
| Affects | Status | Importance | Assigned to | Milestone | |
|---|---|---|---|---|---|
| ecryptfs-utils (Ubuntu) |
Invalid
|
High
|
Unassigned | ||
| Jaunty |
Invalid
|
High
|
Unassigned | ||
| linux (Ubuntu) |
Fix Released
|
High
|
Tim Gardner | ||
| Jaunty |
Fix Released
|
High
|
Tim Gardner | ||
Bug Description
I recently installed Kubuntu Jaunty on a new drive, using Ext4 for all my data.
The first time i had this problem was a few days ago when after a power loss ktimetracker's config file was replaced by a 0 byte version . No idea if anything else was affected.. I just noticed ktimetracker right away.
Today, I was experimenting with some BIOS settings that made the system crash right after loading the desktop. After a clean reboot pretty much any file written to by any application (during the previous boot) was 0 bytes.
For example Plasma and some of the KDE core config files were reset. Also some of my MySQL databases were killed...
My EXT4 partitions all use the default settings with no performance tweaks. Barriers on, extents on, ordered data mode..
I used Ext3 for 2 years and I never had any problems after power losses or system crashes.
Jaunty has all the recent updates except for the kernel that i don't upgrade because of bug #315006
ProblemType: Bug
Architecture: amd64
DistroRelease: Ubuntu 9.04
NonfreeKernelMo
Package: linux-image-
ProcCmdLine: root=UUID=
ProcEnviron:
LANGUAGE=
LANG=en_US.UTF-8
SHELL=/bin/bash
ProcVersionSign
SourcePackage: linux
Related branches

| Bogdan Gribincea (bogdan-gribincea) wrote : | #1 |
- BootDmesg.txt Edit (49.4 KiB, text/plain; charset="utf-8")
- CurrentDmesg.txt Edit (823 bytes, text/plain; charset="utf-8")
- Dependencies.txt Edit (977 bytes, text/plain; charset="utf-8")
- HalComputerInfo.txt Edit (3.2 KiB, text/plain; charset="utf-8")
- Lspci.txt Edit (13.1 KiB, text/plain; charset="utf-8")
- Lsusb.txt Edit (726 bytes, text/plain; charset="utf-8")
- ProcCpuinfo.txt Edit (2.9 KiB, text/plain; charset="utf-8")
- ProcInterrupts.txt Edit (1.7 KiB, text/plain; charset="utf-8")
- ProcModules.txt Edit (2.0 KiB, text/plain; charset="utf-8")
| Changed in linux: | |
| importance: | Undecided → High |
| status: | New → Triaged |
| Benjamin Hodgetts (enverex) wrote : | #2 |
| Benjamin Hodgetts (enverex) wrote : | #3 |
Additional: ext4 was implemented as a clean format, not an upgrade of any sort (backed up, formatted and copied back over).
| Matt Drake (mattduckman) wrote : | #4 |
This has happened to me twice, the first time erasing Firefox settings, and the second time erasing gnome-terminal settings. Both cases were caused by a kernel panic locking up the system. Also, both times the program whose settings were affected was in use during the kernel panic.
An important note is that these data losses have been taken place on an ext3 partition that is mounted as ext4 in fstab, so it is not a true ext4 partition.
This is taking place on fully up-to-date Jaunty.
| Pavel Rojtberg (rojtberg) wrote : | #5 |
I also had data loss with ext4. The "feature" responsible for this is delayed allocation.
With delayed allocation on all hd-writes are held back in memory, so if you just cut the power the data is lost.
Basically the old version should be still available, but perhaps ext4 decides that a zeroed file is more "consistent".
| Anders Aagaard (aagaande) wrote : | #6 |
Delayed allocation is to skip the allocating step when writing a file, not to keep data in memory. I'd say this is more likely to be related to barriers, but that's only because of my hate towards how ext handles barriers in a non safe way.
| Theodore Ts'o (tytso) wrote : | #7 |
Ben --- can you tell me what version of the kernel you are using? Since you are a Gentoo user, it's not obvious to me what version of the kernel you are using, and whether you have any ext4-related patches installed or not.
Bogden --- *any* files written during the previous boot cycle?
I've done some testing, using Ubuntu Interpid, and a stock (unmodified) 2.6.28 kernel on a Lenovo S10 netbook (my crash and burn machine; great for doing testing :-). On it, I created a fresh ext4 filesystem on an LVM partition, and I used as a test source a directory /home/worf, a test account that has been used briefly right after I installed it, so it has gnome dot files, plus a relatively small number of files in the Firefox cache. Its total size is 21 megabytes.
I then created a ext4 filesystem, and then tested it as follows:
% sudo bash
# cp -r /home/worf /mnt ; sleep 120; echo b > /proc/sysrq-trigger
After the system was forcely rebooted (the echo b >/proc/
How aggressively the system writes things back out to disk can be controlled via some tuning parameters, in particular /proc/sys/
So the bottom line is that I'm not able to replicate any data loss except for very recently written data before a crash, and this can be controlled by explicitly using the "sync" command or adjusting how aggressively the system writes back dirty pages via /proc/sys/
It would be useful if you could send me the output of "sysctl -a", and if you can tell me whether the amount of data that you are losing is decreased if you explicitly issue the "sync" command before the crash (which you can simulate via "echo b > /proc/sysctl-
| Benjamin Hodgetts (enverex) wrote : | #8 |
Kernel is Gentoo's own:
Linux defiant 2.6.28-gentoo #4 SMP Sat Jan 3 21:56:33 GMT 2009 x86_64 Intel(R) Core(TM)2 Quad CPU Q9450 @ 2.66GHz GenuineIntel GNU/Linux
The files that were zeroed when my machine hardlocked I'd imagine were the ones that were in use; my desktop env is Gnome and I was running a game in Wine. Wine's reg files which it would have had open were wiped and also my Gnome terminal settings were wiped. Not sure how often it would have been writing to them but it would have only been tiny amounts of data if it was.
| Pavel Rojtberg (rojtberg) wrote : | #9 |
in my case the zeroed files were also just updated, not created.
My "test scenario" was starting a OpenGL applications with unsaved source files. Then all graphics froze because of a bug in fglrx.
If I immediately powered off the machine my source file was empty. If I waited a bit everything was saved fine. Likely because I waited long enough for the changes to be written to disk...
| Bogdan Gribincea (bogdan-gribincea) wrote : | #10 |
Just to clarify, my Ext4 partitions were all 'true' ext4 not converted from ext3.
| Bogdan Gribincea (bogdan-gribincea) wrote : | #11 |
It happend again. Somehow when trying to logout KDM crashed. After rebooting I had some zeroed config files in a few KDE apps, log files (pidgin)..
I coverted / and /home back to EXT3. This is extremely annoying, reminds me of Windows 9x
I will have some free time next week and I'll try testing this in a virtual machine.
| Andy Whitcroft (apw) wrote : | #12 |
@Bogdan Gribincea -- am i correct in thinking that you are using the ext4 support in the Intrepid kernel?
| Bogdan Gribincea (bogdan-gribincea) wrote : | #13 |
@Andy: I am the bug report starter and I attached all the logs generated by the ubuntu-bug command.
And, no, it's Jaunty with it's 2.6.28 kernel and the 'stable' ext4 support. Also the partitions were created as ext4 on a new drive, not converted from ext3.
| Kai Mast (kai-mast) wrote : | #14 |
I can confirm this with AMD64 and Ubuntu Jaunty
| Niclas Lockner (niclasl) wrote : | #15 |
I have experienced some issues with EXT4 and data losses too, but more extreme than you all describe. I installed jaunty alpha 3 two days ago and have all the updates installed. Since the install 2 days ago I have lost data on 3 occations. The most strange losses is:
* the computer wiped out a whole network share mounted in fstab
* the computer one time also removed ~/.icons when I empty the trash
The data losses never happened after a crasch or power failure.
| Veovis (masterkedri) wrote : | #16 |
I was just browsing the forums on Ubuntu ( http://
Does this sound like it could have been the situation?
| Benjamin Hodgetts (enverex) wrote : | #17 |
No Veovis, please read the bug, that is nothing to do with the actual report here.
| Christian Roessner (christian-roessner-net) wrote : | #18 |
Just a question: Would data=journal in /etc/fstab be a workaround until this bug is fixed?
(Unfortunatlly I can not set this option in fstab for the root-partition, because initramfs does not support that feature!), but you may try this with your home and what-else partitions, if you do have them.
Data=journal deactivates delaloc. It should put data and metadata into the journal, thereof I hope that recently opened files should not have 0 bytes size. I do not put further comments here from my side. It´s just an idea.
| Andy Whitcroft (apw) wrote : | #19 |
Talking to Ted on this one we believe that the trigger for the data loss has been found and included in a new upstream stable update. The patches for ext4 have been picked up and applied to the jaunty kernel. Kernel 2.6.28-7.19 should contain those. If any of you are able to test and report back that would be most helpful.
| Changed in linux: | |
| assignee: | nobody → apw |
| status: | Triaged → Incomplete |
| Steve Langasek (vorlon) wrote : | #20 |
Should we mark this bug as 'fix released' unless someone shows otherwise?
| Christian Roessner (christian-roessner-net) wrote : | #21 |
Hi,
just updated my system. While this was in process, I tried to switch compiz to metacity (checking for another bug). The X-server froze and I switched to tty2 to stop gdm. This took a long time and afterwards even the Xorg process hang. I entered reboot, but the system could not reboot in the last third of the stop procedure. I used SysRequest+s, -u, -b.
After reboot I saw: /home was unmounted unclean, check forced.
When I came into gnome again, my compiz settings were partially cleared and my gnome-terminal settings were lost. I can not say, if the files were zero bytes. But maybe the e2fsck had corrupted some files.
The updates that had taken place did not include compiz or gnome-terminal so at this point I can not see a connection to the updates done and the lost information.
| Christian Roessner (christian-roessner-net) wrote : | #22 |
Ok, thunderbird settings are gone, too. So this seems ext4 related?
| pablomme (pablomme) wrote : | #23 |
@Christian: I understand that your system hung _before_ you rebooted into the updated kernel? If so, the changes wouldn't have taken effect, and the data loss was caused by the original kernel.
| Tim Gardner (timg-tpi) wrote : | #24 |
This issue should be fixed with 2.6.28-7.18. I cherry picked a number of patches that Ted Tso is submitting for stable kernel updates which he says fixes this data loss problem. Please confirm.
| Changed in linux: | |
| assignee: | apw → timg-tpi |
| status: | Incomplete → Fix Released |
| Christian Roessner (christian-roessner-net) wrote : Re: [Bug 317781] Re: Ext4 data loss | #25 |
pablomme schrieb:
> @Christian: I understand that your system hung _before_ you rebooted
> into the updated kernel? If so, the changes wouldn't have taken effect,
> and the data loss was caused by the original kernel.
Well, there has not been any kernel update so far here. I am on:
2.6.28-7.20 for several days now. The problem I spoke about was today
with the specified kernel.
So are the patches applied to this version or a leter one, which has not
arrived here, yet?
Else the problem persists.
| Peter Clifton (pcjc2) wrote : | #26 |
I'm using 2.6.28-8-generic and a crash just zeroed out a _load_ of important files in my git repository which I'd recently rebased a patch series in.
Not impressed (TM).
Oh well.. anyway.. I don't think this problem is fixed.
| André Barmasse (barmassus) wrote : | #27 |
For testing I installed ext4 together with Jaunty Alpha 4 as standard root file system on my Sony Vaio. Since then I had four hardlocks, two of them completely destroying my gnome desktop. So far, this only happens within Gnome while upgrading the system with apt-get in a shell AND at the same time running and working with other programms (like quodlibet, firefox, Thunderbird, Bluefish etc.).
As of the gnome desktop destructions, in one case apt-get unfortunately was just installing some xorg-server files and - in the other case - configuring the gnome-desktop, when the hard lock happened. The sad part is that I didn't find a way to repair the broken system neither with apt-get nor with dpkg nor with aptitute as the size some needed configuration files was set to zero by the crash. So, for now I am switching back to ext4 releasing this warning:
DON'T DO ANYTHING WHILE UPGRADING UBUNTU WITH EXT4!
| David Tomaschik (matir) wrote : | #28 |
Looks like the data loss bug may still exist. Setting back to confirmed.
| Changed in linux: | |
| status: | Fix Released → Confirmed |
| pablomme (pablomme) wrote : | #29 |
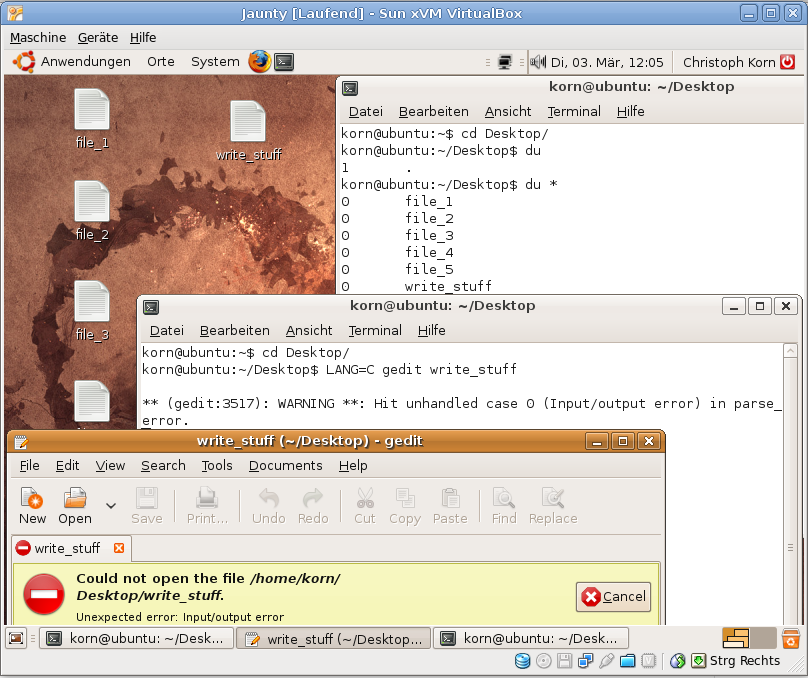
- write_stuff.gz Edit (768 bytes, application/octet-stream)
I think this bug is in desperate need of a systematic test, so I've attached a script which attempts to do precisely that. You need to run the script like this:
./write_stuff <directory-
The script will open 5 files (named 'file_<i>') under the specified directory and start appending one line per second to each of them, until you stop it with Ctrl-C. If the script is re-run, lines are appended to the previous contents.
If instead of stopping the script you turn off or reboot your computer by force (say with SysRq+B, or holding the power button), you would be reproducing the conditions under which the bug seems to occur.
My / partition is ext4 (but not my /home, so I haven't suffered this bug as much as others have). Running the script on '/test' without any initial files and rebooting with SysRq+B gave:
- rebooting in 30 seconds resulted in all 5 files zeroed
- rebooting in 45 seconds resulted in 4 files having 40 lines and one having 41
- rebooting in 60 seconds resulted in 4 files having 55 lines and one having 56
I would think that the first data flush on the initially-empty files takes too long to occur. This would explain the problems other people are having if the configuration files they mention are deleted and rewritten from scratch, and the system crashes before the first flush. Or maybe I'm completely wrong in my interpretation, so go ahead and do your own tests.
Hope this helps!
| Jeremy LaCroix (jlacroix82-deactivatedaccount) wrote : | #30 |
I never had any trouble, but I installed Jaunty last week, after the fix
was released. Is it possible this bug now only affects those that
installed it prior to the fix? When did you guys install it?
I've moved over 100GB of files since I installed it. I had at least two
hard crashes, everything seems to be intact.
André Barmasse wrote:
> For testing I installed ext4 together with Jaunty Alpha 4 as standard
> root file system on my Sony Vaio. Since then I had four hardlocks, two
> of them completely destroying my gnome desktop. So far, this only
> happens within Gnome while upgrading the system with apt-get in a shell
> AND at the same time running and working with other programms (like
> quodlibet, firefox, Thunderbird, Bluefish etc.).
>
> As of the gnome desktop destructions, in one case apt-get unfortunately
> was just installing some xorg-server files and - in the other case -
> configuring the gnome-desktop, when the hard lock happened. The sad part
> is that I didn't find a way to repair the broken system neither with
> apt-get nor with dpkg nor with aptitute as the size some needed
> configuration files was set to zero by the crash. So, for now I am
> switching back to ext4 releasing this warning:
>
> DON'T DO ANYTHING WHILE UPGRADING UBUNTU WITH EXT4!
>
| pablomme (pablomme) wrote : | #31 |
@Jeremy: I've never had a problem either, but I haven't had any crashes at all so this bug hasn't had a chance to show up. However my script above does reproduce the problem - have you tried it?
I installed Jaunty Alpha 4 on February the 6th. I would suppose that this is equivalent to what you've done, since you only get the updates after having installed the system. (Alpha 5 is not out yet, is it?)
| Jeremy LaCroix (jlacroix82-deactivatedaccount) wrote : | #32 |
I've not experienced the bug yet, though I've not had a chance to try
the script yet.
I was wondering if anyone knows of a terminal command I could run that
would give me a list of all the files on my system that are 0 KB. As far
as I know, I've never experienced this, but then again it may have
happened to a file I don't use often. I don't care if I lose anything
since I have everything backed up but a command to list files that may
have been effected would be nice if anyone knows.
| pablomme (pablomme) wrote : | #33 |
> I was wondering if anyone knows of a terminal command I could run that
> would give me a list of all the files on my system that are 0 KB.
There's
find / -type f -size 0
but there are very many files that have zero length under normal conditions, so it'll be very hard to tell if any file has been affected this way.
| Wade Menard (wade-ezri) wrote : | #34 |
find / -size 0b should be enough. Please keep further discussion not related to fixing this bug on a forum or mailing list.
| Jeremy LaCroix (jlacroix82-deactivatedaccount) wrote : | #35 |
Thank you. Please understand that my question was related to this bug,
as such a command will help me determine if this bug is affecting me,
then I could give more info that would help the fix.
Wade Menard wrote:
> find / -size 0b should be enough. Please keep further discussion not
> related to fixing this bug on a forum or mailing list.
>
| Jeremy LaCroix (jlacroix82-deactivatedaccount) wrote : | #36 |
There are a couple files that are 0b, so this bug is affecting me. Is
there any information I can provide to help the developers?
Wade Menard wrote:
> find / -size 0b should be enough. Please keep further discussion not
> related to fixing this bug on a forum or mailing list.
>
| Michael Rooney (mrooney) wrote : | #37 |
Jeremy, as pablomme said: "there are very many files that have zero length
under normal conditions, so it'll be very hard to tell if any file has been
affected this way."
Many people are reporting trashed gnome sessions so it should be fairly
obvious whether it is or not. A 0b file is definitely not indicative of
this.
| Jeremy LaCroix (jlacroix82-deactivatedaccount) wrote : | #38 |
The two files I have that are 0b are jpg images.
Michael Rooney wrote:
> Jeremy, as pablomme said: "there are very many files that have zero length
> under normal conditions, so it'll be very hard to tell if any file has been
> affected this way."
>
> Many people are reporting trashed gnome sessions so it should be fairly
> obvious whether it is or not. A 0b file is definitely not indicative of
> this.
>
| kubrentu (brentkubuntu) wrote : | #39 |
Same data loss problem.
Installed Kubuntu Jaunty Alpha 4. ext4 as root / partition. Did all the updates.
$ uname -a
Linux andor 2.6.28-8-generic #26-Ubuntu SMP Wed Feb 25 04:28:54 UTC 2009 i686 GNU/Linux
ran the "write_stuff" script, and held down the power button after about 5-10 seconds.
brent@andor:~/test$ ls -l
total 4
-rw-r--r-- 1 brent brent 0 2009-02-26 13:38 file_1
-rw-r--r-- 1 brent brent 0 2009-02-26 13:38 file_2
-rw-r--r-- 1 brent brent 0 2009-02-26 13:38 file_3
-rw-r--r-- 1 brent brent 0 2009-02-26 13:38 file_4
-rw-r--r-- 1 brent brent 0 2009-02-26 13:38 file_5
-rw-r--r-- 1 brent brent 1411 2009-02-26 13:32 write_stuff
All 0B files.
I'm happy to try other tests that people may suggest.
| 3vi1 (launchpad-net-eternaldusk) wrote : | #40 |
Ack... had a power outage and ran into this one today too. Several configuration files from programs I was running ended up trashed. This also explains the corruption I've seen of my BOINC/SETI files when hard-rebooting in past weeks.
System: Linux mars 2.6.28-8-generic #26-Ubuntu SMP Wed Feb 25 04:27:53 UTC 2009 x86_64 GNU/Linux
I'm running RAID1 dmraid mirroring w/ an Asus Striker Formula II MB, in case it matters.
| Changed in ecryptfs-utils: | |
| importance: | Undecided → High |
| status: | New → Invalid |
| Changed in linux: | |
| milestone: | none → ubuntu-9.04-beta |
| status: | Confirmed → Fix Committed |
| Changed in linux: | |
| status: | Fix Committed → Fix Released |
|
147 comments hidden
Loading more comments
|
view all 227 comments |
| helios (martin-lichtvoll) wrote : | #188 |
Daniel Philipps, developer of Tux3 filesystem, wants to make sure that renames come after file being written even when delayed writing of metadata is introduced to it:
http://
| Jamin W. Collins (jcollins) wrote : | #189 |
I know this report claims that a fix is already in Jaunty for this issue. However, I just found myself with a 0 byte configuration file after a system lockup (flashing caps lock).
$ uname -ra
Linux odin 2.6.28-11-generic #37-Ubuntu SMP Mon Mar 23 16:40:00 UTC 2009 x86_64 GNU/Linux
| Theodore Ts'o (tytso) wrote : | #190 |
@189: Jamin,
The fix won't protect against a freshly written new file (configuration or otherwise); it only protects against a file which is replaced via rename or truncate. But if it was a file that previously didn't exist, then you can still potentially get a zero-length file --- just as you can crash just before the file was written out.
| Jamin W. Collins (jcollins) wrote : | #191 |
@Theo
The file in question was a previously existing configuration file for my IM client (gajim). All IM accounts and preferences were lost. Not a huge deal, but definitely a preexisting file. The system kernel panicked (flashing caps lock) while chatting. The kernel panic is a separate issue that's been reported previously.
| Rocko (rockorequin) wrote : | #192 |
@Theo: I vote for what (I think) lots of people are saying: if the file system delays writing of data to improve performance, it should delay renames and truncates as well so you don't get *complete* data loss in the event of a crash... Why have a journaled file system if it allows you to lose both the new *and* the old data on a crash rather than just the new data that couldn't be written in time?
It's true that this situation won't happen if the system never crashes, and it's great that this is true of your system - but in that case, why not just use ext2?
If ext3 also allows this, I'd say there's a problem with ext3 too.
Incidentally, I just ended up with a ton of trashed object files due to a kernel panic in the middle of a build. But I wouldn't say gcc is a crappy application!
PS. Other than this bug, ext4 rocks.
| Theodore Ts'o (tytso) wrote : | #193 |
@Rocko,
If you really want this, you can disable delayed allocation via the mount option, "nodelalloc". You will take a performance hit and your files will be more fragmented. But if you have applications which don't call fsync(), and you have an unstable system, then you can use the mount option. All I can say is that I don't see these data loss problems, but everyone has different usage patterns.
In terms of trashed object files in the middle of the build, those object files are non-precious files. How often do you crash in the middle of a build? Should you slow down all builds just to handle the rare case where your system crashes in the middle of the build? Or would it be better to run "make clean", and rebuild the tree in the case where you have trashed object files? It's not like a kernel rebuild takes that long. OTOH, if your system is crashing all the time, there's something else seriously wrong; Linux systems shouldn't be that unstable.
| Theodore Ts'o (tytso) wrote : | #194 |
@Jamin,
We'd have to see how gaim is rewriting the application file. If it is doing open/truncate/
| Jamin W. Collins (jcollins) wrote : | #195 |
@Theo,
Been digging through the source to track down how it does it. Managed to find it. It does use a central consistent method, which does use a tempfile. However, it does not (as of yet) force a sync. I'm working on getting that added to the code now. Here's the python routine it uses:
self.__filename: the full path to the user's configuration file.
self.__tempfile: the same path and filename but with a dot prefix
def write(self):
(base_dir, filename) = os.path.
self.__tempfile = os.path.
try:
f = open(self.
except IOError, e:
return str(e)
try:
gajim.
except IOError, e:
return str(e)
f.close()
if os.path.
# win32 needs this
try:
os.
except Exception:
pass
try:
os.rename(
except IOError, e:
return str(e)
os.chmod(
| Aryeh Gregor (simetrical+launchpad) wrote : | #196 |
That looks like it removes the file before it does the rename, so it misses the special overwrite-by-rename workaround. This is slightly unsafe on any filesystem, since you might be left with no config file with the correct name if the system crashes in a small window, fsync() or no. Seemingly Python on Windows doesn't support an atomic rename operation at all.
It might be simplest for it to only do the remove if rename throws an OSError, or only if the platform is Windows. Ideally it should call fsync() as well, of course.
| Daniel Colascione (dcolascione) wrote : | #197 |
What that code does is stupid, yes. It shouldn't remove the original unless the platform is win32. *Windows* (except with Transactional NTFS) doesn't support an atomic rename, so it's no surprise that Python under Windows doesn't either.
You're seeing a zero-length file because Tso's fix for ext4 only applies to files being renamed on top of other files. The filesystem should be fixed to allocate blocks on *every* commit, not just ones overwriting existing files.
As for the program -- fsync should *not* be inserted. (Though the unconditional os.remove() should be changed.) It's a bad thing to ritually fsync every file before the rename for a host of reasons described upthread. Just fix the filesystem.
| Theodore Ts'o (tytso) wrote : | #198 |
@Daniel,
Note that if you don't call fsync(), and you hence you don't check the error returns from fsync(), your application won't be notified about any possible I/O errors. So that means if the new file doesn't get written out due to media errors, the rename may also end up wiping out the existing file. This can be an issue with some remote file systems, like AFS, where you'll miss quota errors unless you fsync() and check the error returns on both fsync() and close(). But hey, if you don't care about that, feel free to write your applications any way you want.
| Aryeh Gregor (simetrical+launchpad) wrote : | #199 |
"The filesystem should be fixed to allocate blocks on *every* commit, not just ones overwriting existing files."
alloc_on_commit mode has been added. Those who want to use it (and take the large associated performance hit) can use it. It's a tradeoff that is and should be in the hands of the individual system administrator. Personally, my machine almost never crashes, so I'd prefer the extra performance.
What the application is doing in this case is broken anyway, and if it fixed that there would be no problem on ext4.
"As for the program -- fsync should *not* be inserted. (Though the unconditional os.remove() should be changed.) It's a bad thing to ritually fsync every file before the rename for a host of reasons described upthread."
fsync() should preferably be used for config file updates, assuming those are reasonably rare, "for a host of reasons described upthread". Otherwise, the user will click "Save" and then the preference change won't actually take effect if the system crashes shortly thereafter. This is true in any filesystem. On some filesystems (not just ext4: XFS certainly, maybe NFS?), you might also get some kind of other bad stuff happening. Explicit user saving of files/preferenc
If Gaim updates its config file very often for some reason, though, they'd have to weigh the added reliability of fsync() against the performance hit (especially on filesystems like ext3).
| Daniel Colascione (dcolascione) wrote : | #200 |
If you accept that it makes sense to allocate on rename commits for overwrites of *existing* files, it follows that it makes sense to commit on *all* renames. Otherwise, users can still see zero-length junk files when writing a file out for the first time. If an application writes out a file using the atomic rename technique, it should expect just as good a consistency guarantee when the file doesn't already exist as when it does. Anything else just adds extra complexity.
Before your knee jerks out "performance," consider that brand-new, throwaway files aren't renamed. gcc doesn't write a file out, only to rename it immediately. Only files for which atomicty matters are renamed that way -- which are precisely the files that would get the commit-on-rename treatment in other circumstances. The performance impact of committing on *all* renames would be minimal over the existing rename code.
We keep talking in circles: if you're going to make a commitment to application reliability, go all the way and commit on all renames. Anything else is just a subtle gotcha for application programs. Yes, POSIX them harder, will you?
NFS is a special case in that 1) it's widely known to have strange semantics, and 2) many applications explicitly don't support NFS for that reason. NFS semantics are *not* the ones we should be striving to emulate! Besides, the kind of inconsistency you see with NFS doesn't result in corrupt configurations in the same way the ext4 bug does.
As for AFS: it has a special place in Hell. AFS doesn't even meet basic POSIX guarantees with regard to permissions. Its mind-bendingly stupid quota behavior is just icing on the cake. It's crap as a unix filesystem, and I sure as hell wouldn't consider using it except on a specially-prepared system. I'm not going to make my application jump through hoops to support your antiquated hack. Every other filesystem checks quotas on write and close; why does yours have to be different?
| Aryeh Gregor (simetrical+launchpad) wrote : | #201 |
"If you accept that it makes sense to allocate on rename commits for overwrites of *existing* files, it follows that it makes sense to commit on *all* renames."
Renaming a new file over an existing one carries the risk of destroying *old* data. If I create a new file and don't rename it to anything, it's possible I will lose *the new file only*, on any filesystem (unless I fsync()). This is universally considered an acceptable risk: losing up to a couple of minutes' work (but nothing earlier) in the event of a system crash. This is the exact risk carried by renaming a file to a name that doesn't exist -- unless you gratuitously delete the old file first, which is completely pointless on Unix and obviously destroys any hope of atomicity (if the system crashes/app dies/etc. between delete and rename).
"Only files for which atomicty matters are renamed that way -- which are precisely the files that would get the commit-on-rename treatment in other circumstances."
Virtually all users of this atomicity technique appear to rename over the existing file, which is why almost all problems disappeared when users applied Ted's patches. Gaim only did otherwise as a flawed attempt to work around a quirk of the Windows API, in a way that wasn't atomic anyway, and that can be expected to be fixed in Gaim.
| Daniel Colascione (dcolascione) wrote : | #202 |
The risk isn't data loss; if you forgo fsync, you accept the risk of some data loss. The issue that started this whole debate is consistency.
The risk here is of the system ending up in an invalid state with zero-length files *THAT NEVER APPEARED ON THE RUNNING SYSTEM* suddenly cropping up. A zero-length file in a spot that is supposed to be occupied by a valid configuration file can cause problems --- an absent file might indicate default values, but an empty file might mean something completely different, like a syntax error or (famously) "prevent all users from logging into this system."
When applications *really* do is create a temporary file, write data to it, and rename that temporary file to its final name regardless of whether the original exists. If the filesystem doesn't guarantee consistency for a rename to a non-existing file, the application's expectations will be violated in unusual cases causing hard-to-discover bugs.
Why should an application that atomically updates a file have to check whether the original exists to get data consistency?
Allocate blocks before *every* rename. It's a small change from the existing patch. The performance downsides are minimal, and making this change gives applications the consistency guarantees they expect.
Again: if you accept that you can give applications a consistency guarantee when using rename to update the contents of a file, it doesn't make sense to penalize them the first time that file is updated (i.e., when it's created.) Unless, of course, you just want to punish users and application developers for not gratuitously calling fsync.
| Chow Loong Jin (hyperair) wrote : | #203 |
On Fri, 2009-03-27 at 22:55 +0000, Daniel Colascione wrote:
> The risk isn't data loss; if you forgo fsync, you accept the risk of
> some data loss. The issue that started this whole debate is consistency.
>
> The risk here is of the system ending up in an invalid state with zero-
> length files *THAT NEVER APPEARED ON THE RUNNING SYSTEM* suddenly
> cropping up. A zero-length file in a spot that is supposed to be
> occupied by a valid configuration file can cause problems --- an absent
> file might indicate default values, but an empty file might mean
> something completely different, like a syntax error or (famously)
> "prevent all users from logging into this system."
A syntax error usually prevents the whole program from running, I should
think. And I'm not sure about the whole "prevent all users from logging
into this sytem" bit. I've never even heard of it, so I don't know how
you can consider that famous.
> When applications *really* do is create a temporary file, write data to
> it, and rename that temporary file to its final name regardless of
> whether the original exists. If the filesystem doesn't guarantee
> consistency for a rename to a non-existing file, the application's
> expectations will be violated in unusual cases causing hard-to-discover
> bugs.
It is guaranteed. When you *rename onto an existing file*. If you delete
the original *before* renaming, then I see it as "you have agreed to
forgo your atomicity".
>
> Why should an application that atomically updates a file have to check
> whether the original exists to get data consistency?
Um, no, I don't think it needs to. See this:
Case 1: File already exists.
1. Application writes to file.tmp
2. Application closes file.tmp
3. Application renames file.tmp to file.
** If a crash happens, you either get the original, or the new.
Case 2: File doesn't already exist.
1-3 as above.
** If a crash happens, you either get the new file, or a zero-length
file.
Considering that in case 2 there wasn't a file to begin with, I don't
think it's much of an issue in getting a zero-length file. Unless your
program crashes when you get zero-length configuration files, in which
case I think your program sucks and you suck for writing it with that
assumption.
>
> Allocate blocks before *every* rename. It's a small change from the
> existing patch. The performance downsides are minimal, and making this
> change gives applications the consistency guarantees they expect.
I wholeheartedly agree with "Allocate blocks before renames over
existing files", but "Allocate blocks before *every* rename" is
overdoing it a little.
>
> Again: if you accept that you can give applications a consistency
> guarantee when using rename to update the contents of a file, it doesn't
> make sense to penalize them the first time that file is updated (i.e.,
> when it's created.) Unless, of course, you just want to punish users and
> application developers for not gratuitously calling fsync.
Again, I don't see exactly how an application is being penalized the
first time the file is updated.
--
Chow Loong Jin
| Daniel Colascione (dcolascione) wrote : | #204 |
First of all, the program under discussion got it wrong. It shouldn't have unlinked the destination filename. But the scenario it unwittingly created is *identical* to the first-time creation of a filename via a rename, and that's a very important case. EVERY program will encounter it the first time it creates a file via an atomic rename. If the system dies at the wrong time, the program will see a zero-length file in place of the one it just wrote.
This is your scenario two. This is *NOT* about data loss. If the program cared about data loss, it'd use fsync(), dammit. This is about consistent state.
The program didn't put that zero-length file there. Why should it be expected to handle it? It's perfectly reasonable to barf on a zero-length file. What if it's XML and needs a root element? What if it's a database that needs metadata? It's unreasonable to expect every program and library to be modified to not barf on empty files *it didn't write* just like it's unreasonable to modify every program to fsync gratuitously. Again -- from the point of view of the program on a running system, there was at *NO TIME* a zero-length file. Why should these programs have to deal with them mysteriously appearing after a crash?
Okay, and now what about XFS? XFS fills files with NULL instead of truncating them down to zero length (technically, it just makes the whole file sparse, but that's beside the point.) Do programs need to specially handle the full-of-NULLs case too? How many hoops will they have to go through just to pacify sadistic filesystems?
A commit after every rename has a whole host of advantages. It rounds out and completes the partial guarantee provided by a commit after an overwriting rename. It completely prevents the appearance of a garbage file regardless of whether a program is writing the destination for the first or the nth time. It prevents anyone from having to worry about garbage files at all.
It's far better to fix a program completely than to get it right 99% of the time and leave a sharp edge hiding in some dark corner. Just fix rename.
And what's the downside anyway? High-throughput applications don't rename brand-new files after they've just created them anyway.
As for no users being able to log in -- I was referring to an old BSD network daemon. But for a more modern example, how about cron.deny? If cron.deny does not exist, only root can use cron. If cron.deny exists *AND IS EMPTY*, all users can use cron.
| Rocko (rockorequin) wrote : | #205 |
I agree with Daniel - consistency should be a primary objective of any journaling file system.
Would it be possible to do something like store both the old and new inodes when a rename occurs, and to remove the old inode when the data is written? This way it could operate like it is currently, except that after a system crash it would be able to see that the new inode is invalid and restore the old one instead.
| Jamin W. Collins (jcollins) wrote : | #206 |
@Theo
Sorry for the false alarm. Filed it as soon as I found the 0 byte file while still investigating the source. I've since created and submitted a patch (via launchpad, https:/
| Rocko (rockorequin) wrote : | #207 |
@Theo: would it be hard to implement something like I suggested, ie storing rename backup metadata for crash recovery? I think in the discussion on your blog someone says that reiserfs already does this via 'save links' (comment 120).
Alternatively, if there were a barrier to all renames instead of just ones that overwrite an existing file, would that stop the zero-length files issue, ie make the file system consistent in the event of a crash? I imagine that this would only impact on performance for applications that create very large files and then rename them before the data is written to disk, which seems a very unusual case.
| André Barmasse (barmassus) wrote : | #208 |
Hello together
Just reporting some observations after making a brand new installation of Ubuntu 9.04 with ext4 as default file system on my Sony Vaio VGN-FS195VP. Since the installation some days ago I had again four hard locks, but luckily - despite my experiences some weeks ago - without any data loss. All of them happened with the standard installation of Ubuntu on the Gnome desktop.
One hard lock happened when listening internet radio with quodlibet in the background and trying to update Ubuntu via Synaptics. Another one when trying to rip a dvd with wine and dvdshrink in the background and trying to open other applications (Firefox, Bluefish, gFTP) almost at the same time. The other two happended when trying to remove some ISO files of DVDs (together maybe about 12 GB data) from the trash. The trash icon on the desktop turned empty (actuallly a good sign), but about five seconds later the entire system crashed .
The Kernel running on my system is 2.6.28-11-generic and the Gnome version is 2.6.28-11-generic. Since I am not a very technical guy, I have not applied any of the above mentioned remedies. But as I am very happy with ext4 as my default file system (and have not yet experienced data loss!) I will keep it hoping that there will be some fixes in the next Kernel.
Thanks for all your explanations about ext4, Theodore Ts'o, and keep up the good work!
| Rocko (rockorequin) wrote : | #209 |
@André: you might be experiencing one or two different bugs that are possibly related to ext4 in the Jaunty kernel - see https:/
To try and avoid the hard lockups, I've installed the 2.6.30.rc3 kernel from the weekly Ubuntu kernel builds since it has the patches in this bug applied to stop truncated files on a crash and the file deletion bug is fixed. So far so good.
| André Barmasse (barmassus) wrote : | #210 |
Hi
Thanks for your answers, Rocko. Today I have installed the Karmic Koala Alpha 1 with Kernel 2.6.30-5-generic, and it seems that all the former problems with ext4 are gone. For testing purposes I have created 5 big dvd iso files (together about 30 GB of data), moved them around in the system, copyied and deleted them three or four times, and - as a final barrier - emptyied the trash with meanwhile around 120 GB of data in it. Everything went smoothly without the system tottering for even one second!! Great work, guys!!
| Rocko (rockorequin) wrote : | #211 |
No worries, André! Some more feedback on 2.6.30: I've been using 2.6.30-rc3 then 2.6.30-rc5 without problems in Jaunty for several weeks now (I used to get kernel panics at least twice a week with 2.6.28) and am now trying 2.6.30-rc6. Still so far so good.
| Jose Bernardo (bernardo-bandos) wrote : | #212 |
I just subscribed this bug as I started seeing this behaviour with 2.6.30-rc6 on my aspire one. First it was the 0 length files after a crash (the latest intel drivers still hang sometimes at suspend/resume or at logout/shutdown, and only the magic REISUB gets you out of it), and once I saw my /home mounted R/O because of a ext4 error (unfortunately didn't save dmesg) and after the fsck had again 0 byte files (mostly in my firefox profile, as I was web browsing at the time). Next time I get this bug I'll post here the dmesg.
Some possibly relevant points:
I formated both my / and my /home partitions clean with mkfs.ext4.
I have / on the internal ssd, and /home on a sdhc 8GB card.
I have 1.5GB RAM and no swap (to save some wear and tear on the flash memory).
| Jose Bernardo (bernardo-bandos) wrote : | #213 |
Now I didn't even had a crash, but on reboot my kdewallet.kwl file was empty. I removed it, and in syslog I got the following:
"EXT4-FS warning (device mmcblk0p1): ext4_unlink: Deleting nonexistent file (274), 0
| Jose Bernardo (bernardo-bandos) wrote : | #214 |
| Jose Bernardo (bernardo-bandos) wrote : | #215 |
- dmesg2.txt Edit (42.8 KiB, text/plain)
And after another clean shutdown and a reboot, I finally had to reformat my home partition and restore it from a backup, as the fsck gave a huge amount of errors and unlinked inodes. Gone back to ext3, will wait for 2.6.30 final before new tests. Here is the final dmesg to just after the fsck. As with the previous one, I just removed my AP mac address for privacy reasons.
| Theodore Ts'o (tytso) wrote : | #216 |
Jose, please open a separate bug, as this is an entirely different problem. (I really hate Ubuntu bugs that have a generic description, because it seems to generate "Ubuntu Launchpad Syndrome" --- a problem which seems to cause users to search for bugs, see something that looks vaguely similar, and then they add a "me too" to a bug, instead of opening a new bug.)
Launchpad simply doesn't scale, and it's painful as all heck to deal with a bug with 200 comments. And this is entirely unrelated to the problem that people were dealing with --- and which has been solved in the Ubuntu kernels and in 2.6.29.
The errors you are reporting are entirely consistent with this which I found earlier in your dmesg:
[ 7.531490] EXT4-fs warning: mounting fs with errors, running e2fsck is recommended
I'm guessing you didn't set up your /etc/fstab correctly so that the filesystem on your /dev/mmcblk0p1 (i.e., your SD card) would have e2fsck run on reboot when it had errors. That would certainly be consistent with the dmesg log which you showed.
As for what caused the problem, I'm not entirely sure. One things is for sure, though --- you need to fix up your filesystem first, and I would recommend that you check out your /etc/fstab to make sure that the filesystem is checked at boot-up if it needs it. That means the fsck pass field of /etc/fstab needs to be non-zero. In any case, please open a new bug, and put a pointer in this launchpad bug to the new bug so people who are interested can follow you to the new bug. Thanks!
| Jose Bernardo (bernardo-bandos) wrote : | #217 |
Ok, I'll try installing 2.6.30 final for ubuntu and report a new bug. As for the fsck, the only time I didn't boot into single user mode and ran fsck by hand was that one. My fstab entry is simple - "LABEL=Home /home ext4 relatime,defaults 0 0", and most errors I had were data corruption after a crash/hang, as most reporters here, so that is why I reported it here. I've now changed the 6th field to 2 to make sure it is checked at boot if needed.
Anyway, as I said I reformatted my sd card as ext3 and won't try ext4 on it until 2.6.30 final, so until then I'll keep quiet.
| corneliupa (corneliupa) wrote : | #218 |
Would it be possible to create sync policies (per distribution, per user, per application) and ensure like this a flexibility/
| Lamont Granquist (lamont-scriptkiddie) wrote : | #219 |
ted ts'o:
"You can opine all you want, but the problem is that POSIX does not specify anything ..."
I'll opine that POSIX needs to be updated.
The use of the create-
There is now an expectation that filesystems have transactional behavior. Deal with it. If it isn't explicitly part of POSIX then POSIX needs to be updated in order to reflect the actual realities of how people are using Unix-like systems these days -- POSIX was not handed down from God to Linus on the Mount. It can and should be amended. And this should not damage the performance benefits of doing delayed writes. Just because you have to be consistent doesn't mean that you have to start doing fsync()s for me all the time. If I don't explictly call fsync()/fdatasync() you can hold the writes in memory for 30 minutes and abusively punish me for not doing that explicitly myself. But just delay *both* the data and metadata writes so that I either get the full "transaction" or I don't. And stop whining about how people don't know how to use your precious filesystem.
| Steffen Neumann (sneumann) wrote : | #220 |
Hi,
I am also bitten by the above ecryptfs messages slowly filling my /var/log and
have a followup question to the cleanup workaround presented by Dustin in comment #57
of this bug:
Is there any way to determine (=decrypt) which files have been messed up,
so I know if there is anything important, which I have to grab from the backup
before that expires and gets overwritten ? In other words:
$ umount.
$ cd $HOME/.Private
$ mount.ecryptfs_
$ find . -size 0c | xargs ecryptfs-
Yours,
Steffen
| Steffen Neumann (sneumann) wrote : | #221 |
I have added a separate bug for the problem of (de-)crypting filenames,
see https:/
Yours,
Steffen
| Steffen Neumann (sneumann) wrote : | #222 |
Hi,
I found a workaround to the problem of determining the cleartext filenames.
*Before* you delete the zero-byte files, back 'em up:
1) tar find .Private -size 0b | xargs tar -czvf zerofiles.tgz
2) Unmount your encrypted home
3a) Temporarily move the "good" files away:
mv .Private .Private-real
3b) and restore the "broken" ones:
tar xzvf zerofiles.tgz
4) remount your encrypted home
The files will not be usable, but at least you know their names
5a) Unmount your unusable encrypted home
5b) restore the "good" encrypted files:
mv .Private .Private-broken
mv .Private-real .Private
6) Remount and continue.
My last problem: I *still* have 5 files for which I get
the "Valid eCryptfs headers not found in file header region or xattr region"
error. Since I purged all -size 0b files (verified!) I'd like to know
how to track those ones down. Is there another find expression
that can nail those down ? Any other debugging option I could/should
enable to find these 5 files ?
Yours,
Steffen
| Rgpublic (rgpublic) wrote : | #223 |
Installed Karmic with ext4 on a new PC today. Installed FGLRX afterwards. All of a sudden the PC froze completely. No mouse-movement, no keyboard. Hard reset. After reboot lots of configuration files that were recently changed had zero length. The system became unusable due to this (lots of error messages in dpkg etc). Installed again on ext3. No problems ever since. I wonder why this is installed by default as Ubuntu is supposed to be a user-friendly distro. Is it really necessary to squeeze out the last bit of extra performance for the sake of data security? This is certainly not desired for a desktop system. At least an explicit warning that this could happen should appear during installation.
| Jobo (arkazon) wrote : | #224 |
Can someone point me toward documentation for "data=alloc_
I am getting 0 byte files after system freezes on Ubuntu 10.04.01 (amd64) with kernel version 2.6.32-25. Just want to understand how one uses alloc_on_commit and how it works before I use it, and I can't find any proper documentation for it, just a few brief mentions in articles and forum postings.
Thanks.
| Lukas (lukas-ribisch) wrote : | #225 |
As far as I understand, the problem has been fixed for overwriting by rename and overwriting by truncate. Is it an issue at all for just overwriting part of a file, without truncating it first?
I realize that there are basically no guarantees when fsync() is not used, but will such writes to already allocated blocks be written on every commit interval (by default 5 seconds)?
Or can the changes possibly remain in the cache much longer, since there is no chance of metadata corruption? (It would seem that the inode wouldn't have to change except for modification time, and unlike for newly allocated blocks, there is also no security issue, since the owner of the file can only get access to his own stale data after a crash, not somebody else's, as it would be with newly allocated blocks.)
| Patola (patola) wrote : | #226 |
Shouldn't this problem be closed by now if this bug was fixed?
| Kai Mast (kai-mast) wrote : | #227 |
Feel free to close this. The bug has not affected me in over a decade.
{kind=link}
I thought it was worth adding this, even though I'm running Gentoo, it seems to be exactly the same issue:
I recently upgraded to ext4 as well, I ran a game in Wine and the system hardlocked (nothing special there with the fglrx drivers). After rebooting all my Wine registry files were 0 bytes, as were many of my Gnome configuration files. Absoloute nightmare. fsck on boot said that it had removed 760+ orphaned inodes.
Mounted as:
/dev/root on / type ext4 (rw,noatime,