vss: full handshake support
e12c519 Tools: hv: vss: use misc char device to communicate with kernel
1f3abc0 Drivers: hv: kvp: convert to hv_utils_transport
d789589 Drivers: hv: fcopy: convert to hv_utils_transport
51ed5da Drivers: hv: vss: convert to hv_utils_transport
edbff5d Drivers: hv: util: introduce hv_utils_transport abstraction
056fbb5 Drivers: hv: fcopy: switch to using the hvutil_device_state state machine
5eb0af4 Drivers: hv: vss: switch to using the hvutil_device_state state machine
a170e78 Drivers: hv: kvp: switch to using the hvutil_device_state state machine
a539598 Drivers: hv: fcopy: rename fcopy_work -> fcopy_timeout_work
7894b35 Drivers: hv: kvp: rename kvp_work -> kvp_timeout_work
d3fc031 Drivers: hv: kvp,vss: Fast propagation of userspace communication failure
ee85362 Drivers: hv: vss: Introduce timeout for communication with userspace
d714c5a Tools: hv: vssdaemon: ignore the EBUSY on multiple freezing the same partition
b957545 connector: add portid to unicast in addition to broadcasting
The test kernel can be downloaded from:
http://
Can this kernel be tested to see if it resolves this bug?
Note, that both the linux-image and linux-image-extra .deb packages need to be installed.
| Benjamin Ihrig (benjamin-ihrig) wrote : | #342 |
Any news on this? Recently it seemed like a fix was found, but no update for about a month now.
Thanks guys!
| Alex Ng (alexng-v) wrote : | #343 |
I'll let @jsalisbury comment on the status of his backported patches.
@jsalisbury, I'd also take this recently submitted patch from upstream kernel as well. It ensures that the VSS driver doesn't timeout any long running FREEZE operations too early. This should preclude the need for faulpeltz's patch in most cases, unless the FREEZE operation takes extraordinarily long (> 15 mins).
| faulpeltz (mg-h) wrote : | #344 |
@Alex
The modified timeout should take care of the issue, but I think its a good idea for the VSS daemon to issue a THAW before either exiting or trying to recover
| Alex Ng (alexng-v) wrote : | #345 |
- 0004-Tools-hv-vss-Thaw-the-filesystem-and-continue-after-.patch Edit (1.1 KiB, text/plain)
@faulpeltz
I agree. Your patch should also be included in case a FREEZE operation does exceed the increased timeout.
I've attached a modified version of your patch that addresses some concerns we had offline. Could you give it a try?
| faulpeltz (mg-h) wrote : | #346 |
@Alex
I will try as soon as I have some spare time
@jsalisbury
Unfortunately I didnt have time to test the kernel from #341.
Including the #343 upstream commit should take care of our issue, and using the patch from #345 (replacing my initial patch) should prevent any hv_vss_daemon crashes in extremely slow cases
| Joseph Salisbury (jsalisbury) wrote : | #347 |
@faulpeltz, Thanks for the update. I'll build a test kernel with all the latest patches and backport them to prior releases.
Just to confirm, so I build the test kernels with everything needed, we need the following:
New patch from comment #343:
Drivers: hv: vss: Operation timeouts should match host expectation
The updated patch from @faulpeltz posted in comment #343
Tools: hv: vss: Thaw the filesystem and continue after freeze fails
And lastly, Alex's patch, which has already landed in mainline:
497af84 Drivers: hv: utils: Continue to poll VSS channel after handling requests.
I have not submitted an SRU request for these three patches yet. I just want to confirm all we need are these three patches, and have good testing feedback.
| Alex Ng (alexng-v) wrote : | #348 |
Thanks Joseph for compiling the list. The patches you've outlined should be sufficient.
| Joseph Salisbury (jsalisbury) wrote : | #349 |
I built Yakkety and Xenial test kernels with the three patches mentioned in comment #347. It would be great if these test kernels can be tested. If they resolve the bug, I'll submit and SRU request to have them included in Yakkety and Xenial.
The test kernels can be downloaded from:
Xenial: http://
Yakkety: http://
The Trusty kernel requires quite a bit of prerequisites commits and backporting. I'll post a trusty test kernel once it's available.
The Zesty kernel will pick up these patches when they land in mainline. The patches will be SRU'd to Zesty if they don't land in mainline in time for release.
| Emsi (trash1-z) wrote : | #350 |
The link to trusty kernels is gone :(
http://
| Joseph Salisbury (jsalisbury) wrote : | #351 |
@Emsi, right now there are only Xenial and Yakkety test kernels with all the updated patches. I will have a Trusty test kernel available shortly.
| Joseph Salisbury (jsalisbury) wrote : | #352 |
@Emsi and whoever can test Trusty. There is a test kernel available at:
http://
This test kernel has the updated 3 patches. It also required 19 prerequisite patches.
| Joseph Salisbury (jsalisbury) wrote : | #353 |
For those interested, the Trusty test kernel contains the following commits:
e81d871 UBUNTU: SAUCE: (no-up) Tools: hv: vss: Thaw the filesystem and continue after freeze fails
01032c1 UBUNTU: SAUCE: (no-up) Drivers: hv: vss: Operation timeouts should match host expectation
4a6f680 Drivers: hv: utils: Continue to poll VSS channel after handling requests.
61c18ef Drivers: hv: kvp: fix IP Failover
db70a1c Drivers: hv: utils: Invoke the poll function after handshake
3c8486d Drivers: hv: utils: run polling callback always in interrupt context
e6e9811 Drivers: hv: fcopy: full handshake support
8f0d521 Drivers: hv: vss: full handshake support
8b167aa Tools: hv: vss: use misc char device to communicate with kernel
6712c24 Drivers: hv: kvp: convert to hv_utils_transport
e5bd829 Drivers: hv: fcopy: convert to hv_utils_transport
9ec74ad Drivers: hv: vss: convert to hv_utils_transport
a2adece Drivers: hv: util: introduce hv_utils_transport abstraction
7aa0716 Drivers: hv: fcopy: switch to using the hvutil_device_state state machine
d804513 Drivers: hv: vss: switch to using the hvutil_device_state state machine
5c9bfa1 Drivers: hv: kvp: switch to using the hvutil_device_state state machine
11aef70 Drivers: hv: fcopy: rename fcopy_work -> fcopy_timeout_work
742f132 Drivers: hv: kvp: rename kvp_work -> kvp_timeout_work
a5a8e26 Drivers: hv: kvp,vss: Fast propagation of userspace communication failure
77fbf9a Drivers: hv: vss: Introduce timeout for communication with userspace
d1401e0 Tools: hv: vssdaemon: ignore the EBUSY on multiple freezing the same partition
fcee4902 connector: add portid to unicast in addition to broadcasting
| Joshua R. Poulson (jrp) wrote : | #354 |
Microsoft will test the trusty kernel in the coming days. The Xenial kernel may be getting all the patches from the 4.9 rebase that's currently in progress.
| Emsi (trash1-z) wrote : | #355 |
3.13.0-103-generic #150~lp1470250 SMP looks promising.
Several days without crash. I encountered some IO errors but the filesystem remains rw.
[Wed Jan 11 13:47:35 2017] hv_storvsc vmbus_0_1: cmd 0x35 scsi status 0x2 srb status 0x82
[Wed Jan 11 13:47:35 2017] hv_storvsc vmbus_0_1: stor pkt ffff8800f0b0f728 autosense data valid - len 18
[Wed Jan 11 13:47:35 2017] storvsc: Sense Key : Unit Attention [current]
[Wed Jan 11 13:47:35 2017] storvsc: Add. Sense: Changed operating definition
[Wed Jan 11 13:47:35 2017] sd 2:0:0:0: Warning! Received an indication that the operating parameters on this target have changed. The
Linux SCSI layer does not automatically adjust these parameters.
[Wed Jan 11 13:47:35 2017] end_request: I/O error, dev sda, sector 0
[Wed Jan 11 13:48:56 2017] hv_storvsc vmbus_0_1: cmd 0x28 scsi status 0x2 srb status 0x82
[Wed Jan 11 13:48:56 2017] hv_storvsc vmbus_0_1: stor pkt ffff8800f0fa0668 autosense data valid - len 18
[Wed Jan 11 13:48:56 2017] storvsc: Sense Key : Unit Attention [current]
[Wed Jan 11 13:48:56 2017] storvsc: Add. Sense: Changed operating definition
[Wed Jan 11 13:48:56 2017] sd 2:0:0:0: Warning! Received an indication that the operating parameters on this target have changed. The Linux SCSI layer does not automatically adjust these parameters.
[Wed Jan 11 14:07:56 2017] hv_storvsc vmbus_0_1: cmd 0x2a scsi status 0x2 srb status 0x82
[Wed Jan 11 14:07:56 2017] hv_storvsc vmbus_0_1: stor pkt ffff8800f0fa50a8 autosense data valid - len 18
[Wed Jan 11 14:07:56 2017] storvsc: Sense Key : Unit Attention [current]
[Wed Jan 11 14:07:56 2017] storvsc: Add. Sense: Changed operating definition
[Wed Jan 11 14:07:56 2017] sd 2:0:0:0: Warning! Received an indication that the operating parameters on this target have changed. The Linux SCSI layer does not automatically adjust these parameters.
| James Straub (jstraub) wrote : | #356 |
It's been more than 1.5 years!
When can we expect this fix to be released?
$ uname -a
Linux Server123 3.13.0-107-generic #154-Ubuntu SMP Tue Dec 20 09:57:27 UTC 2016 x86_64 x86_64 x86_64 GNU/Linux
$ lsb_release -a
No LSB modules are available.
Distributor ID: Ubuntu
Description: Ubuntu 14.04.5 LTS
Release: 14.04
Codename: trusty
Jan 30 01:54:55 Server123 kernel: [78577.687381] cifs_vfs_err: 18 callbacks suppressed
Jan 30 01:54:55 Server123 kernel: [78577.687389] CIFS VFS: open dir failed
Jan 30 01:54:55 Server123 kernel: [78577.692074] CIFS VFS: open dir failed
Jan 30 01:54:56 Server123 kernel: [78578.027096] CIFS VFS: open dir failed
Jan 30 01:54:56 Server123 kernel: [78578.031664] CIFS VFS: open dir failed
Jan 30 03:00:27 Server123 Hyper-V VSS: VSS: freeze of /archive: Success
Jan 30 03:00:27 Server123 Hyper-V VSS: VSS: freeze of /: Success
Jan 30 03:00:27 Server123 kernel: [82509.382621] hv_storvsc vmbus_0_1: cmd 0x28 scsi status 0x2 srb status 0x82
Jan 30 03:00:27 Server123 kernel: [82509.382730] hv_storvsc vmbus_0_1: stor pkt ffff8800d306d368 autosense data valid - len 18
Jan 30 03:00:27 Server123 kernel: [82509.382735] storvsc: Sense Key : Unit Attention [current]
Jan 30 03:00:27 Server123 kernel: [82509.382741] storvsc: Add. Sense: Changed operating definition
Jan 30 03:00:27 Server123 kernel: [82509.382811] sd 2:0:0:0: Warning! Received an indication that the operating parameters on this target have changed. The Linux SCSI layer does not automatically adjust these parameters.
Jan 30 03:00:27 Server123 Hyper-V VSS: VSS: thaw of /archive: Success
Jan 30 03:00:27 Server123 Hyper-V VSS: VSS: thaw of /: Success
Jan 30 03:00:57 Server123 kernel: [82539.424627] hv_storvsc vmbus_0_1: cmd 0x2a scsi status 0x2 srb status 0x82
Jan 30 03:00:57 Server123 kernel: [82539.424678] hv_storvsc vmbus_0_1: stor pkt ffff8800b89df468 autosense data valid - len 18
Jan 30 03:00:57 Server123 kernel: [82539.424683] storvsc: Sense Key : Unit Attention [current]
Jan 30 03:00:57 Server123 kernel: [82539.424689] storvsc: Add. Sense: Changed operating definition
Jan 30 03:00:57 Server123 kernel: [82539.424834] sd 2:0:0:0: Warning! Received an indication that the operating parameters on this target have changed. The Linux SCSI layer does not automatically adjust these parameters.
| David (c6d) wrote : | #357 |
Yeah an official fix would be nice. I am tired of getting up early to see if I have to reboot any vm's :)
| Brian Vargyas (brianv) wrote : | #358 |
So I'm the OP on this bug report from what seems like ages ago... While a lot of hard work as been done by some of the members posting here to try and replicate it, it's been very difficult to track the specific event that has been causing this. While we "fixed" our problem a long time ago by moving all the VM's effected to a server and disabling Hyper-V nightly snapshots, instead opting to shut down all VM's once a month on a weekend and shapshot the whole system and bring it back online, it hasn't been optimal.
Lately, we've been upgrading the 14.04LTS systems one at a time to 16.04 with the latest kernel and dropping them back into active nightly backup systems and so far, have not seen a read-only file system failure with systems running the latest updates. Now these systems are not write heavy either, which tends to trigger this bug more often. At least we've seen some improvement in our environment just by keeping up to date with the latest distribution updates. Outside of this, microsoft has released server 2016 during our lifetime, and while we are not running, it would be interesting to see if that Hyper-V server OS is any better/worse then 2012R2.
| Alex Ng (alexng-v) wrote : | #359 |
Hi @jsalisbury,
Any status update on the patches for this issue?
It appears the test kernels have resolved the issue.
Let us know if you need additional testing or have questions about the patches.
Thanks,
Alex
| Joseph Salisbury (jsalisbury) wrote : | #360 |
Just waiting on test results for Trusty per comments #352 and #353. It sounds like the test kernels resolved the issue? If that is the case, I'll submit the SRU request.
| Emsi (trash1-z) wrote : | #361 |
I can confirm that the trusty patches are preventing the filesystem failure.
| Joseph Salisbury (jsalisbury) wrote : | #362 |
The patch from @faulpeltz posted in comment #345 has never landed in mainline. Is there plans for this patch to be sent upstream, or do we just want to include it as a SAUCE patch?
| Joshua R. Poulson (jrp) wrote : | #363 |
That patch was submitted upstream under the title "[PATCH] Tools: hv: recover after hv_vss_daemon freeze times out" but I don't see that it was committed. I'll poke around.
| Joshua R. Poulson (jrp) wrote : | #364 |
By the way, the "operation times should match host expectation" patch in #343 (and listed in #347) is upstream:
commit b357fd3908c1191
Author: Alex Ng <email address hidden>
Date: Sun Nov 6 13:14:11 2016 -0800
Drivers: hv: vss: Operation timeouts should match host expectation
Increase the timeout of backup operations. When system is under I/O load,
it needs more time to freeze. These timeout values should also match the
host timeout values more closely.
Signed-off-by: Alex Ng <email address hidden>
Signed-off-by: K. Y. Srinivasan <email address hidden>
Signed-off-by: Greg Kroah-Hartman <email address hidden>
| Alex Ng (alexng-v) wrote : | #365 |
The patch from @faulpeltz hasn't been mainlined because of some feedback that it shouldn't have to close and reopen the /dev/vmbus/hv_vss device after failure.
I addressed this comment this in a modified version of @faulpeltz's patch (see comment #345).
I haven't heard from @faulpeltz whether he's tested it. From my testing, it seems fine and I expect to resubmit it upstream. If we can make it a SAUCE patch, that would be nice.
| faulpeltz (mg-h) wrote : | #366 |
Sorry guys I had been swamped with other stuff and then simply forgot to test @alexng's patch
I ran it overnight on my original test setup and it also worked for me.
| Changed in linux (Ubuntu Xenial): | |
| status: | In Progress → Fix Committed |
| Changed in linux (Ubuntu Yakkety): | |
| status: | In Progress → Fix Committed |
| Changed in linux (Ubuntu Zesty): | |
| status: | In Progress → Fix Released |
| Emsi (trash1-z) wrote : | #367 |
How about rusty?
| Joseph Salisbury (jsalisbury) wrote : | #368 |
Trusty requires quite a few prereq commits(See comment #353), so it's SRU will be a little behind. However, it will be SRU'd shortly as well.
| Joseph Salisbury (jsalisbury) wrote : | #369 |
The fixes for Xenial, Yakkety and Zesty are committed or released.
However, I built one more Trusty test kernel with all of the prereq commits and the patches. Would it be possible to have this kernel tested one more time before it is SRU'd? It would be good to confirm no regressions are introduced in Trusty due to the number of changes needed. It can be downloaded from:
| Thadeu Lima de Souza Cascardo (cascardo) wrote : | #370 |
This bug is awaiting verification that the kernel in -proposed solves the problem. Please test the kernel and update this bug with the results. If the problem is solved, change the tag 'verification-
If verification is not done by 5 working days from today, this fix will be dropped from the source code, and this bug will be closed.
See https:/
| tags: | added: verification-needed-xenial |
| Thadeu Lima de Souza Cascardo (cascardo) wrote : | #371 |
This bug is awaiting verification that the kernel in -proposed solves the problem. Please test the kernel and update this bug with the results. If the problem is solved, change the tag 'verification-
If verification is not done by 5 working days from today, this fix will be dropped from the source code, and this bug will be closed.
See https:/
| tags: | added: verification-needed-yakkety |
| Launchpad Janitor (janitor) wrote : | #372 |
This bug was fixed in the package linux - 4.4.0-75.96
---------------
linux (4.4.0-75.96) xenial; urgency=low
* linux: 4.4.0-75.96 -proposed tracker (LP: #1684441)
* [Hyper-V] hv: util: move waiting for release to hv_utils_transport itself
(LP: #1682561)
- Drivers: hv: util: move waiting for release to hv_utils_transport itself
linux (4.4.0-74.95) xenial; urgency=low
* linux: 4.4.0-74.95 -proposed tracker (LP: #1682041)
* [Hyper-V] hv: vmbus: Raise retry/wait limits in vmbus_post_msg()
(LP: #1681893)
- Drivers: hv: vmbus: Raise retry/wait limits in vmbus_post_msg()
linux (4.4.0-73.94) xenial; urgency=low
* linux: 4.4.0-73.94 -proposed tracker (LP: #1680416)
* CVE-2017-6353
- sctp: deny peeloff operation on asocs with threads sleeping on it
* vfat: missing iso8859-1 charset (LP: #1677230)
- [Config] NLS_ISO8859_1=y
* Regression: KVM modules should be on main kernel package (LP: #1678099)
- [Config] powerpc: Add kvm-hv and kvm-pr to the generic inclusion list
* linux-lts-xenial 4.4.0-63.84~14.04.2 ADT test failure with linux-lts-xenial
4.4.
- SAUCE: apparmor: fix link auditing failure due to, uninitialized var
* regession tests failing after stackprofile test is run (LP: #1661030)
- SAUCE: fix regression with domain change in complain mode
* Permission denied and inconsistent behavior in complain mode with 'ip netns
list' command (LP: #1648903)
- SAUCE: fix regression with domain change in complain mode
* unexpected errno=13 and disconnected path when trying to open /proc/1/ns/mnt
from a unshared mount namespace (LP: #1656121)
- SAUCE: apparmor: null profiles should inherit parent control flags
* apparmor refcount leak of profile namespace when removing profiles
(LP: #1660849)
- SAUCE: apparmor: fix ns ref count link when removing profiles from policy
* tor in lxd: apparmor="DENIED" operation=
namespace=
name=
- SAUCE: apparmor: Fix no_new_privs blocking change_onexec when using stacked
namespaces
* apparmor oops in bind_mnt when dev_path lookup fails (LP: #1660840)
- SAUCE: apparmor: fix oops in bind_mnt when dev_path lookup fails
* apparmor auditing denied access of special apparmor .null fi\ le
(LP: #1660836)
- SAUCE: apparmor: Don't audit denied access of special apparmor .null file
* apparmor label leak when new label is unused (LP: #1660834)
- SAUCE: apparmor: fix label leak when new label is unused
* apparmor reference count bug in label_merge_
- SAUCE: apparmor: fix reference count bug in label_merge_
* apparmor's raw_data file in securityfs is sometimes truncated (LP: #1638996)
- SAUCE: apparmor: fix replacement race in reading rawdata
* unix domain socket cross permission check failing with nested namespaces
(LP: #1660832)
- SAUCE: apparmor: fix cross ns perm of unix domain sockets
* Xenial update to v4.4.59 stable release (LP: #1678960)
- xfrm: policy: init locks early
- virtio_balloon: init ...
| Changed in linux (Ubuntu Xenial): | |
| status: | Fix Committed → Fix Released |
| Launchpad Janitor (janitor) wrote : | #373 |
This bug was fixed in the package linux - 4.8.0-49.52
---------------
linux (4.8.0-49.52) yakkety; urgency=low
* linux: 4.8.0-49.52 -proposed tracker (LP: #1684427)
* [Hyper-V] hv: util: move waiting for release to hv_utils_transport itself
(LP: #1682561)
- Drivers: hv: util: move waiting for release to hv_utils_transport itself
linux (4.8.0-48.51) yakkety; urgency=low
* linux: 4.8.0-48.51 -proposed tracker (LP: #1682034)
* [Hyper-V] hv: vmbus: Raise retry/wait limits in vmbus_post_msg()
(LP: #1681893)
- Drivers: hv: vmbus: Raise retry/wait limits in vmbus_post_msg()
linux (4.8.0-47.50) yakkety; urgency=low
* linux: 4.8.0-47.50 -proposed tracker (LP: #1679678)
* CVE-2017-6353
- sctp: deny peeloff operation on asocs with threads sleeping on it
* CVE-2017-5986
- sctp: avoid BUG_ON on sctp_wait_
* vfat: missing iso8859-1 charset (LP: #1677230)
- [Config] NLS_ISO8859_1=y
* [Hyper-V] pci-hyperv: Use device serial number as PCI domain (LP: #1667527)
- net/mlx4_core: Use cq quota in SRIOV when creating completion EQs
* Regression: KVM modules should be on main kernel package (LP: #1678099)
- [Config] powerpc: Add kvm-hv and kvm-pr to the generic inclusion list
* linux-lts-xenial 4.4.0-63.84~14.04.2 ADT test failure with linux-lts-xenial
4.4.
- SAUCE: apparmor: fix link auditing failure due to, uninitialized var
* regession tests failing after stackprofile test is run (LP: #1661030)
- SAUCE: fix regression with domain change in complain mode
* Permission denied and inconsistent behavior in complain mode with 'ip netns
list' command (LP: #1648903)
- SAUCE: fix regression with domain change in complain mode
* unexpected errno=13 and disconnected path when trying to open /proc/1/ns/mnt
from a unshared mount namespace (LP: #1656121)
- SAUCE: apparmor: null profiles should inherit parent control flags
* apparmor refcount leak of profile namespace when removing profiles
(LP: #1660849)
- SAUCE: apparmor: fix ns ref count link when removing profiles from policy
* tor in lxd: apparmor="DENIED" operation=
namespace=
name=
- SAUCE: apparmor: Fix no_new_privs blocking change_onexec when using stacked
namespaces
* apparmor oops in bind_mnt when dev_path lookup fails (LP: #1660840)
- SAUCE: apparmor: fix oops in bind_mnt when dev_path lookup fails
* apparmor auditing denied access of special apparmor .null fi\ le
(LP: #1660836)
- SAUCE: apparmor: Don't audit denied access of special apparmor .null file
* apparmor label leak when new label is unused (LP: #1660834)
- SAUCE: apparmor: fix label leak when new label is unused
* apparmor reference count bug in label_merge_
- SAUCE: apparmor: fix reference count bug in label_merge_
* apparmor's raw_data file in securityfs is sometimes truncated (LP: #1638996)
- SAUCE: apparmor: fix replacement race in reading rawdata
* unix domain socket cross permission check failing with n...
| Changed in linux (Ubuntu Yakkety): | |
| status: | Fix Committed → Fix Released |
| Changed in linux (Ubuntu Trusty): | |
| status: | In Progress → Won't Fix |
| tags: | added: cscc |
Some additional details:
https:/