We are running multiple clusters.
The cluster that frequently scale-in and out sometimes fail to join the cluster.
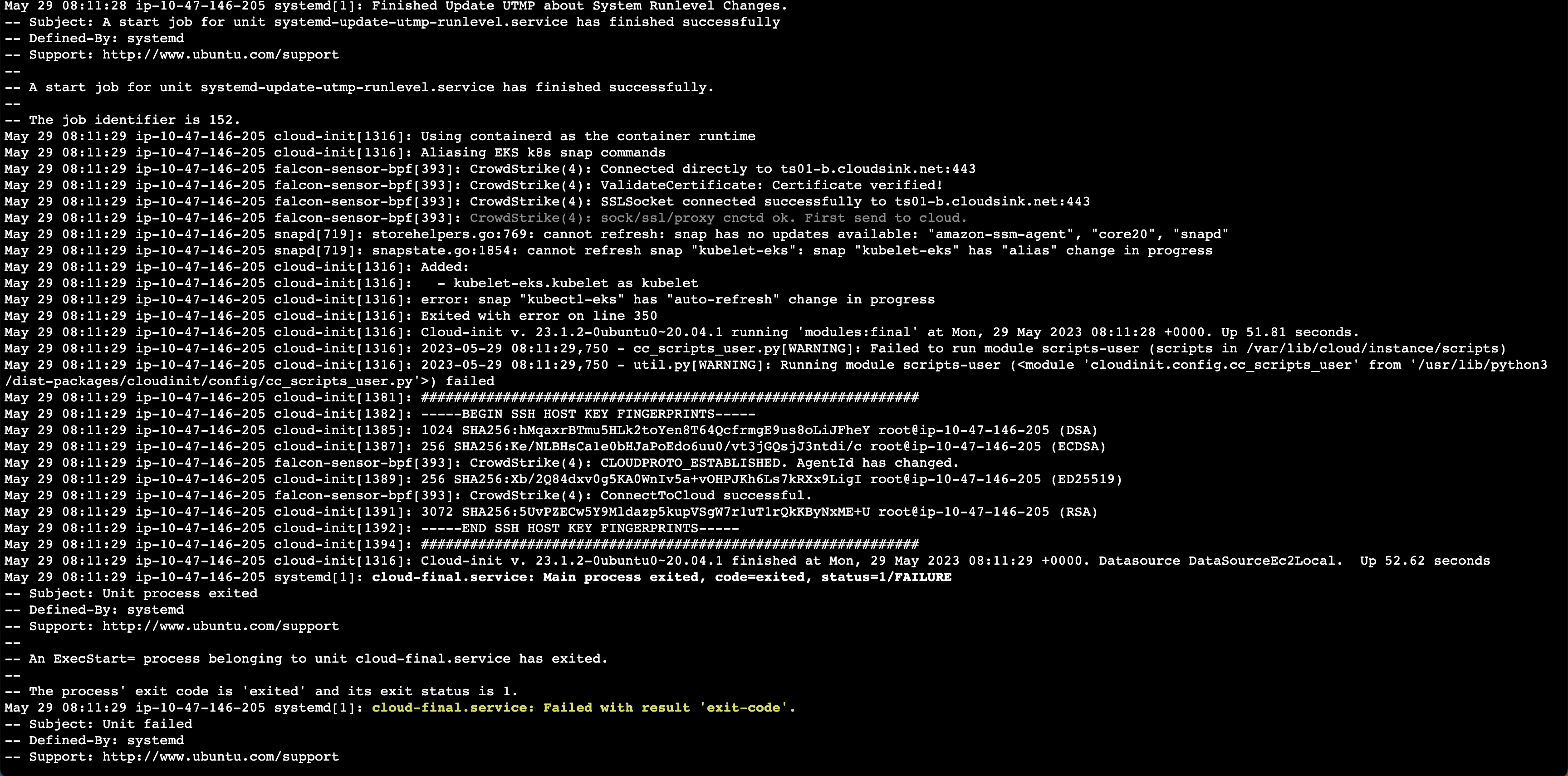
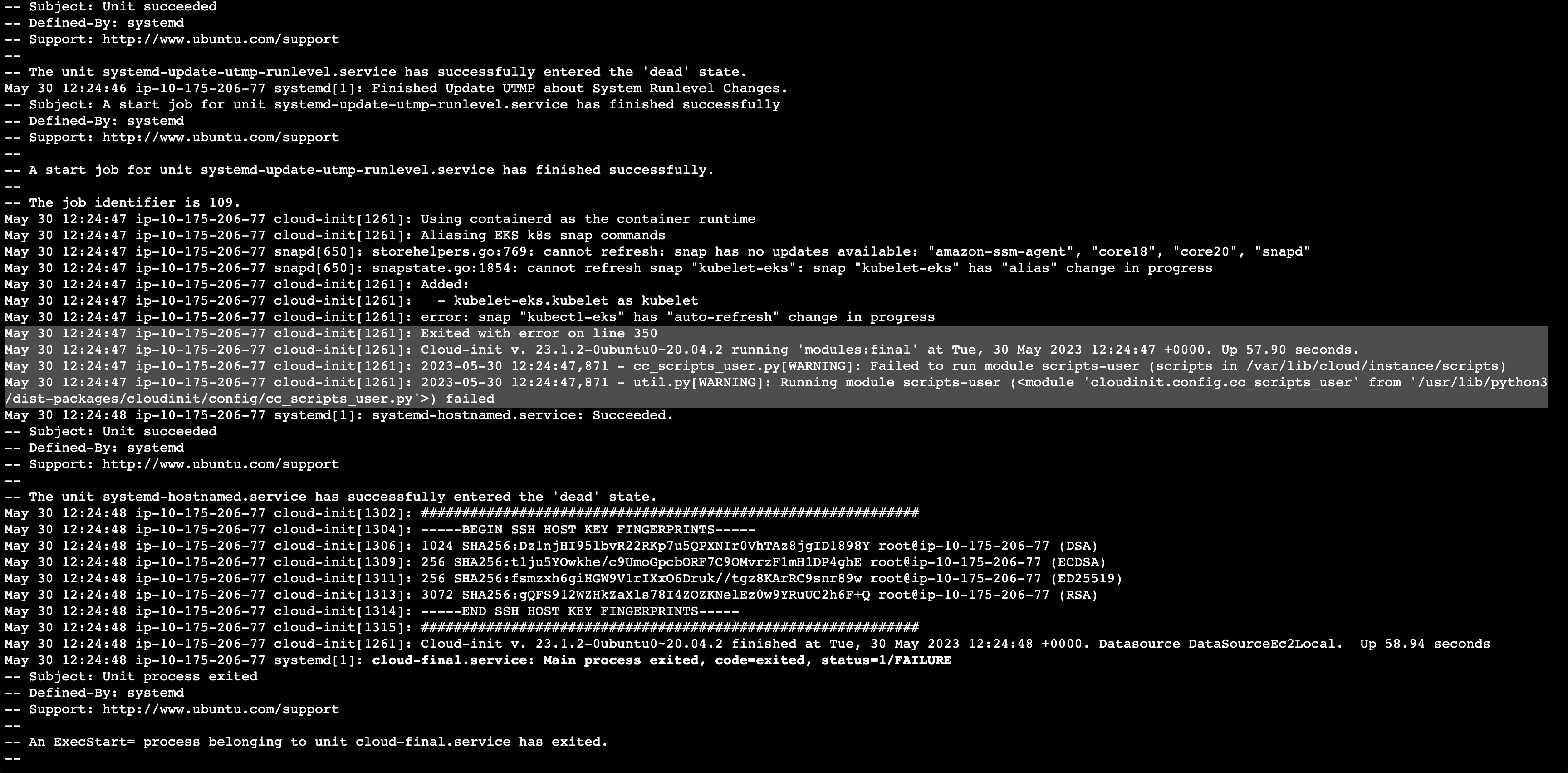
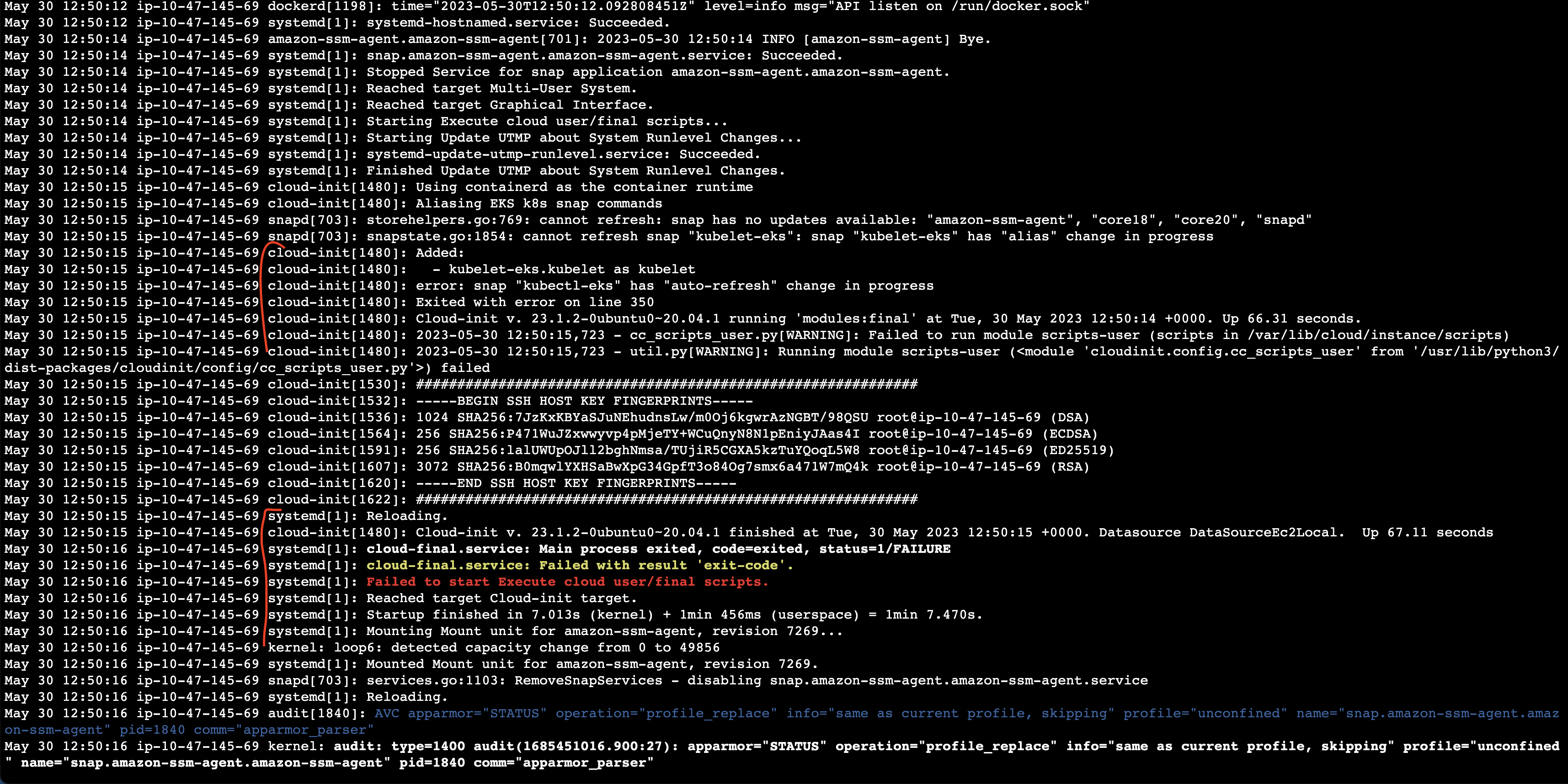
Looking at /var/log/user-data.log, running `snap start kubelet-eks` in /etc/eks/bootstrap.sh returns fail. Looking at journalctl, it seems as that is running without specifying kubelet's arguments at all.
If I manually run /etc/eks/bootstrap.sh after the nodes are orphaned, the cluster joins just fine.
I think this is a timing issue related to the snap and argument settings.
Using 1.24 AMI with ami-04c00a6fc53487c5a
Some interesting log for snap does not read argument:
kubelet-eks.daemon[935]: cat: /var/snap/kubelet-eks/92/args: No such file or directory
kubelet runs fail same errors:
kubelet-eks.daemon[889]: I0307 19:24:58.886750 889 util_unix.go:104] "Using this format as endpoint is deprecated, please consider using full url format." deprecatedFormat="" fullURLFormat="unix://"
kubelet-eks.daemon[889]: W0307 19:24:58.888995 889 clientconn.go:1331] [core] grpc:
Certains logs from journalctl:
systemd[1]: Started containerd container runtime.
systemd[1]: Started Service for snap application amazon-ssm-agent.amazon-ssm-agent.
systemd[1]: Reloading.
systemd[1]: Started Service for snap application kubelet-eks.daemon.
systemd[1]: Started snap.kubelet-eks.hook.configure.3540f36b-29a1-4974-8c41-31995a6c637e.scope.
kubelet-eks.daemon[935]: cat: /var/snap/kubelet-eks/92/args: No such file or directory
amazon-ssm-agent.amazon-ssm-agent[833]: Error occurred fetching the seelog config file path: open /etc/amazon/ssm/seelog.xml: no such file or directory
amazon-ssm-agent.amazon-ssm-agent[833]: Initializing new seelog logger
amazon-ssm-agent.amazon-ssm-agent[833]: New Seelog Logger Creation Complete
amazon-ssm-agent.amazon-ssm-agent[833]: 2023-03-07 19:24:53 WARN Error adding the directory '/etc/amazon/ssm' to watcher: no such file or directory
amazon-ssm-agent.amazon-ssm-agent[833]: 2023-03-07 19:24:53 INFO Proxy environment variables:
amazon-ssm-agent.amazon-ssm-agent[833]: 2023-03-07 19:24:53 INFO https_proxy:
amazon-ssm-agent.amazon-ssm-agent[833]: 2023-03-07 19:24:53 INFO http_proxy:
amazon-ssm-agent.amazon-ssm-agent[833]: 2023-03-07 19:24:53 INFO no_proxy:
amazon-ssm-agent.amazon-ssm-agent[833]: 2023-03-07 19:24:53 INFO Agent will take identity from EC2
amazon-ssm-agent.amazon-ssm-agent[833]: 2023-03-07 19:24:53 INFO [amazon-ssm-agent] using named pipe channel for IPC
amazon-ssm-agent.amazon-ssm-agent[833]: 2023-03-07 19:24:53 INFO [amazon-ssm-agent] using named pipe channel for IPC
amazon-ssm-agent.amazon-ssm-agent[833]: 2023-03-07 19:24:53 INFO [amazon-ssm-agent] using named pipe channel for IPC
amazon-ssm-agent.amazon-ssm-agent[833]: 2023-03-07 19:24:53 INFO [amazon-ssm-agent] amazon-ssm-agent - v3.1.1732.0
amazon-ssm-agent.amazon-ssm-agent[833]: 2023-03-07 19:24:53 INFO [amazon-ssm-agent] OS: linux, Arch: amd64
amazon-ssm-agent.amazon-ssm-agent[833]: 2023-03-07 19:24:53 INFO [CredentialRefresher] Identity does not require credential refresher
amazon-ssm-agent.amazon-ssm-agent[833]: 2023-03-07 19:24:54 INFO [amazon-ssm-agent] [LongRunningWorkerContainer] [WorkerProvider] Worker ssm-agent-worker is not running, starting worker process
amazon-ssm-agent.amazon-ssm-agent[833]: 2023-03-07 19:24:54 INFO [amazon-ssm-agent] [LongRunningWorkerContainer] [WorkerProvider] Worker ssm-agent-worker (pid:948) started
amazon-ssm-agent.amazon-ssm-agent[833]: 2023-03-07 19:24:54 INFO [amazon-ssm-agent] [LongRunningWorkerContainer] Monitor long running worker health every 60 seconds
systemd[1]: snap.kubelet-eks.hook.configure.3540f36b-29a1-4974-8c41-31995a6c637e.scope: Succeeded.
dbus-daemon[531]: [system] Activating via systemd: service name='org.freedesktop.timedate1' unit='dbus-org.freedesktop.timedate1.service' requested by ':1.9' (uid=0 pid=539 comm="/usr/lib/snapd/snapd " label="unconfined")
systemd[1]: Starting Time & Date Service...
dbus-daemon[531]: [system] Successfully activated service 'org.freedesktop.timedate1'
systemd[1]: Started Time & Date Service.
systemd[1]: Started Kubernetes systemd probe.
kubelet-eks.daemon[889]: I0307 19:24:58.858562 889 server.go:399] "Kubelet version" kubeletVersion="v1.24.9"
kubelet-eks.daemon[889]: I0307 19:24:58.858619 889 server.go:401] "Golang settings" GOGC="" GOMAXPROCS="" GOTRACEBACK=""
kubelet-eks.daemon[889]: I0307 19:24:58.858841 889 server.go:562] "Standalone mode, no API client"
systemd[1]: run-r5647ef4c140746af8f68048b9b657df0.scope: Succeeded.
kubelet-eks.daemon[889]: I0307 19:24:58.886249 889 server.go:450] "No api server defined - no events will be sent to API server"
kubelet-eks.daemon[889]: I0307 19:24:58.886266 889 server.go:648] "--cgroups-per-qos enabled, but --cgroup-root was not specified. defaulting to /"
kubelet-eks.daemon[889]: I0307 19:24:58.886544 889 container_manager_linux.go:262] "Container manager verified user specified cgroup-root exists" cgroupRoot=[]
kubelet-eks.daemon[889]: I0307 19:24:58.886618 889 container_manager_linux.go:267] "Creating Container Manager object based on Node Config" nodeConfig={RuntimeCgroupsName: SystemCgroupsName: KubeletCgroupsName: KubeletOOMScoreAdj:-999 ContainerRuntime: CgroupsPerQOS:true CgroupRoot:/ CgroupDriver:cgroupfs KubeletRootDir:/var/lib/kubelet ProtectKernelDefaults:false NodeAllocatableConfig:{KubeReservedCgroupName: SystemReservedCgroupName: ReservedSystemCPUs: EnforceNodeAllocatable:map[pods:{}] KubeReserved:map[] SystemReserved:map[] HardEvictionThresholds:[{Signal:nodefs.inodesFree Operator:LessThan Value:{Quantity:<nil> Percentage:0.05} GracePeriod:0s MinReclaim:<nil>} {Signal:imagefs.available Operator:LessThan Value:{Quantity:<nil> Percentage:0.15} GracePeriod:0s MinReclaim:<nil>} {Signal:memory.available Operator:LessThan Value:{Quantity:100Mi Percentage:0} GracePeriod:0s MinReclaim:<nil>} {Signal:nodefs.available Operator:LessThan Value:{Quantity:<nil> Percentage:0.1} GracePeriod:0s MinReclaim:<nil>}]} QOSReserved:map[] ExperimentalCPUManagerPolicy:none ExperimentalCPUManagerPolicyOptions:map[] ExperimentalTopologyManagerScope:container ExperimentalCPUManagerReconcilePeriod:10s ExperimentalMemoryManagerPolicy:None ExperimentalMemoryManagerReservedMemory:[] ExperimentalPodPidsLimit:-1 EnforceCPULimits:true CPUCFSQuotaPeriod:100ms ExperimentalTopologyManagerPolicy:none}
kubelet-eks.daemon[889]: I0307 19:24:58.886635 889 topology_manager.go:133] "Creating topology manager with policy per scope" topologyPolicyName="none" topologyScopeName="container"
kubelet-eks.daemon[889]: I0307 19:24:58.886644 889 container_manager_linux.go:302] "Creating device plugin manager" devicePluginEnabled=true
kubelet-eks.daemon[889]: I0307 19:24:58.886706 889 state_mem.go:36] "Initialized new in-memory state store"
kubelet-eks.daemon[889]: I0307 19:24:58.886750 889 util_unix.go:104] "Using this format as endpoint is deprecated, please consider using full url format." deprecatedFormat="" fullURLFormat="unix://"
kubelet-eks.daemon[889]: W0307 19:24:58.888995 889 clientconn.go:1331] [core] grpc: addrConn.createTransport failed to connect to { <nil> 0 <nil>}. Err: connection error: desc = "transport: Error while dialing dial unix: missing address". Reconnecting...

{kind=link}
{kind=link}
{kind=link}
Thanks for filing this bug @dinggggu and sorry for the extremely delayed response. We are working internally to consistently reproduce and try to identify a root cause. We will update ASAP.