
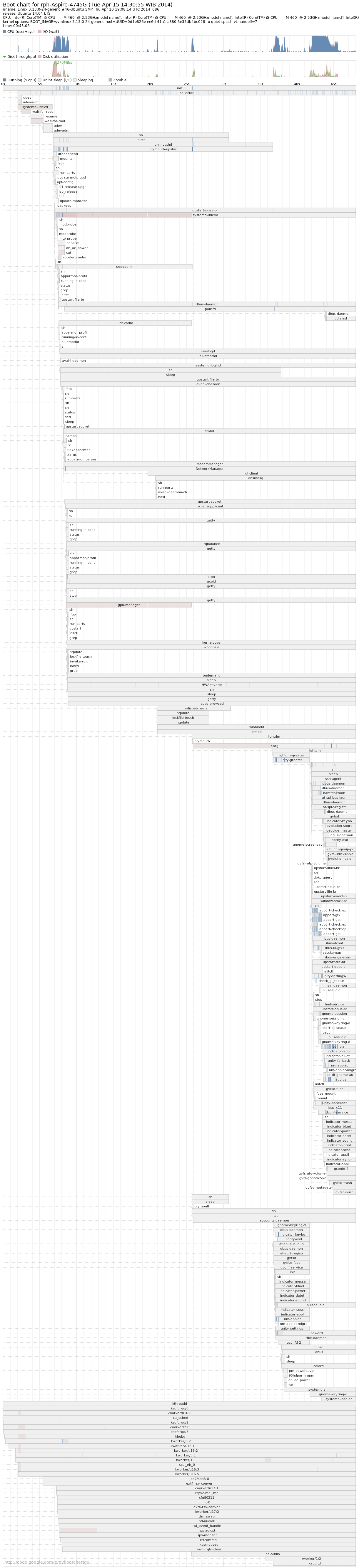
gpu-manager causing long startup delays
| Affects | Status | Importance | Assigned to | Milestone | |
|---|---|---|---|---|---|
| ubuntu-drivers-common (Ubuntu) |
Fix Released
|
High
|
Alberto Milone | ||
| Trusty |
Triaged
|
High
|
Alberto Milone | ||
| Wily |
Triaged
|
High
|
Alberto Milone | ||
Bug Description
I have installing ubuntu 14.04 beta2 and i have update it to latest. My computer take 40 seconds for start up from displaying grub until displaying LightDM on my SSD. My ubuntu 12.04 only takes up 13 seconds for start up on the same SSD.
reported as bug from question:
#246899
https:/
Computer specification:
Ati Mobility Radeon HD 5650 and using Mesa 10.2 from Oibaf's PPA (the start up time is same as default Gallium Mesa 10.1)
Processors: Intel Core i5-460M (Arrandale)
8 GB DDR3 RAM 1333 MHz
Vendor : Acer Aspire 4745G
running dmesg | less
showing:
intel ips 0000:00:1f.6: ME failed to update for more than 1s, likely hung (many rows)
ProblemType: Bug
DistroRelease: Ubuntu 14.04
Package: grub2 2.02~beta2-9
ProcVersionSign
Uname: Linux 3.13.0-24-generic i686
NonfreeKernelMo
ApportVersion: 2.14.1-0ubuntu2
Architecture: i386
CurrentDesktop: Unity
Date: Sun Apr 13 11:25:46 2014
InstallationDate: Installed on 2014-04-07 (5 days ago)
InstallationMedia: Ubuntu 14.04 LTS "Trusty Tahr" - Beta i386 (20140326)
SourcePackage: grub2
UpgradeStatus: No upgrade log present (probably fresh install)
Related branches

{kind=link}
{kind=link}
{kind=link}
| summary: |
- Ubuntu 14.04 takes long start up. + gpu-manager causing long startup delays |
| Changed in ubuntu-drivers-common (Ubuntu): | |
| assignee: | nobody → Alberto Milone (albertomilone) |
| importance: | Undecided → Medium |
| status: | Confirmed → Triaged |
| Changed in ubuntu-drivers-common (Ubuntu): | |
| status: | Triaged → In Progress |
| importance: | Medium → High |
| Changed in ubuntu-drivers-common (Ubuntu): | |
| status: | Triaged → In Progress |
| Changed in ubuntu-drivers-common (Ubuntu Trusty): | |
| status: | New → Triaged |
| Changed in ubuntu-drivers-common (Ubuntu Wily): | |
| status: | New → Triaged |
| Changed in ubuntu-drivers-common (Ubuntu Trusty): | |
| assignee: | nobody → Alberto Milone (albertomilone) |
| Changed in ubuntu-drivers-common (Ubuntu Wily): | |
| assignee: | nobody → Alberto Milone (albertomilone) |
| Changed in ubuntu-drivers-common (Ubuntu Trusty): | |
| importance: | Undecided → High |
| Changed in ubuntu-drivers-common (Ubuntu Wily): | |
| importance: | Undecided → High |
running command:
dmesg | less
output:
[ 115.654087] intel ips 0000:00:1f.6: ME failed to update for more than 1s, likely hung
[ 115.857987] intel ips 0000:00:1f.6: ME failed to update for more than 1s, likely hung
[ 116.057970] intel ips 0000:00:1f.6: ME failed to update for more than 1s, likely hung
[ 116.257979] intel ips 0000:00:1f.6: ME failed to update for more than 1s, likely hung
[ 116.465892] intel ips 0000:00:1f.6: ME failed to update for more than 1s, likely hung
[ 116.665900] intel ips 0000:00:1f.6: ME failed to update for more than 1s, likely hung
[ 116.869912] intel ips 0000:00:1f.6: ME failed to update for more than 1s, likely hung
[ 117.069965] intel ips 0000:00:1f.6: ME failed to update for more than 1s, likely hung
[ 117.277921] intel ips 0000:00:1f.6: ME failed to update for more than 1s, likely hung
[ 117.485865] intel ips 0000:00:1f.6: ME failed to update for more than 1s, likely hung
[ 117.693884] intel ips 0000:00:1f.6: ME failed to update for more than 1s, likely hung
[ 117.893861] intel ips 0000:00:1f.6: ME failed to update for more than 1s, likely hung
[ 118.109871] intel ips 0000:00:1f.6: ME failed to update for more than 1s, likely hung
[ 118.317804] intel ips 0000:00:1f.6: ME failed to update for more than 1s, likely hung
[ 118.545822] intel ips 0000:00:1f.6: ME failed to update for more than 1s, likely hung
[ 118.745784] intel ips 0000:00:1f.6: ME failed to update for more than 1s, likely hung
[ 118.945821] intel ips 0000:00:1f.6: ME failed to update for more than 1s, likely hung
[ 119.145812] intel ips 0000:00:1f.6: ME failed to update for more than 1s, likely hung
[ 119.345770] intel ips 0000:00:1f.6: ME failed to update for more than 1s, likely hung
[ 119.553762] intel ips 0000:00:1f.6: ME failed to update for more than 1s, likely hung
[ 119.789762] intel ips 0000:00:1f.6: ME failed to update for more than 1s, likely hung
[ 119.989762] intel ips 0000:00:1f.6: ME failed to update for more than 1s, likely hung
[ 120.189729] intel ips 0000:00:1f.6: ME failed to update for more than 1s, likely hung
[ 120.413728] intel ips 0000:00:1f.6: ME failed to update for more than 1s, likely hung
[ 120.617813] intel ips 0000:00:1f.6: ME failed to update for more than 1s, likely hung
[ 120.861672] intel ips 0000:00:1f.6: ME failed to update for more than 1s, likely hung
[ 121.073686] intel ips 0000:00:1f.6: ME failed to update for more than 1s, likely hung
[ 121.273654] intel ips 0000:00:1f.6: ME failed to update for more than 1s, likely hung
[ 121.605715] intel ips 0000:00:1f.6: ME failed to update for more than 1s, likely hung
[ 122.013690] intel ips 0000:00:1f.6: ME failed to update for more than 1s, likely hung
[ 122.457665] intel ips 0000:00:1f.6: ME failed to update for more than 1s, likely hung
[ 122.825652] intel ips 0000:00:1f.6: ME failed to update for more than 1s, likely hung
[ 123.101652] intel ips 0000:00:1f.6: ME failed to update for more than 1s, likely hung
[ 123.385634] intel ips 0000:00:1f.6: ME failed to update for more than 1s, likely hung
[ 123.597608] intel ips 0000:00:1f.6: ME failed to update for more than 1s, likely hung
[ 123.861608] intel ips 0000:00:1f.6: ME fai...