
Ryzen 1800X freeze - rcu_sched detected stalls on CPUs/tasks
| Affects | Status | Importance | Assigned to | Milestone | |
|---|---|---|---|---|---|
| Linux |
Expired
|
Medium
|
|||
| linux (Ubuntu) |
Confirmed
|
High
|
Unassigned | ||
Bug Description
Hi,
We aregetting various kernel crash on a pretty new config.
We're using Ryzen 1800X CPU with X370 Gaming Pro Carbon MB (7A32V1) using latest BIOS available (1.52)
We are running Ubuntu 17.04 (amd64), we've tried different kernel version, native one and releases from http://
Tested kernel version:
native 17.04 kernel
4.10.15
Issues are the same, we're getting random freeze on the machine.
Here is kern.log entry when happening :
May 10 22:41:56 dev2 kernel: [24366.186246] INFO: rcu_sched detected stalls on CPUs/tasks:
May 10 22:41:56 dev2 kernel: [24366.187618] 0-...: (1 GPs behind) idle=49b/1/0 softirq=28561/28563 fqs=913449
May 10 22:41:56 dev2 kernel: [24366.188977] (detected by 12, t=1860207 jiffies, g=10001, c=10000, q=4656)
May 10 22:41:56 dev2 kernel: [24366.190344] Task dump for CPU 0:
May 10 22:41:56 dev2 kernel: [24366.190345] swapper/0 R running task 0 0 0 0x00000008
May 10 22:41:56 dev2 kernel: [24366.190348] Call Trace:
May 10 22:41:56 dev2 kernel: [24366.190354] ? native_
May 10 22:41:56 dev2 kernel: [24366.190355] ? default_
May 10 22:41:56 dev2 kernel: [24366.190358] ? arch_cpu_
May 10 22:41:56 dev2 kernel: [24366.190360] ? default_
May 10 22:41:56 dev2 kernel: [24366.190362] ? do_idle+0x16f/0x200
May 10 22:41:56 dev2 kernel: [24366.190364] ? cpu_startup_
May 10 22:41:56 dev2 kernel: [24366.190366] ? rest_init+0x77/0x80
May 10 22:41:56 dev2 kernel: [24366.190368] ? start_kernel+
May 10 22:41:56 dev2 kernel: [24366.190369] ? early_idt_
May 10 22:41:56 dev2 kernel: [24366.190371] ? x86_64_
May 10 22:41:56 dev2 kernel: [24366.190372] ? x86_64_
May 10 22:41:56 dev2 kernel: [24366.190373] ? start_cpu+0x14/0x14
May 10 22:44:56 dev2 kernel: [24546.188093] INFO: rcu_sched detected stalls on CPUs/tasks:
May 10 22:44:56 dev2 kernel: [24546.189461] 0-...: (1 GPs behind) idle=49b/1/0 softirq=28561/28563 fqs=935027
May 10 22:44:56 dev2 kernel: [24546.190823] (detected by 14, t=1905212 jiffies, g=10001, c=10000, q=4740)
May 10 22:44:56 dev2 kernel: [24546.192191] Task dump for CPU 0:
May 10 22:44:56 dev2 kernel: [24546.192192] swapper/0 R running task 0 0 0 0x00000008
May 10 22:44:56 dev2 kernel: [24546.192195] Call Trace:
May 10 22:44:56 dev2 kernel: [24546.192199] ? native_
May 10 22:44:56 dev2 kernel: [24546.192201] ? default_
May 10 22:44:56 dev2 kernel: [24546.192203] ? arch_cpu_
May 10 22:44:56 dev2 kernel: [24546.192204] ? default_
May 10 22:44:56 dev2 kernel: [24546.192206] ? do_idle+0x16f/0x200
May 10 22:44:56 dev2 kernel: [24546.192208] ? cpu_startup_
May 10 22:44:56 dev2 kernel: [24546.192210] ? rest_init+0x77/0x80
May 10 22:44:56 dev2 kernel: [24546.192211] ? start_kernel+
May 10 22:44:56 dev2 kernel: [24546.192213] ? early_idt_
May 10 22:44:56 dev2 kernel: [24546.192214] ? x86_64_
May 10 22:44:56 dev2 kernel: [24546.192215] ? x86_64_
May 10 22:44:56 dev2 kernel: [24546.192217] ? start_cpu+0x14/0x14
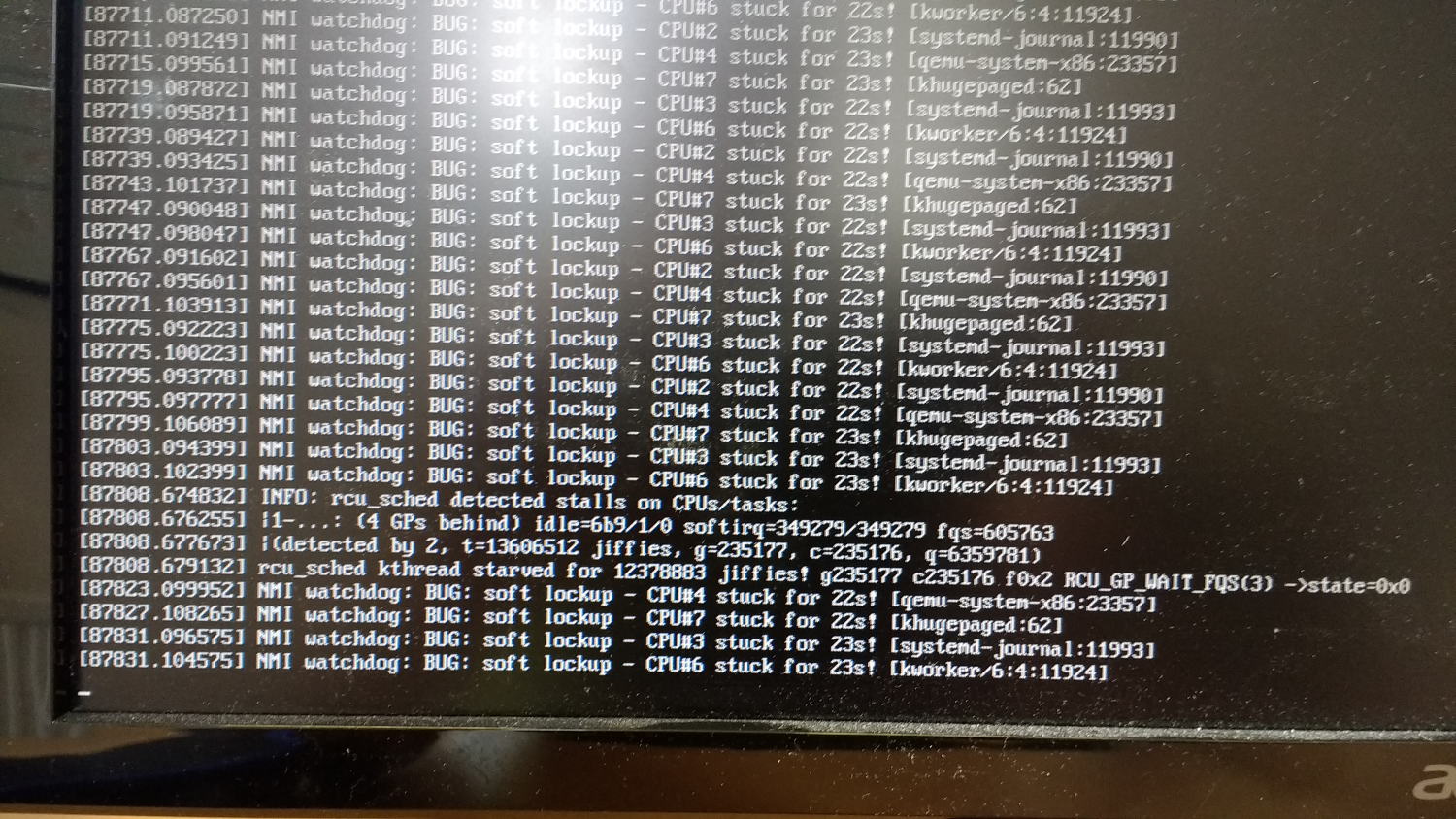
Depending on the kernel version, we've got NMI watchdog errors related to CPU stuck (mentioning the CPU core id, which is random).
Crash is happening randomly, but in general after some hours (3-4h).
Now, we've installed kernel 4.11.0-
For now, the machine is not "used", at least, it's not CPU stressed...
Thanks
---
ApportVersion: 2.20.4-0ubuntu4
Architecture: amd64
DistroRelease: Ubuntu 17.04
InstallationDate: Installed on 2017-05-09 (1 days ago)
InstallationMedia: Ubuntu-Server 17.04 "Zesty Zapus" - Release amd64 (20170412)
Package: linux (not installed)
ProcEnviron:
TERM=xterm-
PATH=(custom, no user)
XDG_RUNTIME_
LANG=fr_FR.UTF-8
SHELL=/bin/bash
Tags: zesty
Uname: Linux 4.11.0-
UnreportableReason: The running kernel is not an Ubuntu kernel
UpgradeStatus: No upgrade log present (probably fresh install)
UserGroups:
_MarkForUpload: True

| Changed in linux (Ubuntu): | |
| status: | Triaged → Invalid |
{kind=link}
| tags: | removed: kernel-da-key |
| information type: | Public → Public Security |
| information type: | Public Security → Public |
| Changed in linux: | |
| importance: | Unknown → Medium |
| status: | Unknown → Confirmed |
| tags: | added: cscc |
| Changed in linux: | |
| status: | Confirmed → Expired |
This bug is missing log files that will aid in diagnosing the problem. From a terminal window please run:
apport-collect 1690085
and then change the status of the bug to 'Confirmed'.
If, due to the nature of the issue you have encountered, you are unable to run this command, please add a comment stating that fact and change the bug status to 'Confirmed'.
This change has been made by an automated script, maintained by the Ubuntu Kernel Team.