
Instance/VM Console is not opened, Horizon is getting back with Network Error (tcp_error)
| Affects | Status | Importance | Assigned to | Milestone | |
|---|---|---|---|---|---|
| StarlingX |
Invalid
|
Low
|
Erich Cordoba | ||
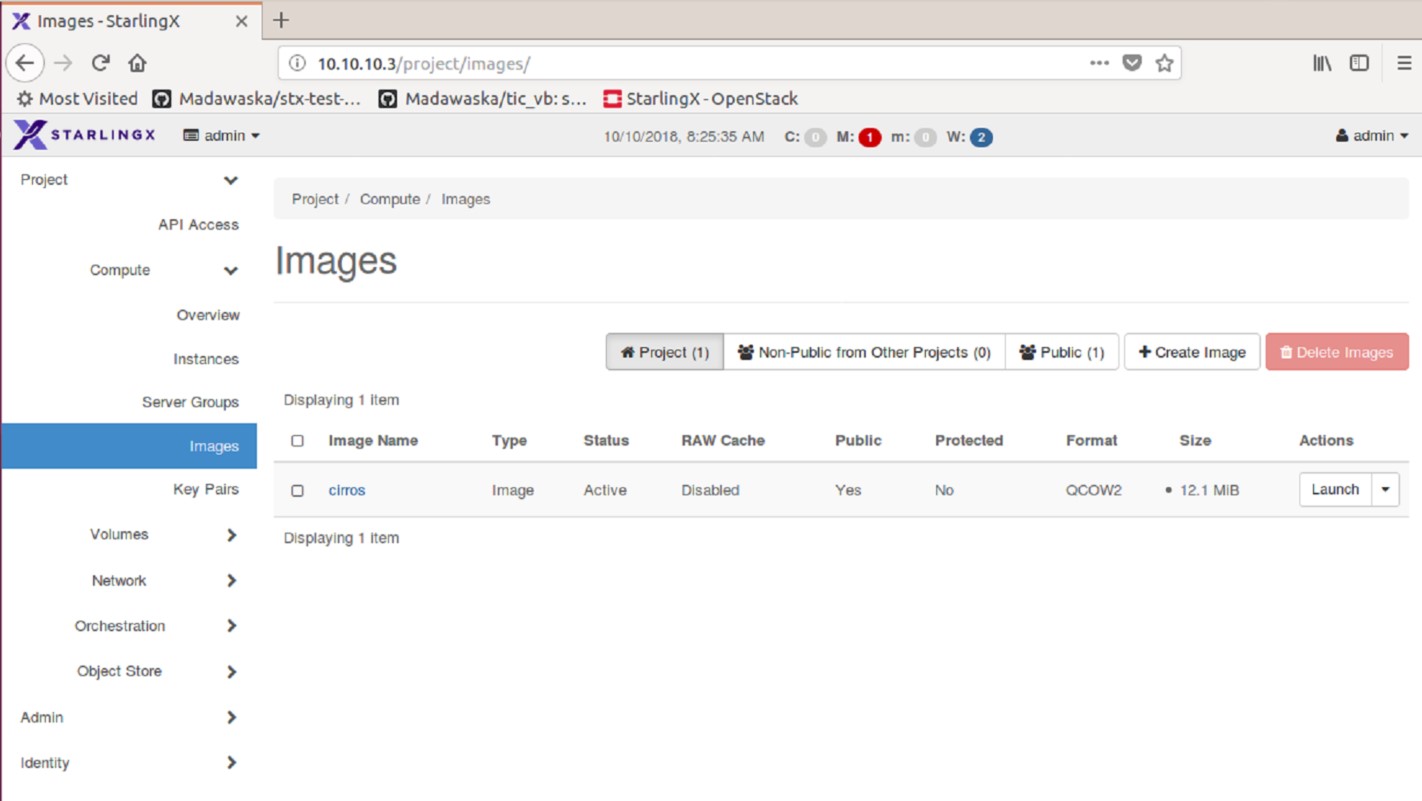
Bug Description
Brief Description
-----------------
After Image,flavor,
Severity
--------
Critical: VMs are not able to be used.
Steps to Reproduce
------------------
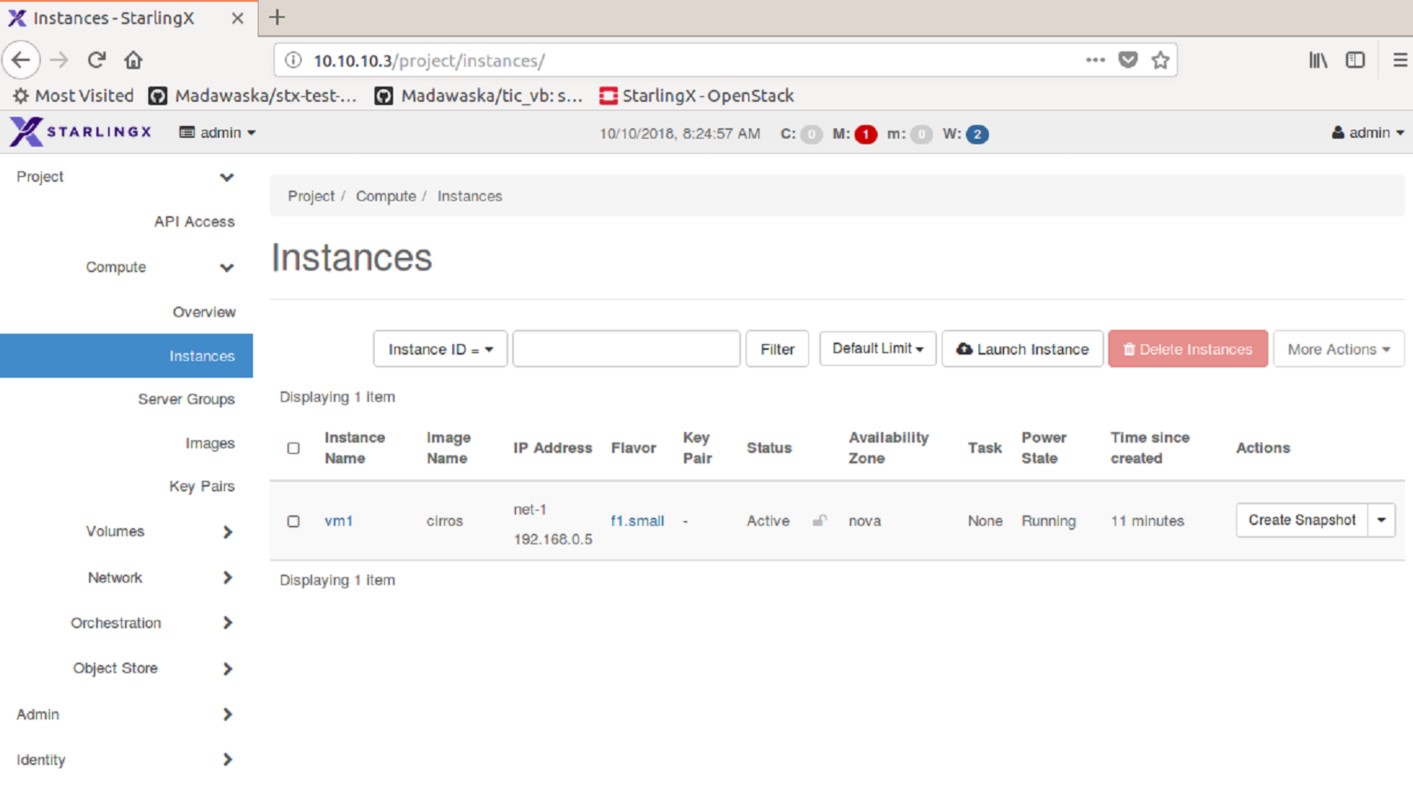
Create an instace following next steps on active conrtoller:
source /etc/nova/openrc
wget http://
openstack flavor create --public --id 1 --ram 512 --vcpus 1 --disk 4 m1.tiny
openstack image create --file cirros-
openstack network create --shared net
openstack subnet create --network net --ip-version 4 --subnet-range 192.168.0.0/24 --dhcp net-subnet1
openstack server create --flavor m1.tiny --image cirros --nic net-id=uuid vm1
Expected Behavior
------------------
After we create an instance/VM we should be able to open the prompt console and start working on it.
Actual Behavior
----------------
Prompt console is not able to be opened.
Reproducibility
---------------
This issue is 100% reproducible.
System Configuration
-------
Virtual Multinodo Dedicated Ceph storage: 2 Controllers, 2 computes, 3 storage over IPV4 link [0]
Timestamp/Logs
--------------
Provide a snippet of logs if available and the timestamp when issue was seen.
Please indicate the unique identifier in the logs to highlight the problem
Provide a pointer to the logs for debugging (use attachments in Launchpad or paste.openstack
[0] https:/

{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Changed in starlingx: | |
| importance: | Undecided → Medium |
{kind=link}
| Changed in starlingx: | |
| status: | New → In Progress |
In Virtual Multinode - Going through "cat /var/log/
This is what i found:
cat /var/log/
2018-10-10 13:13:53.552 7379 INFO nova.filters [req-8b5076c3-
...
2018-10-10 13:13:54.194 7379 INFO nova.scheduler.
...