
{kind=link}
© 2004
Canonical Ltd.
•
Terms of use
•
Data privacy
•
Contact Launchpad Support
•
Blog
•
Careers
•
System status
•
0e1f616
(Get the code!)
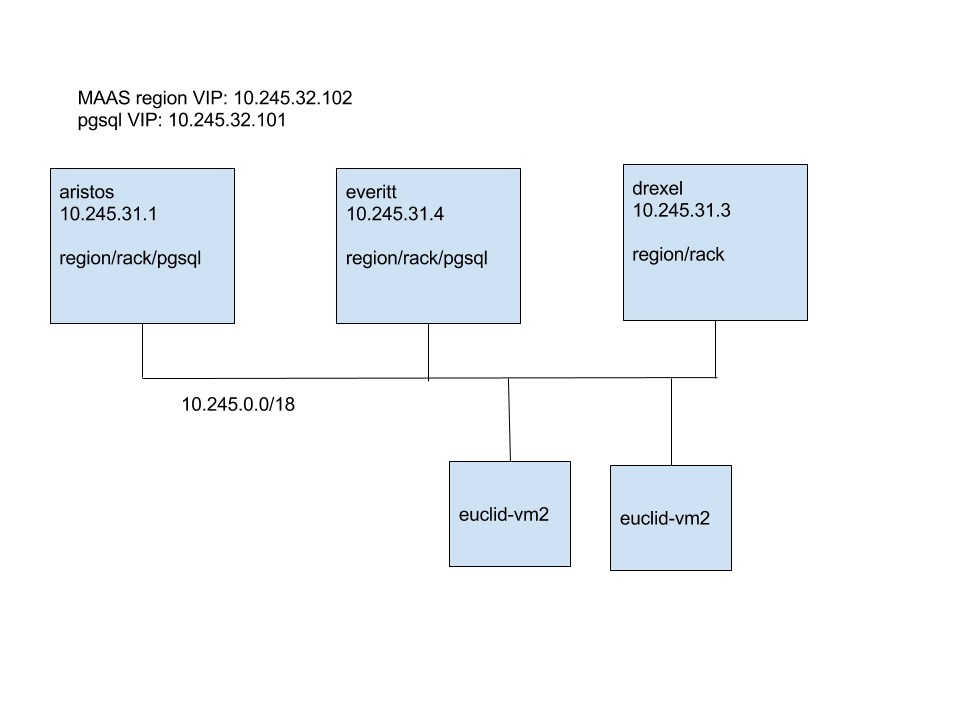
I've attached a drawing of my setup, I hope that helps. 10.245.31.4
(everitt) is the isolated controller in this test.
On Tue, Feb 6, 2018 at 3:53 PM, Andres Rodriguez
<email address hidden> wrote:
> 4. How long was it from the time the network partition was confirmed to the time the machine attempted to boot?
The first time through, what's in the logs, I started the deploy about
a minute after the rack controller lost its connection to the region
controllers.
It continued to try to boot and fail for about 20 minutes, at which
point I released the node. 45 minutes later now, I tried to deploy
the node again and I'm getting the same behavior - the isolated rack
controller is still providing dhcp.
> 5. After the machine failed to boot, did the rack controller continued providing DHCP ?
Yes.
> 6. Did the rack controller at all fully disconnected for *all* regions?
There is a region controller running on the same node as it which it
may still be able to talk to, but I don't think it's connected to it,
because it can't talk to the region's vip to get /rpc to find where it
should connect to. Even if it could, that region controller can't
talk to the DB, so it would be worthless. It can not talk to either
of the working region controllers.
> --
> You received this bug notification because you are subscribed to the bug
> report.
> https:/
>
> Title:
> [2.3, ha] rack controller HA fails during a network partition
>
> Status in MAAS:
> Incomplete
>
> Bug description:
> I have an HA setup with 3 MAAS controllers, each running rack
> controllers and region controllers.
>
> On two of the three controllers, I used iptables to drop traffic from
> the third, to simulate a network partition.
>
> Then I instructed MAAS to deploy a node. The node powered on fine,
> but when it started PXE booting, the third isolated rack controller
> responded to the DHCP request, gave it an IP, and told it to talk to
> it via tftp to get its pxelinux.cfg.
>
> That rack controller was unable to provide the pxelinux.cfg because it
> couldn't reach the region controller via the VIP due to the network
> partition, and the node failed to PXE boot.
>
> I think that the isolated rack controller should not be running DHCP.
> If a rack controller can't reach the region controller, it can't
> handle PXE booting a node, and shouldn't try. If it would not have
> responded, one of the functional rack controllers would have and it
> would be fine.
>
> In the attached logs, 10.245.31.4 is the node that was isolated. I
> started the isolation at about 21:15.
>
> This is with 2.3.0-6434-
>
> To manage notifications about this bug go to:
> https:/