
Ext4 corruption associated with shutdown of Ubuntu 12.10
| Affects | Status | Importance | Assigned to | Milestone | |
|---|---|---|---|---|---|
| upstart |
Confirmed
|
Undecided
|
Unassigned | ||
| linux (Ubuntu) |
Incomplete
|
High
|
Unassigned | ||
| network-manager (Ubuntu) |
Fix Released
|
High
|
Unassigned | ||
| upstart (Ubuntu) |
Confirmed
|
High
|
Unassigned | ||
Bug Description
1. Format and label a target Ext4 partion using Ubuntu 12.04
2. Install 64bit 12.10 OS using that target without reformatting it
3. Shut down
4. Boot an alternate copy of Ubuntu
5. Restart selecting the newly installed OS
6. Login then shutdown
6. Boot an alternate copy of Ubuntu
7.Fsck the newly installed OS allowing corrections to be made
Each time the the newly installed OS is executed and then shutdown, even if execution only consists of logging on, a subsequent fsck will FAIL.
I used Acronis True Image Home 2013 to create an image of the newly installed 64-bit Ubuntu 12.10, so I can recreate the symptoms of Ext4 filesystem corruption 100% of the time by restoring from the image, booting, logging on and shutting down.
ProblemType: Bug
DistroRelease: Ubuntu 12.10
Package: linux-image-
ProcVersionSign
Uname: Linux 3.5.0-17-generic x86_64
ApportVersion: 2.6.1-0ubuntu3
Architecture: amd64
AudioDevicesInUse:
USER PID ACCESS COMMAND
/dev/snd/
/dev/snd/
CRDA: Error: command ['iw', 'reg', 'get'] failed with exit code 1: nl80211 not found.
Date: Tue Oct 30 22:24:54 2012
HibernationDevice: RESUME=
InstallationMedia: Ubuntu 12.10 "Quantal Quetzal" - Release amd64 (20121017.5)
IwConfig:
eth0 no wireless extensions.
lo no wireless extensions.
MachineType: System manufacturer P5Q-E
ProcEnviron:
PATH=(custom, no user)
XDG_RUNTIME_
LANG=en_US.UTF-8
SHELL=/bin/bash
ProcFB: 0 nouveaufb
ProcKernelCmdLine: BOOT_IMAGE=
RelatedPackageV
linux-
linux-
linux-firmware 1.95
RfKill:
SourcePackage: linux
UpgradeStatus: No upgrade log present (probably fresh install)
dmi.bios.date: 04/06/2009
dmi.bios.vendor: American Megatrends Inc.
dmi.bios.version: 2101
dmi.board.
dmi.board.name: P5Q-E
dmi.board.vendor: ASUSTeK Computer INC.
dmi.board.version: Rev 1.xx
dmi.chassis.
dmi.chassis.type: 3
dmi.chassis.vendor: Chassis Manufacture
dmi.chassis.
dmi.modalias: dmi:bvnAmerican
dmi.product.name: P5Q-E
dmi.product.
dmi.sys.vendor: System manufacturer

| Ernie 07 (ernestboyd) wrote : | #1 |
- AlsaInfo.txt Edit (48.8 KiB, text/plain; charset="utf-8")
- BootDmesg.txt Edit (57.4 KiB, text/plain; charset="utf-8")
- CurrentDmesg.txt Edit (1.0 KiB, text/plain; charset="utf-8")
- Dependencies.txt Edit (2.9 KiB, text/plain; charset="utf-8")
- Lspci.txt Edit (14.8 KiB, text/plain; charset="utf-8")
- Lsusb.txt Edit (641 bytes, text/plain; charset="utf-8")
- ProcCpuinfo.txt Edit (1.6 KiB, text/plain; charset="utf-8")
- ProcInterrupts.txt Edit (1.7 KiB, text/plain; charset="utf-8")
- ProcModules.txt Edit (2.4 KiB, text/plain; charset="utf-8")
- PulseList.txt Edit (23.7 KiB, text/plain; charset="utf-8")
- UdevDb.txt Edit (147.5 KiB, text/plain; charset="utf-8")
- UdevLog.txt Edit (208.7 KiB, text/plain; charset="utf-8")
- WifiSyslog.txt Edit (197.8 KiB, text/plain; charset="utf-8")
| Changed in linux (Ubuntu): | |
| status: | New → Confirmed |
| Joseph Salisbury (jsalisbury) wrote : | #2 |
| Changed in linux (Ubuntu): | |
| importance: | Undecided → High |
| status: | Confirmed → Incomplete |
| importance: | High → Critical |
| tags: | added: kernel-da-key needs-upstream-testing |
| Joseph Salisbury (jsalisbury) wrote : | #3 |
Set importance to critical due to possible corruption.
| Joseph Salisbury (jsalisbury) wrote : | #4 |
Are you using any "Non-default" mount options?
| Ernie 07 (ernestboyd) wrote : | #5 |
In an effort to KISS and minimize regression testing, I reported a 100% repeatable bug. In my haste, I failed to indicate that the source iso used burn the LiveCD was the 64-bit version of Ubuntu 12.10 which was recently released to the public. After running the installation under the Try Ubuntu path, I performed a shutdown followed by a reboot of an alternate version (12.04) of Ubuntu. A fsck -vf of the recently installed (12.10) indicated problems and I followed the prompts to repair the Ext4 file system.
Acronis True Image Home 2013 was used to create an image which could be restored quickly.
To create the problem, I booted (12.10), logged in, waited a while (sometimes a few minutes) and then performed a shutdown followed by a reboot of an alternate version (12.04) of Ubuntu. A fsck -vf of the recently installed (12.10) indicated problems and I followed the prompts to repair the Ext4 file system.
It would seem to me that critical data can be obtained from a 100% repeatable problem in a "known" environment. The symptoms might be masked in a different version of the kernel although the problem still exists.
| Changed in linux (Ubuntu): | |
| importance: | Critical → High |
| Bernd Schubert (aakef) wrote : | #6 |
Ernie, I see a lot of log files here, but somehow e2fsck logs seem to be missing. Any chance you have captured e2fsck messages or could recreate those?
And I entirely agree with you, in my opionion just updating a recent stable kernel to a development version is not a real solution.
Thanks,
Bernd
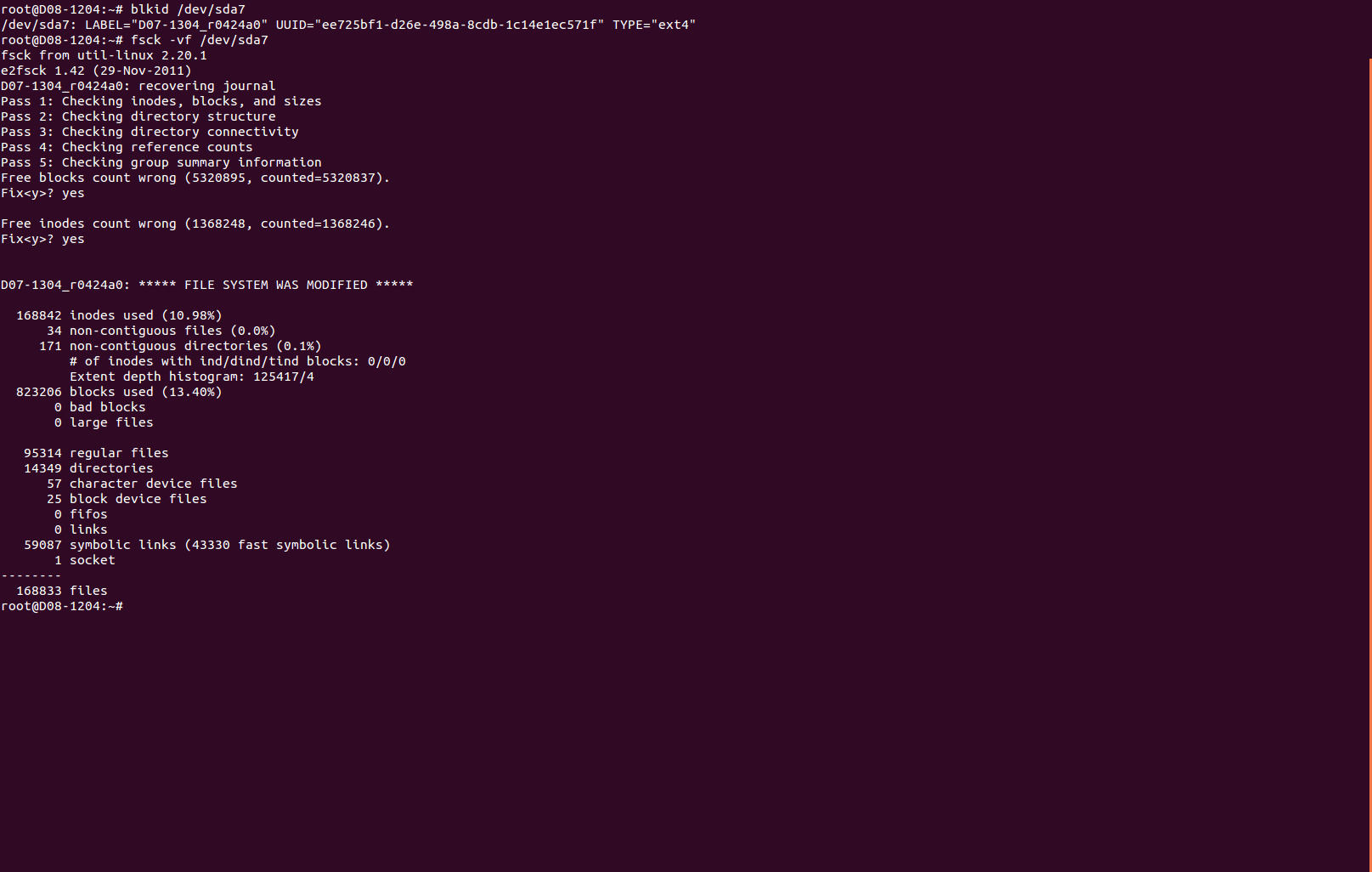
| Ernie 07 (ernestboyd) wrote : | #7 |
- Screenshot of fsck output Edit (114.8 KiB, image/png)
{kind=link}
When I checked /var/log/fsck, the two files appear unchanged from the original distribution on both the 12.10 and 12.04 OS's. I have attached a screenshot of the fsck output in case that would be helpful
| Christian Niemeyer (christian-niemeyer) wrote : | #8 |
Filesystem corruption after shutdown with a clean standard installation. 100% confirmation. 100% reproducable.
But I guess it's not ext4 related. It's a dbus/networking problem with the shutdown scripts. However nobody fixed it. Though it was still reported. Busy filesystem, busy scripts, unclean shutdown. Everytime.
My system: AMD64, wired Networking (forcedeth). Again, I think it's a dbus/networking
References:
https:/
https:/
| Christian Niemeyer (christian-niemeyer) wrote : | #9 |
Shutdown filesystem corruption in 12.10 stops for me after doing: sudo apt-get remove --purge dnsmasq-base resolvconf wpasupplicant isc-dhcp-client isc-dhcp-common libnm-glib-vpn1 libnm-glib4 libnm-gtk-common libnm-gtk0 libnm-util2 network-manager network-
(I guess mandatory are dnsmasq-base, resolconf, isc-dhcp-*, network-manager-*)
| jim warner (warnerjc) wrote : | #10 |
I too have had this problem since upgrading (not fresh installing) 12.10.
Under my wireless connection, when I uncheck "available to all users", for each of several users, I am able to shutdown cleanly.
Of course, upon reboot the "available", "not connected" and then "connected" messages are a bit anoying.
I hope my experience may provide additional clues to this bugs ultimate demise.
| Daniel J Blueman (watchmaker) wrote : | #11 |
This looks to be the same issue as I was experiencing during 12.10 development:
http://
Journal recovery occurs 100% of the time; list of orhpan inodes presumably depends on the amount of unlinking in the last 5 seconds before shutdown. Oddly enough, I don't observe this on my work desktop running Ubuntu 12.10, but I do see this on three laptops - also with Ubuntu 12.04. I'll double-check this.
| Theodore Ts'o (tytso) wrote : | #12 |
Those specific fsck corrections --- fixing the number of free blocks and the number of free inodes --- is completely normal and is purely a cosmetic issue. There is nothing to worry about here.
What is going on is that ext4 no longer updates the superblock after every block and inode allocation; that causes a wasteful write cycle to the superblock at every single journal commit, and it also is a SMP scalability bottleneck for larger servers (i.e., with 32 or 64 CPU's). To fix this, we no longer update these values in the superblock at every commit. Instead, we only update these values when we unmount the file system, mainly for cosmetic purposes so that dumpe2fs shoes the correct number of free inodes and blocks, and at mount time we calculate the total number of free blocks and inodes in the file system by summing the the free blocks/inodes statistics for each block group. So in fact, ext4 does not depend on the correctness of the values in the superblock, but it does try to update them on a clean unmount.
In e2fsprogs commit id 2788cc879bbe6, which is in e2fsprogs 1.42. 3 and newer, we changed things so that e2fsck -n would not display this as something "wrong". However, we still do show this as something that we "fix" when running e2fsck -y or -p, since in fact it is a change to the file systems. See: http://
No one else has complained or noticed up until now, because other distro's apparently are capable of doing a clean shutdown allowing the file system to be unmounted cleanly. Ubuntu, unfortunately, is incapable of reliably doing a clean shutdown even when users request it, which is why Ubuntu users are seeing this behavior much more frequently, and apparently some people have panicked as a result. Sigh....
| Ernie 07 (ernestboyd) wrote : | #13 |
For my environment (Ethernet DSL to Internet) a temporary workaround follows:
1. UNCHECK Enable Networking
2. Wait until after the disconnected message goes away
3. Restart and Shutdown
4. Fsck from an alternate installation will NOT throw any errors.
Apparently Unchecking Enable Networking does something that a simple restart or shutdown does NOT in terms of preparing for a SAFE shutdown.
| Daniel J Blueman (watchmaker) wrote : | #14 |
Ok, I found this also on older desktops with rotational disks (all the four ones mentioned have SSDs) running Ubuntu 12.04.1.
As Ted points out, it looks like Ubuntu (Upstart?) has issues with shutdown, but could there be a race exposed by the superb speed that Upstart is executing the umount/remount-ro, disk-cache-flush and kernel-reboot vector sequence?
| Luis Alvarado (luisalvarado) wrote : | #15 |
Might this have to do with anything relating to NetworkManager not connecting automatically or not detecting any connections until I disable the "Enable Networking" option, wait a couple of seconds and enable it again. Same for Wireless.
Tested just in case it has something to do with it with Intel LAN Wired connections (Motherboards Intel DP35DP and Intel DZ68DB) and with Linksys WMP300N, Linksys WMP600 and Realtek Gigalan (Forgot model). All of them I need to "reset" the network like I mentioned above.
| misiu_mp (misiu-mp) wrote : | #16 |
To clarify as it is not completely apparent from the above discussion:
The repairs reported by fsck are not caused by corruption, but are harmless and purely cosmetic fixes. The reason is that to avoid performance bottlenecks, ext4 does not update the superblock after each inode or block (de)allocation. This is done on (clean) unmount instead and only to make it look good. The filesystem does not rely on this information.
The real bug is of course ubuntu not shutting down cleanly, and thus not performing the umount.
Then again if this is not an error in the fs, then maybe fsck shouldn't prevent the system from cleanly booting.
Theodore Ts'o take on it:
https:/
| misiu_mp (misiu-mp) wrote : | #17 |
Hmm, somehow I missed that the actual Theodore Ts'o already commented on this here. Oops.
Still though , if this is not an error in the fs, then fsck shouldn't prevent the system from cleanly booting.
| Ernie 07 (ernestboyd) wrote : | #18 |
I have attempted to focus on a repeatable error condition. Essentially, a fsck via an alternate copy of Ubuntu would ALWAYS produce errors following simple behavior. Boot, logon, shutdown.
If I keep the Enable Network option unchecked, the error NEVER occurs. Therefore it seems reasonable to conclude that networking functionally is broken.
| Francisco Reverbel (reverbel) wrote : | #19 |
I ran into this bug and confirm it that the suggested workaround is effective. The problem does not show up if I uncheck "Enable Networking" before shutting the system down.
| Launchpad Janitor (janitor) wrote : | #20 |
Status changed to 'Confirmed' because the bug affects multiple users.
| Changed in network-manager (Ubuntu): | |
| status: | New → Confirmed |
| xavier vilajosana (xvilajosana) wrote : | #21 |
I'm facing the same problem. Then I've read that by disabling networking before turning off the computer the problem disappears, however, after two days of turning turning off networking service and everything working fine, I've ran in the same issue, even having disabled networking.
I am using gnome-shell and I don't have a button to disable networking but I switch the service off instead
sudo service networking stop
right before shutting down the system.
several errors appear when I stop the networking service:
1-gnome-shell crashes and I lose the window borders including buttons to close them.
2-Also the top bar disappears and hence I need to stop the machine by
sudo shutdown now.
this process fails when trying to stop services and logs me in into a root terminal.
to stop the machine I have to
reboot now
and turn off the machine manually when in starts.
It is becoming urgent to solve that issue as every 2 days I need to boot with a usb drive and force a superblock correction using that tutorial.
http://
I've been using Ubuntu since 7.04 and I am at one step to completely switch to another O.S. I cannot work with so much problems.
| Ernie 07 (ernestboyd) wrote : | #22 |
The workaround of disabling networking becomes unavailable EACH time POORLY maintained Nvidia drivers randomly cause 12.10 to crash requiring a power cycle to recover.
Will this BUG be fixed before 13.04 or should I AVOID 12.10 and continue to use 12.04?
| Daniel J Blueman (watchmaker) wrote : | #23 |
@Joseph
I've tested with various v3.6 and v3.7 mainline kernel, along with Ubuntu kernels, all with defaults mount options; I still observe unclean filesystem messages:
$ dmesg
...
EXT4-fs (sda2): INFO: recovery required on readonly filesystem
EXT4-fs (sda2): write access will be enabled during recovery
...
EXT4-fs (sda2): recovery complete
Users users likely mis-correlate NetworkManager as the issue, since it changes the upstart race condition timing; most likely, this is an upstart issue, as I believe the kernel has the correct behaviour, thus it would be inappropriate to add the "kernel-
What's next?
| Changed in linux (Ubuntu): | |
| status: | Incomplete → Confirmed |
| tags: | removed: needs-upstream-testing |
| Daniel J Blueman (watchmaker) wrote : | #24 |
We need to remove the network-manager project association, as it is just circumstantial.
| Changed in network-manager (Ubuntu): | |
| status: | Confirmed → Invalid |
| Changed in upstart: | |
| status: | New → Confirmed |
| Joseph Salisbury (jsalisbury) wrote : | #25 |
Add upstart task for Ubuntu.
| Changed in upstart (Ubuntu): | |
| importance: | Undecided → High |
| Changed in linux (Ubuntu): | |
| status: | Confirmed → Incomplete |
| Joseph Salisbury (jsalisbury) wrote : | #26 |
Has anyone affected by this bug had a chance to test 13.04(Raring)? It would be good to know if this issue exists there as well, or if it is limited to 12.10.
| Launchpad Janitor (janitor) wrote : | #27 |
Status changed to 'Confirmed' because the bug affects multiple users.
| Changed in upstart (Ubuntu): | |
| status: | New → Confirmed |
| Richard Samson (richard) wrote : | #28 |
Issue have disappeared since one month on a new installation of Raring 13.04.
| Ernie 07 (ernestboyd) wrote : | #29 |
This bug STILL occurs in 64 bit 1304 (Raring) with kernel 3.8.0-0-generic.
Downloaded and tested yesterday 2013-01_14
| Richard Samson (richard) wrote : | #30 |
Since one week this issue have occured again.
| Ernie 07 (ernestboyd) wrote : | #31 |
Richard,
This bug exists in 12.10 and 13.04.
In order to avoid file system corruption while using 12.10 or 13.04, you MUST disable networking before:
1. A system crash (if you have Nvidia hardware, this will be IMPOSSIBLE due to extremely poor drivers).
2. An orderly shutdown/restart.
Another option is to boycott 12.10 and 13.04 until the problem is resolved.
| Russell Faull (rfaull) wrote : | #32 |
This bug should be generalised to other file systems. It occurs using xfs and jfs, as well as ext4. In my experience the fs is not relevant, except some recover from an unclean shutdown better than others. (It's easy to try different file systems using fsarchiver, don't forget to change fstab to the new fs before reboot.)
| Ernie 07 (ernestboyd) wrote : | #33 |
This bug STILL occurs in 64 bit 1304 (Raring) with kernel 3.8.0-2-generic.
Downloaded and tested today 2013-01_27
| Francisco Reverbel (reverbel) wrote : | #34 |
The thing actually got worse in Quantal, as the workaround become ineffective after a recently update. Now fsck runs on each and every boot, even if "Enable Networking" is unchecked before shutdown.
Is anybody else seeing this behavior?
This is the Quantal kernel I am currently running:
$ uname -a
Linux skinny 3.5.0-22-generic #34-Ubuntu SMP Tue Jan 8 21:47:00 UTC 2013 x86_64 x86_64 x86_64 GNU/Linux
| Russell Faull (rfaull) wrote : | #35 |
Does anyone else see two lines about 'hub_port_status failed error (-110)' just before shutdown and immediately following 'mount: / is busy'? These errors always occur on several computers using different filesystems. (None of the workarounds mentioned above or in bug #1061639 resolve the problem of fsck/log replay on next boot.)
Is there a way to kill all usb processes before shutdown to try and determine if the usb system is interfering with the clean unmount of the filesystem?
I'm using kernel 3.5.0-23-generic #35-Ubuntu SMP Thu Jan 24 13:05:29 UTC 2013 i686 i686 i686 GNU/Linux
This may need a separate bug report, if the usb system is a possible cause and other filesystems also run fsck/log replay.
| jim warner (warnerjc) wrote : | #36 |
I agree that this has gotten worse recently and occurs on every boot.
That, along with the apparent lack of 'interest in/progress on' a solution has really affected my opinion of Ubuntu and confidence in quantal.
My kernel:
3.5.0-22-generic #34-Ubuntu SMP Tue Jan 8 21:47:00 UTC 2013 x86_64 x86_64 x86_64 GNU/Linux
| Ernie 07 (ernestboyd) wrote : | #37 |
Considering the published intention to have some form of 13.04 running on a Nexus7, I would say that it is FANTASY to expect much to be fixed in 12.10 with the exception of fixes to 13.04 that can be directly backported to 12.10.
| Russell Faull (rfaull) wrote : | #38 |
@Jim Warner, does your suggestion at #10 still work for you. It works for me, if I unckeck all connections, wired, wireless and mobile.
| jim warner (warnerjc) wrote : | #39 |
@Russell Faull, sadly no. That hasn't worked for me since the problem recurred (a few weeks ago, as I recall).
Fedora (spherical cow) is looking better and better...
| Clint Byrum (clint-fewbar) wrote : | #40 |
We saw issues like this in Ubuntu 11.10 as well, and it was resolved by figuring out what is left running just before shutdown.
If you can edit /etc/init.
/usr/sbin/lsof -n > /last-shutdown-lsof
(You may need to sudo apt-get install lsof)
This will record all open files just before root is remounted. Then after verifying that the FS was detected as dirty (please, stop calling it corrupt, it is not corrupt, just dirty) and fsck was run, upload the file /last-shutdown-lsof to this bug and we can take a look at it.
(please check the content of that file. I don't think it will have any sensitive data in it, but please check before uploading as this bug is public).
Judging from the reports, I doubt very much that this has anything to do with the kernel other than Ted T'so's suggestion that the kernel is simply exposing the dirty filesystem.
| Russell Faull (rfaull) wrote : | #41 |
Thanks Clint, I will try and report back soon, but...
For me, lsof is located at /usr/bin/lsof not /usr/sbin/lsof
| Russell Faull (rfaull) wrote : | #42 |
- last-shutdown-lsof-available-unchecked Edit (19.2 KiB, text/plain)
Ok, here are two version of last-shutdown-lsof.
last-shutdown-
last-shutdown-
Hope this helps
| Russell Faull (rfaull) wrote : | #43 |
| Steve Langasek (vorlon) wrote : | #44 |
Russell,
Your log shows dhclient holding a file open. It also shows that Network Manager itself is no longer running. Can you confirm that Network Manager is the only way dhclient is run on your system?
If this dhclient is from NM, then it seems that NM is failing to correctly reap the dhclient at shutdown. Opening a task for NM.
| Changed in network-manager (Ubuntu): | |
| status: | Invalid → Triaged |
| importance: | Undecided → High |
| Russell Faull (rfaull) wrote : | #45 |
Steve, as far as I can tell, NM is the only way that dhclient is started/run. Is there a way to confirm this?
| Russell Faull (rfaull) wrote : | #46 |
Further to #45, if I check 'Available to all user' (usually causing an unclean filesystem at shutdown) and then do 'sudo service network-manager stop' and then 'killall dhclient' the filesystem will then go down cleanly.
Steve, I'm guessing that answers your question at #44.
| Francisco Reverbel (reverbel) wrote : | #47 |
- last-shutdown-lsof Edit (37.3 KiB, text/plain)
Clint,
Here is the file last-shutdown-lsof I obtained per your instructions. It was generated on Quantal, with "Enable Networking" unchecked before shutdown.
My list of open files looks different from Russell's one. I do not have entries for dhcp, but I do have entries for modem-manager.
| Clint Byrum (clint-fewbar) wrote : | #48 |
I wonder if somehow dhclient is being added to omitpids.
If you edit /etc/init.
| Russell Faull (rfaull) wrote : | #49 |
Clint, I have tried what you suggested (uncomment line 132 at /etc/init.
| jim warner (warnerjc) wrote : | #50 |
- disconnect wireless before shutdown Edit (25.5 KiB, text/plain)
I use wireless exclusively and tried the following combinations but NEVER achieved a clean shutdown.
available to all (3 users) -------------------
1. autoconnect, connected @ shutdown
available to single user -------
2. autoconnect, connected @ shutdown
3. autoconnect, disconnected before shut
4. manually connected, disconnected before shut
5. networking + wireless enabled, but never connected
6. disabled networking, never connected
7. disabled wireless+
My lsof log #1 mentions dhclient as others have. My logs #5 - 7 contain no suspect programs. But my logs #1 - 4 also implicate dnsmasq.
I've included the logs from attempt #4 and 7 for what they're worth.
| jim warner (warnerjc) wrote : | #51 |
- everything disabled, never connected and still unclean shutdown Edit (22.2 KiB, text/plain)
and here's # 7...
| Daniel J Blueman (watchmaker) wrote : | #52 |
Here, I see init (expected), dhclient, dnsmasq and plymouthd.
| Steve Langasek (vorlon) wrote : Re: [Bug 1073433] Re: Ext4 corruption associated with shutdown of Ubuntu 12.10 | #53 |
On Tue, Jan 29, 2013 at 01:47:47PM -0000, Daniel J Blueman wrote:
> Here, I see init (expected), dhclient, dnsmasq and plymouthd.
plymouthd is also expected to be running but should not have any files open
for writing. The other two are clearly associated with network-manager, and
seem to indicate a failure to clean up.
| Russell Faull (rfaull) wrote : | #54 |
Ok, where to next? Is more information needed from users?
It's gone quiet on what seems like an identified problem and narrowing evidence pointing to two culprits.
| Clint Byrum (clint-fewbar) wrote : | #55 |
Russell, the problem in network manager needs to be debugged. No milestone is set yet, so its not known when it will be resolved, but it does seem likely that the problem will be easy to fix given how reproducible it is and how much insight we have into it now.
| Bernd Schubert (aakef) wrote : | #56 |
Stupid question, why should network-manager not be killable? From my point of view everything should be killed before a shutdown except of processes, which are absolutely required to continue the shutdown/reboot. So for example if you are using unionfs-fuse for "/", "/etc" or "/var" and kill its daemon, shutdown cannot continue. But how is that related to the network manager?
Assuming there is a network file system involved, kill network-manager or dhclient should not fail the network connection, at least not unless network manager does that. But that would be a in network-manager and should be fixed instead. A simply workaround even would be to kill it with SIGTERM to give it no chance to do any harm.
| Sandor Rozsa (gsrozsa) wrote : | #57 |
Hi all,
I don't know how much time it may take to find why Networkmanager doesn't handle open files properly at shutdown, but since my home was also failing every time and manual disable networking through NM solved my problem (and shutdown is much faster), I added
nmcli nm enable false|true
to my stop and start-up scripts.
I wrote this to help others who may also have this problem and don't want to manually disable / enable networking everytime.
| Francisco Reverbel (reverbel) wrote : | #58 |
Hi Sandor,
Where exactly did you add the calls to nmcli?
| Ernie 07 (ernestboyd) wrote : | #59 |
This bug also occurs in 64 bit 1304 (Raring) with kernel 3.8.0-3-generic.
Tested Friday 2013-02_01
| Francisco Reverbel (reverbel) wrote : | #60 |
Today I' ve seen an improvement in Quantal: the workaround suggested at #13 resumed working after I got a kernel update from 3.5.0-22-generic to 3.5.0-23-generic.
Per Sandor' s suggestion, I have added to /etc/init two files that relieve me from the burden of manually disabling/enabling the network manager. These two files are shown below.
$ cat /etc/init/
description "Hack 1 to circumvent NetworkManager bug in Ubuntu 12.10"
start on started gdm
script
/usr/bin/nmcli nm enable true
end script
$ cat /etc/init/
description "Hack 2 to circumvent NetworkManager bug in Ubuntu 12.10"
start on runlevel [016]
script
/usr/bin/nmcli nm enable false
end script
| Sandor Rozsa (gsrozsa) wrote : | #61 |
Hi Francisco,
I created a script in /etc/init.d (I copied from an existing script actually), at the stop part I inserted the command
"nmcli nm enable false" and at the start part true.
Then I created a symlink for it S60networkm in /etc/rc2...rc5.d, and also K05networkm in /etc/rc0.d and rc6.d.
| Francisco Reverbel (reverbel) wrote : | #62 |
Thanks Sandor. I did something similar, but in /etc/init. (See #60.) Your comment (at #57) was very helpful!
| Russell Faull (rfaull) wrote : | #63 |
Hi Fransisco' I agree that latest kernel has improved the situation. It is now possible to simple uncheck 'Available to all users' in NM to get a clean shutdown. Beware if you create a new network connection, because it defaults to 'Available to all users' checked. Before the latest kernel, this solution wouldn't work for me.
| Francisco Reverbel (reverbel) wrote : | #64 |
For people who need to live with this bug, it might be good to stress that Sandor' s suggestion (#57 and #61) and my little hack (#60) rely on the workaround at #13, which is effective with kernel 3.5.0-23-generic (the current kernel in Ubuntu 12.10), but not with kernel 3.5.0-22-generic (the previous kernel in Ubuntu 12.10). I believe (but am not quite sure) that the workaround was also ineffective with kernel 3.5.0-21-generic and that it was effective with the previous Quantal kernels.
While this bug is not fixed I will think twice before doing a kernel upgrade on Quantal, as a disk check on every boot makes the system nearly unusable to me. I am not blaming the kernel, but it appears that the workaround depends upon the timing of an upstart race condition, which may change with the kernel version.
When a new kernel version comes out, I would like to know if the new kernel will not break the workaround again.
| Francisco Reverbel (reverbel) wrote : | #65 |
Hi Russel,
With Sandor's hack (see #57 and #61, or, alternatively, #60) you do not even need to uncheck "Available to all users", as the shutdown and startup scripts take care of disabling and enabling the NM.
| Sandor Rozsa (gsrozsa) wrote : | #66 |
Yes, you are right, Francisco, I didn't uncheck the all users option. I am glad it helped. I hope others with this problem will also find this page and solve this problem this way.
I don't know if an update to the kernel or any part of the system config will break this. Previously I had root filesystem problems, that was fixed by some killall commands ( I don't remeber the site, that suggested it) and I thought the problem is gone, but a few days later it started to do home corruptions, so I searched for this symptom again, and found this bug.
Since Linux has a command for everything, I thought there must be one for disabling network through Networkmanager. I like Networkmanager, so I didn't want to disable it (I travel with my laptop and use wireless connection, so this is convenient.), but this command is perfectly does its job.
| Russell Faull (rfaull) wrote : | #67 |
I've just tested newly released kernel 3.5.0-24. It also works with uncheck 'Available to all users' workaround mentioned above.
| Ernie 07 (ernestboyd) wrote : | #68 |
This bug also occurs in 64 bit 1304 (Raring) with kernel 3.8.0-6-generic.
Tested Friday 2013-02_16
| Bernd Schubert (aakef) wrote : | #69 |
I fail to understand why so many people are insisting this is a kernel bug. It isn't. What basically happens is that the network-manager process is not killed by killall5. This process also has an open file descriptor and therefore the root partitions cannot be mounted read-only before shutdown, as the kernel reports it is busy. Network-manager will not be killed due to the ubuntu patch add_sendsigs_
From: Mathieu Trudel-Lapierre <email address hidden>
Subject: Move NM's spawns pid files to /run/sendsigs.
Bug-Ubuntu: https:/
The pidfiles are only used by NM to start and be able to stop the same process,
their actual location doesn't overly matter. In this case, putting them
under /run/sendsigs.
an upstart job, and in fact they are (although indirectly).
I have no idea what Mathieu actually intended with this patch, but it is entirely wrong and made everything worse. Instead of refusing to kill NM, it needs to be killed, which is just the other way around than what the patch is doing.
The only way to fix this from kernel point of view would be to write a kernel patch to allow to mount read-only while there are still file descriptors, which have write access. All those FDs would need to be closed from the kernel side and propably would cause application crashes.
| Steve Langasek (vorlon) wrote : | #70 |
On Sun, Feb 17, 2013 at 09:04:32PM -0000, Bernd Schubert wrote:
> I have no idea what Mathieu actually intended with this patch, but it is
> entirely wrong and made everything worse. Instead of refusing to kill NM,
> it needs to be killed, which is just the other way around than what the
> patch is doing.
The intent, which is correct, is that NM itself shuts down these subordinate
processes as part of the network shutdown *after* /etc/init.
run, instead of having them killed in an uncontrolled manner by
/etc/init.
Perhaps NM is failing to shut down the processes; but the sendsigs handling
itself remains correct. /etc/init.
indiscriminately terminate processes that are needed for the network to run;
these processes need to be ended later, after /etc/init.
unmounted all network filesystems.
| Bernd Schubert (aakef) wrote : | #71 |
Well, network usually does not break by killing dhclient, at least not if the lease does not expire just in this second. If we ignore this race, probably only modem processes are left. But these are not even considered by the add_sendsigs_
If we don't want to ignore the lease race and we don't trust NM to kill sub-processes we need a to run killall5 a 2nd time and this time it only must ignore fuse processes. However, if the root file system or /etc or /var are on NFS, we cannot fix this race at all and have to leave it to the admin to provide sufficiently long leases.
| Steve Langasek (vorlon) wrote : | #72 |
On Mon, Feb 18, 2013 at 08:32:14AM -0000, Bernd Schubert wrote:
> Well, network usually does not break by killing dhclient,
Irrelevant. The dhclient process is managed by NM, and sendsigs must not
interfere with it.
> If we don't want to ignore the lease race and we don't trust NM to kill
> sub-processes
We *require* NM to clean up its subprocesses. This is the only sane
architecture. If NM is not doing so, that's a bug in NM.
> we need a to run killall5 a 2nd time
No.
| Bernd Schubert (aakef) wrote : | #73 |
On 02/18/2013 10:10 AM, Steve Langasek wrote:
> On Mon, Feb 18, 2013 at 08:32:14AM -0000, Bernd Schubert wrote:
>
>> Well, network usually does not break by killing dhclient,
>
> Irrelevant. The dhclient process is managed by NM, and sendsigs must not
> interfere with it.
>
>> If we don't want to ignore the lease race and we don't trust NM to kill
>> sub-processes
>
> We *require* NM to clean up its subprocesses. This is the only sane
> architecture. If NM is not doing so, that's a bug in NM.
Well, do as you like, but from my point of view an init system that does
not properly kill processes is broken by design.
Relying on something is always wrong, especially if it is system
critical (I got severe data loss on my btrfs partition due to this bug
here). killall5 is there to enfore things, not to rely on them... It is
nice that it speeds up shutdown, but that is only a side effect.
So far I also only see a patch in NM that made it worse than it had been
before. Properly fixing NM is certainly correct, but that still is no
enforcement that shutdown properly works.
I know how to fix it on my systems and I'm going to publish that
information, but other than that I'm giving up on upstream.
| Francisco Reverbel (reverbel) wrote : | #74 |
Does anybody know if the workarounds at #10 and #13 (or the suggestion at #57 and #61, or the one at #60) remain effective after a kernel upgrade to 3.5.0-25?
| Russell Faull (rfaull) wrote : | #75 |
Not directly, but I would assume so, as unchecking 'Available to all users' still works with 3.5.0-25.
I have also tried your suggestion at #60, thanks. It works for me -- but I have reverted to the simple 'uncheck' as there seems no downside in my installations and any future fix should be with NM not the init system.
| Francisco Reverbel (reverbel) wrote : | #76 |
Thanks Russel. I will upgrade to 3.5.0-25.
| Francisco Reverbel (reverbel) wrote : | #77 |
Does anybody know if the workarounds posted here remain effective after a kernel upgrade to 3.5.0-26?
| Russell Faull (rfaull) wrote : | #78 |
Franciso, I am using 3.5.0-26, and the my comment at #75 holds true.
| Ernie 07 (ernestboyd) wrote : | #79 |
Do not be deceived. This is a 1210 and 13.04 problem.
64-bit 1204 3.2.0-39-generic #62-Ubuntu SMP Thu Feb 28 00:28:53 UTC 2013 and prior 12.04 64-bit versions work just fine!
It would be quite delightful if someone would correct this problem of failing to shutdown properly.
| Ernie 07 (ernestboyd) wrote : | #80 |
I repeat. This is a 12.10 and 13.04 problem.
64-bit 1204 3.5.0-26-generic #42~precise1-Ubuntu SMP Mon Mar 11 22:17:58 UTC 2013 and prior 12.04
64-bit versions work just fine!
A fix for this problem of failing to shutdown properly would be much appreciated.
| Francisco Reverbel (reverbel) wrote : | #81 |
Thanks again Russell. I'm upgrading to 3.5.0-26. It's good to know that the upgrade won't break the workarounds.
And of course I agree with Ernest that a proper fix for this bug would be very much appreciated.
| Max (m-gorodok) wrote : | #82 |
It seems that the issue may be connected with bug 1124803
"NetworkManager doesn't respond to SIGTERM in daemon mode"
That patch helped me on 12.10. But I am puzzled by the reports
that this bug has not fixed in Raring.
| Daniel J Blueman (watchmaker) wrote : | #83 |
From the upstream report [1], the fix is for Ubuntu to carry the patch against NetworkManager [2].
Since this is correctly understood and addressed in bug 1124803 as Max points out, this is a duplicate bug report, so I'll mark it so.
[1] https:/
[2] https:/
| Alexander (lxandr) wrote : | #84 |
- mount-lsof-fuser Edit (23.6 KiB, text/plain)
I think, the problem is somewhere deeper... In upstart/init.
I've purged network-manager, modem-manager and even plymouth! And added S75 script in
/etc/rc0.d:
cat /proc/mounts
/usr/bin/lsof
/bin/fuser -v -m -u / 1>/dev/null
But as you can see, the problem remained.
kernel 3.5.0-22-generic, quantal.
| Marius B. Kotsbak (mariusko) wrote : | #85 |
Alexander, could you test it using a Raring daily image?
| Steve Langasek (vorlon) wrote : | #86 |
Alexander, your lsof output doesn't show any files open for writing on the root filesystem except for the S75 script's own log. If you're getting ext4 corruption on shutdown, that seems to be unrelated to this bug.
| Ernie 07 (ernestboyd) wrote : | #87 |
Using 64-bit 3.8.0-16-generic #26-Ubuntu SMP Mon Apr 1 19:52:57 UTC 2013 from the 2013-04_02 daily build:
1. NetworkManager stopped correctly (immediately) via sudo stop network-manager.
2. A reboot to an alternate system and fsck of the system under test presented errors.
Regardless of whether I stopped or restarted NetworkManager, as long as I manually unchecked Enable Networking, a clean shutdown would occur and a subsequent fsck would show no errors.
A process (maybe more than one) is being gracefully shut down when I manually uncheck Enable Networking but is not getting properly shutdown via sudo stop network-manager. Hope this data point is helpful.
| Alexander (lxandr) wrote : | #88 |
Steve Langasek, maybe it's a race condition. When init scripts trying to unmount root, they fail because of opened files. But, when I check for opened files in S75 script those processes had been terminated already. So, we see no open files.
I'll try to catch it with S59 script (before S60umountroot).
| Alexander (lxandr) wrote : | #89 |
Marius B. Kotsbak, no, currently, I can't, sorry. (lack of time)
Upd: I also have
tmpfs /tmp tmpfs defaults
string in /etc/fstab. Maybe this is the case...
I'll check this too.
| Alexander (lxandr) wrote : | #90 |
As I've understood, unmount of tmpfs filesystems is called from /etc/rc{
My /etc/rc{0,6}.d/S59 script calls 'cat /proc/mounts > S59.log'
Then, why do I see tmpfs in log?
$ grep "tmpfs" S59.log
udev /dev devtmpfs rw,relatime,
tmpfs /run tmpfs rw,nosuid,
none /run/lock tmpfs rw,nosuid,
none /run/shm tmpfs rw,nosuid,
none /run/user tmpfs rw,nosuid,
| Alexander (lxandr) wrote : | #91 |
Forgot to mention that the lsof launched from S59 didn't show any files opened for writing too.
| Ivan Larionov (xeron-oskom) wrote : | #92 |
I have exactly the same problem.
Everything stopped, dhclient, network manager and plymouthd as well, no redundant open files, everything what should be umounted is umounted.
But every reboot I still see "umount: / is busy" and then fsck at start.
| Max (m-gorodok) wrote : | #93 |
The original description does not mention removing of network-manager
and other packages.
The phrase concerning redundant open files in unclear for me.
Is there any files open for writing? I wonder if the problem
if the debug scripts is removed.
Instead of plymouth removing, the splash screen can be suppressed
by setting empty
GRUB_CMDLINE_
in /etc/default/grub
(remove default options "quiet" and "splash")
and run
sudo update-grub
/etc/default/halt can be temporally changed to
HALT=halt
this will allow to inspect very last messages during shutdown.
VERBOSE=yes
in /etc/default/rcS will add a couple more messages.
Finally
sudo initctl log-priority info
sudo sysctl kernel.printk="7 4 1 7"
before shutdown makes upstart quite verbose.
| Alexander (lxandr) wrote : | #94 |
- mega-log-1365656098 Edit (27.5 KiB, text/plain)
Max, as I've understood, "no splash" doesn't disable plymouth. Some people suppose that the freezed plymouth is the cause:
https:/
I've decided to find it out and totally purged plymouth from system. But that didn't help.
So, what do we have now?
I've modified /etc/init.
=======
for i in 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21
do
|| mount $MOUNT_FORCE_OPT -n -o remount,ro dummydev / 2>/dev/null \
|| mount $MOUNT_FORCE_OPT -n -o remount,ro /
# [ "$VERBOSE" = no ] || log_action_end_msg $ES
if [ $ES -gt 0 ]
# sleep 1
fi
done
=======
Today's morning I've got a 21 message "/ is busy" at shutdown.
Early, I thought that the cause is that some processes are accessing the disk during shutdown (writing). Some processes which are not terminated on time, so " / is busy " message appears.
Now I'm looking into logs and... Well, looks like it isn't the real cause.
I don't see any files opened for writing (except pipe, @/com/ubuntu/
So, more and more I think, that this bug is in 'init/upstart'... or in kernel!
It's not so easy to reproduce it. I've tried a lot of times to reboot machine under heavy cpu and I/O load and bug doesn't apper (a lot of times in about 10-15 minutes).
But bug appears more frequently when uptime is high enough (at least 1/2 of a day).
Steps to reproduce: push power button from running X session.
One more interesting thing: my root partition is on usb hard drive.
If I'll have some more free time near future, I'll try to test it with a new kernel ( > 3.5).
| Alexander (lxandr) wrote : | #96 |
| Alexander (lxandr) wrote : | #97 |
| Max (m-gorodok) wrote : | #98 |
It turned out to a kind of mystery. No files are left open for writing
but device is busy and can not be cleanly remounted readonly.
Moreover it is not clear how to reproduce the issue.
Concerning the formalities, since the issue addressed
in the last comments have nothing with bug lp: #1124803
"NetworkManager doesn't respond to SIGTERM in daemon mode",
the link to that bug might be removed. On the other hand
original description of this bug fitted quite well
to bug lp: #1124803 and it has nothing
common with removing of network-manager, plymouth, etc.
In my opinion the case with no bunch of packages should be filed
as a dedicated bug with clear statements concerning conditions
and ruled out hypotheses.
Alexander, actually I can not figure out which way debug scripts
can block umount, but since they provide no useful info,
it is interesting what would happen if you completely remove
debug scripts and temporally set
HALT=halt
in /etc/default/halt to have time to inspect last messages
without writing them to a file.
Have you tried memtest on that box? Have you experienced
kernel panic or Oops due to kernel modules or hangs
due to e.g. graphics card driver?
Concerning the bug lp: #1124803, there are tails of
modem-manager and so network-manager again.
I can not comment on plymouth hangs since removing
of "quiet" and "splash" from GRUB_CMDLINE_
works like a charm for me. (Actually I have tried
an upstart task with "/bin/plymouth hide-splash"
command before.)
To obtain more debug info I would suggest to run
sudo initctl log-priority info
before shutdown
(perhaps 'sudo sysctl kernel.printk="7 4 1 7"'
to see the messages on the screen as well)
and add
dmesg > /upstart-
to /etc/init.
There is an issue with network manager proliferated to
plenty of bugs, but it can be easily fixed. The problem
with busy / when no processes are left and
no files are open is very strange.
| Max (m-gorodok) wrote : | #99 |
Alexander, by the way, how have you managed to remove plymouth?
mountall depends on plymouth, initscripts depends on plymouth.
| sghpunk (sgh-mail) wrote : | #100 |
I just want to say about my expirience here. Maybe it adds some useful details to understanding what's going on.
Ubuntu = 12.04 amd64
kernel = 3.5.0-22-generic.
rootfs = btrfs
Sometimes I was able to see that / is busy before halt. Especially when my torrent client is seeding/leeching much torrents from/to another partition on another USB drive, and before shutdown I don't stop torrents.
Because I have no time to debug this issue. I just installed kernel from http://
And bug disappears like a charm.
So. My point is: This issue is more like kernel issue, not init scripts. And maybe it is related to old good https:/
I don't know, maybe I'm wrong.
| sghpunk (sgh-mail) wrote : | #101 |
Forget to say.
I have plymouth installed, but just removed of "quiet" and "splash" from GRUB_CMDLINE_
| Max (m-gorodok) wrote : | #102 |
I have broken the link to duplication of bug #1124803
"NetworkManager doesn't respond to SIGTERM in daemon mode".
This bug have been reported by Ernie and in the discussion
of bug #1124803 he insists that his bug has not fixed.
Network manager 0.9.6.0 in 12.10 quantal is really affected
by that bug, and if the patch mentioned there is applied
system shuts down correctly. On 'stop network-manager'
dhclient is stopped as well.
If network-manager 0.9.8.0 from Raring is installed to
12.10 Quantal then dhclient for some reason (unclear for me)
does not open lease file in /var/lib/
so root filesystem can be cleanly remounted readonly.
In Raring network-manager 0.9.8.0 opens a lease file
in /var/lib/
dhclient (intentionally?) remains alive.
The PID of dhclient is mentioned in /run/sendsigs.
so, if I guess correctly, dhclient is not stopped during
shutdown and /etc/init.
/ readonly due to the lease file open for writing.
Any volunteers to debug further?
| sghpunk (sgh-mail) wrote : | #103 |
I have Network manager installed in Ubuntu 12.04, but I have "/ busy" only with generic kernel.
With pf-kernel I have clear shutdown.
| Ernie 07 (ernestboyd) wrote : | #104 |
In another perhaps related bug 1124803, it was suggested to try wicd.
Unfortunately wicd would not install on 13.04 amd64.deb for me. Failure indicated partway through the installation.
| Alexander (lxandr) wrote : | #105 |
1) Problem appears on different hardware. I mean totally different (except for my usb hdd, from which the system boots).
2) I run memtest about a year ago... But I don't see any oops-es, hangs or kernel panics. So the problem is not related with (broken) hardware.
3) How I've removed plymouth? I read about plymouth in comments to #556372. People suggest to install plymouth-dummy package (which has no mountall dependency) so after that plymouth can be easily removed. I have neither plymouth nor network-manager nor modemmanager nor wicd installed. Just plain /etc/network/
4) I'm bringing network interface up manually from /etc/rc.local. Because 'ifup -a' called from init-scrips doesn't work correctly (bug).
5) The harder I'm trying to debug this bug, the less it appears (he knows that I'm hunting on him! haha).
6) I can speak russian, если что.
7) currently I can't set HALT=halt in /etc/default/halt. Because most of the time shutdown is scheduled and done automatically (and I can be far away from computer at that moment). But I'll do that soon.
8) Problem doesn't appear 100% of the time (at least for me). And also not related with any of my debug scripts.
9) Both root and swap partitions are on my usb harddrive. So, maybe it's somehow related to usb? Or swap?
I don't know is it important... but root and swap are mounted from fstab by label:
LABEL=root / ext4 errors=remount-ro 0 1
LABEL=swap none swap sw 0 0
10) I'm also using autofs daemon. Maybe it's somehow related to it?
11) Now I've removed all my debug parts from umountroot. And added two scripts:
/etc/rc0.
#!/bin/bash
/sbin/sysctl kernel.printk="7 4 1 7"
/bin/dmesg > /upstart-
/etc/rc0.
#!/bin/bash
/bin/dmesg > /upstart-
(also added symlinks to rc6.d)
But, I've got nothing interesting:
...
[22482.298335] init: smbd main process (1057) killed by TERM signal
[22482.299101] init: tty4 main process (1246) killed by TERM signal
[22482.299659] init: tty5 main process (1255) killed by TERM signal
[22482.300259] init: tty2 main process (1293) killed by TERM signal
[22482.304610] init: tty3 main process (1294) killed by TERM signal
[22482.305310] init: tty6 main process (1299) killed by TERM signal
[22482.315235] init: irqbalance main process (1327) killed by TERM signal
[22482.315828] init: cron main process (1339) killed by TERM signal
[22482.318599] init: tty1 main process (2165) killed by TERM signal
[22484.047088] init: Disconnected from system bus
[22484.190023] tg3 0000:10:00.0: wake-up capability enabled by ACPI
Both logs are the same.
12) cat /proc/cmdline
root=LABEL=root ro ipv6.disable=1
| Alexander (lxandr) wrote : | #106 |
Something really going wrong here.
Today's morning I've found reaaally something new! I'm seeing this for the first time ever. I've tried to halt the system (not poweroff as usually):
* Unmounting temporary filesystems...
umount: /tmp/auto6FJPRq (deleted): not found
umount: /tmp: device busy.
...
EXT4-fs (sdb2): re-mount. Opts: (null)
...
System halted.
What's wrong with /tmp now?!
Arrrgh!
All these Ubuntu bugs are beginning to drive me insane.
My own conclusion: init/upstart is totally screwed up!
Filesystem corruption is unacceptable! For _ANY_ operating system!
Ubuntu? On desktop? In production?!
Are you kidding me?!
Of course, no! Never!!
It's sad, but Ubuntu is suitable only for 'eye-candies' ("свистоперделки" in russian). No more. Not for work.
| Russell Faull (rfaull) wrote : | #107 |
Alexander, get rid of NM and install wicd to learn if the problem(s) still persist.
Using wicd, I get clean and fast shutdown in 5 seconds, with no fsck checks on reboot. Worth a try!
| Steve Langasek (vorlon) wrote : | #108 |
On Tue, Apr 16, 2013 at 08:38:29PM -0000, Alexander wrote:
> Something really going wrong here.
> Today's morning I've found reaaally something new! I'm seeing this for the
> first time ever. I've tried to halt the system (not poweroff as usually):
> * Unmounting temporary filesystems...
> umount: /tmp/auto6FJPRq (deleted): not found
> umount: /tmp: device busy.
> ...
> EXT4-fs (sdb2): re-mount. Opts: (null)
> ...
> System halted.
> What's wrong with /tmp now?!
That's a very good question. But it has nothing to do with upstart; for
some reason, /proc/mounts on your system reports a tmpfs mounted at
"/tmp/auto6FJPRq (deleted)", which it can't unmount, and as a result /tmp
can also not be unmounted cleanly.
What's unusual is that something on your system was able to delete the mount
point of an active mount. This shouldn't happen at all. So you may be
looking at a kernel bug, or a bug in sysvinit-utils (which handles the
unmounting at shutdown).
If you can reproduce this issue, please file a new bug report against
the sysvinit-utils package with details. It is certainly unrelated to the
common issue being described here.
| Ernie 07 (ernestboyd) wrote : | #109 |
Russel,
When using the CLI, I got an error and could not install wicd on 13.04
However, I was able to install it via the software center.
Each time that I attempted to use it, a connection failure message occurred immediately after the requested password was entered. Are you able to install/execute wicd using 13.04?
| Ernie 07 (ernestboyd) wrote : | #110 |
Another data set:
1. AT&T is my ISP. My Desktop connects to a DSL modem via Ethernet.
2. There seems to be some keepalive traffic. A packet of 64 or 121 bytes gets sent or received about every 10 seconds. This activity appears to happen in 12.04 which functions correctly and in 13.04 which fails 100% of the time.
3. Shutting down in this state (Enable Networking checked but NO explicit Internet activity) will result in an error every time.
4. The connection will drop if I unplug the Ethernet cable. In that state I can reboot with NO errors.
Since I can manually force the connection to drop by either unplugging the Ethernet cable or unchecking Enable Networking, shouldn't the network manager also drop the Ethernet connection when a restart/
I pose the question because the failure will never occur if the network connection has been dropped. Perhaps the keepalive traffic is not being forcibly killed.
| Russell Faull (rfaull) wrote : | #111 |
Ernie, I'm still on 12.10 (I'm waiting for RC before upgrading) and using wicd with a wireless connection, so I'm not sure why you are getting an error with your ethernet connection. You have probably explored all the options...
In the next couple of days I'll upgrade one computer to 13.04RC and report back if wicd can be successfully installed or not. (It is obviously in the 13.04 repos if you got it though Software centre.)
| Alexander (lxandr) wrote : | #112 |
Russel, please read my comment https:/
I repeat: I have neither plymouth nor network-manager nor modemmanager nor wicd installed. Just plain /etc/network/
/etc/network/
Disabling network in NM/replacing NM just hides the real bug. Problem is NOT in network manager. It is somewhere deeper (like Steve supposed, a kernel bug, or a bug in sysvinit-utils).
Today's morning I've got that 'busy' with halt:
acpid: exiting
speech-dispatcher disabled; edit /etc/default/
* Stopping VirtualBox kernel modules
Stopping UPS power management: apcupsd exiting, signal 15
apcupsd[1444]: apcupsd shutdown succeeded
apcupsd.
* Asking all remaining processes to terminate...
* All processes ended within 2 seconds....
[54994.264815] init: Disconnected from system bus
[54994.484761] tg3 0000:10:00.0: wake-up capability enabled by ACPI
* Unmounting temporary filesystems...
* Deactivating swap...
umount: /run/lock: not mounted
umount: /run/shm: not mounted
mount: / is busy
* Will now halt
[54995.304424] kvm: exiting hardware
[54995.305569] sd 0:0:0:0: [sda]
[54995.305929] sd 0:0:0:0: [sda]
[54995.958554] System halted.
| Alexander (lxandr) wrote : | #113 |
Steve, thanks for the info.
As I've mentioned earlier, I'm using autofs. I think that such names like 'tmp/autoXXXXX' are autofs temporary mount points. Also I have /tmp mounted as tmpfs.
So my guess is that tmpfs is getting unmounted BEFORE autofs daemon have been terminated (unmounted it's mountpoints). So that autofs mount points can't be unmounted (because they were left on old /tmp with tmpfs).
Now starting and stopping of services in Ubuntu not always works as it is expected. Earlier when services got started from /etc/init.d it was slow but predictable. Services have been launched one by one.
What is really going on now?.. Looks like no one really knows. Sometimes it looks like that all this stuff is launched asynchronously (simultaneously) and in background. Some kind of unpredictable hell, full of 'race conditions'. And if you don't see it that doesn't mean that this is not exist.
For me it's like playing with fire. Today you have won... But tomorrow you can burn.
For an example, I've seen a lot of times, when I do 'restart service_name' command I'm getting almost immediately output to console that service have been restarted. But meanwhile, when I've tried to connect to that service it wasn't ready! It is still being launched/restarted!
So why do I get output to the console, that the service have been restarted when in fact it still DOESN'T?
I'm just suspecting that the problem with 'busy' can be even deeper than I thought...
| Max (m-gorodok) wrote : | #114 |
Ernie, please, try to rebuild network-manager
with
#define TARGET_DEBIAN
added to src/dns-
src/nm-device.c src/nm-manager.c
in the very beginning of that files.
Perhaps you might need to change the line 45
of debian/rules from
--with-tests
to
--enable-tests=no
| Alexander (lxandr) wrote : | #115 |
Morning, 'halt'... and "/ is busy" again.
VERBOSE=yes
in /etc/default/rcS didn't help either.
Just a few messages are added:
* Will now unmount temporary filesystems
tmpfs has been unmounted
* Will now deactivate swap
swapoff on /dev/sdb1
* Mounting root filesystem read-only...
umount: /run/lock: not mounted
umount: /run/shm: not mounted
mount: / is busy
I don't know how to debug it even more.
Any ideas?
P.S.: with 3.8 kernel from PPA Xorg doesn't start (lack of KMS or something). So currently I can't fully test it with a new kernel.
| watgrad (watgrad) wrote : | #116 |
Is this bug still present in the released 13.04 version?
| Ernie 07 (ernestboyd) wrote : | #117 |
- Dirty fsck from BAD network enabled restart_2013-04-26 18:45:45.png Edit (111.6 KiB, image/png)
{kind=link}
ABSOLUTELY!
64-bit Desktop 3.8.0-19-generic #29-Ubuntu SMP Wed Apr 17 18:16:28 UTC 2013
IF
Internet connection to the modem exists and
Ethernet connection from my desktop to the modem and
Enable Networking checked and
Shutdown or Restart or Reboot
THEN
Bad shutdown
fsck from another copy of Ubuntu will indicate problems, see attachment
END
Dropping the Ethernet connection by unplugging the Ethernet cable or unchecking Enable Networking before a shutdown or reboot will ALWAYS keep the problem from occurring. This problem has existed since 12.10 and has been discussed but not fixed.
If it is helpful to know, while the Ethernet connection is up small keepalive packets seem to be sent and received from time to time.
| Max (m-gorodok) wrote : | #118 |
Ernie, have you tried the suggestion from the comment #114?
(Bug lp: #1169614)
| Ernie 07 (ernestboyd) wrote : | #119 |
Hi Max,
The last time I touched a compiler was in the windoze world about ten years ago.
1. Will I have to download and install a compiler and a linker?
2. Will I have to recompile the kernel to use the updated NetworkManager?
Advise please. Thanks.
| Max (m-gorodok) wrote : | #120 |
> 1. Will I have to download and install a compiler and a linker?
Sure:
sudo apt-get install build-essential
> 2. Will I have to recompile the kernel to use the updated
> NetworkManager?
No, just network-manager:
sudo apt-get build-dep network-manager
apt-get source network-manager
cd network-
First of all I would suggest you to check that original package
can be build without any errors. For dpkg-buildpackage
I had to disable test (debian/rules file, --enable-tests=no
instead of --with-tests in ./configure invocation)
fakeroot dpkg-buildpackage -b -uc
Successful build will finish with .deb files created
in the parent directory.. Edit .c files as described
in Comment 114. It is better to edit debian/changelog
file as well and add an additional entry to the top of the file
with another version suffix. This step will allow
to avoid confusion which package is installed.
Again
fakeroot dpkg-buildpackage -b -uc
(option -nc can be added to compile only updated files)
You should have new .deb file that can be installed with
sudo dpkg -i ../<exact name of network-
The details can be found in
http://
| Ernie 07 (ernestboyd) wrote : | #121 |
Max,
I did a quick search for the NetworkManger source code. Many variations and levels of development exist.
Since I have no experience as a developer or QA type in the Ubuntu arena and have repeatedly submitted DETAILED steps for this 100% reproducible problem, I will pass on trying to fix it myself.
| Paul F (boxjunk) wrote : | #122 |
I'm experiencing similar issues on an EXT-3 filesystem. There are no inode/block errors reported by fsck but the root filesystem (/ is mounted on /dev/sda2 in my case) fails the fsck check at boot.
% dmesg | grep sda2
EXT3-fs (sda2): recovery required on readonly filesystem
EXT3-fs (sda2): write access will be enabled during recovery
EXT3-fs (sda2): recovery complete
EXT3-fs (sda2): mounted filesystem with ordered data mode
[Edited for brevity]
This happens on every boot. The other partitions (and there are 6 including swap) all pass the fsck check.
The workaround of deselecting "Available to all users" in Network Connections discussed above works for me. Seems reasonable to assume that this is not filesystem specific and that the shutdown is not clean for some reason.
Quantal 12.10
Linux 3.5.0-28-generic #48-Ubuntu SMP Tue Apr 23 23:05:48 UTC 2013 athlon i686 GNU/Linux
| Paul F (boxjunk) wrote : | #123 |
See also LP: #869635.
| Max (m-gorodok) wrote : | #124 |
Paul, In Quantal 12.10 it is the bug lp: #1124803
"NetworkManager doesn't respond to SIGTERM in daemon mode".
And that patch fixes the issue for network-manager 0.9.6
(however there are no .deb packages).
In 13.04 Raring, network-manager maintainers in Ubuntu missed
that upstream dropped distro-specific defines,
so network-
the bug lp: #1169614 "dhclient is not stopped during shutdown".
These two bugs lead to the same result during shutdown:
"mount: / is busy"
That is actually hidden from the users by the plymouth
splash screen.
| Ernie 07 (ernestboyd) wrote : | #125 |
Except for dependency upon Nvidia drivers, I would be quite satisfied with 12,04.
I really would like to put Nvidia drivers in the trash where they belong.
The list of 13.xx BUGs preventing the switch from 12.04 is getting shorter.
Please shorten the list by fixing this BUG promptly. Thanks.
| Max (m-gorodok) wrote : | #126 |
There is at least one more cause of busy / besides network-manager
in Raring 13.10.
I have noticed file /var/log/
for writing by init when /etc/init.
It seems that the problem was caused by absent pack file
in /var/lib/
after installation.
I can not find config responsible for presence of
/sys/kernel/
required for ureadahead.
I am in doubt if "stop on" condition is intentionally missed
in /etc/init/
I do not like ureadahead-other status
# initctl status ureadahead-other
ureadahead-other start/running, process 811
# ps uw 811
USER PID %CPU %MEM VSZ RSS TTY STAT START TIME COMMAND
(no process 811)
| Steve Langasek (vorlon) wrote : | #127 |
Hi Max,
On Tue, May 14, 2013 at 04:17:18PM -0000, Max wrote:
> There is at least one more cause of busy / besides network-manager
> in Raring 13.10.
> I have noticed file /var/log/
> for writing by init when /etc/init.
> It seems that the problem was caused by absent pack file
> in /var/lib/
> after installation.
> I can not find config responsible for presence of
> /sys/kernel/
> required for ureadahead.
> I am in doubt if "stop on" condition is intentionally missed
> in /etc/init/
> I do not like ureadahead-other status
> # initctl status ureadahead-other
> ureadahead-other start/running, process 811
> # ps uw 811
> USER PID %CPU %MEM VSZ RSS TTY STAT START TIME COMMAND
>
> (no process 811)
'ps uw' only shows processes belonging to the current user. Please check
'ps auwx'.
Also, please file a bug report against the ureadahead package for this
package, and post the number of the new bug here. When filing that new bug,
please attach the contents of /var/log/
| tags: | removed: kernel-da-key |
| Max (m-gorodok) wrote : | #128 |
> 'ps uw' only shows processes belonging to the current user.
Unless PID is specified
> Also, please file a bug report against the ureadahead package
> for this package, and post the number of the new bug here.
I would rather file a bug against upstart.
Ureadahead does his job and exits with status 4 or 5
depending either absent pack file or mainline kernel is running.
Init on the other hand does not close the log file for some reason.
There is a chance however that this variant of bug might be triggered
by more than one mount in addition to root filesystem.
/etc/init/
| Steve Langasek (vorlon) wrote : | #129 |
On Thu, May 16, 2013 at 04:21:12PM -0000, Max wrote:
>> 'ps uw' only shows processes belonging to the current user.
> Unless PID is specified
Oops, true. So the process is definitely not running.
> > Also, please file a bug report against the ureadahead package
> > for this package, and post the number of the new bug here.
> I would rather file a bug against upstart.
As the developer, I am asking you to file a bug against ureadahead.
> Ureadahead does his job and exits with status 4 or 5
> depending either absent pack file or mainline kernel is running.
> Init on the other hand does not close the log file for some reason.
Because ureadahead is not behaving correctly under upstart, and somehow
manages to cause upstart to not notice that the process has exited.
| Max (m-gorodok) wrote : | #130 |
Bug #1181528 for ureadahead/upstart issue.
Unfortunately the conditions to reproduce are not clear.
| Max (m-gorodok) wrote : | #131 |
The cause of ureadahead issue is upstart. The pure case
unrelated to ureadahead is Bug lp: #1181789.
In some cases upstart might hold log files
opened for writing for other daemons.
| John Clark (clarkjc) wrote : | #132 |
I added the following line to /etc/init/
console none
This prevents the log file from keeping the file system busy. The only downside is that anything logged by ureadahead-other goes to /dev/null instead.
| John Clark (clarkjc) wrote : | #133 |
P.S. You will have to reboot 2 times after adding "console none" for it to work.
| Clint Byrum (clint-fewbar) wrote : | #134 |
This does seem like a bug in upstart. It seems to me that there needs to be a command to say "upstart, close all of your log files and do not reopen them" so that one can remount / readonly. Systems may have things that want to keep running right up until poweroff/reboot, but that make use of 'console log'.
| Ivan Larionov (xeron-oskom) wrote : | #135 |
Finally did a workaround of this bug with:
1) killing dhclient on umountfs step
2) /etc/init/
AFAIK this bug exists since 12.10 and I have no idea why it still doesn't fixed.
| Vedran Rodic (vrodic) wrote : | #136 |
In my case the bug with unclean shutdown happens only when my machine (Thinkpad X230) is docked to the Thinkpad ultrabase when shutting it down.
When I shutdown outside of a dock, everything is fine. I don't use ureadahead (have SSD), doesn't matter if there are mounted network filesystems or not, if NetworkManager is running or not.
| Steve Dodd (anarchetic) wrote : | #137 |
My problems (on current saucy) were caused by bugs in upstart (affecting ureadahead) and network-manager. The patches in bug #1181789 and bug #1169614 give me a clean unmount and shutdown.
| Dmitry Kasatkin (dmitry-kasatkin) wrote : | #138 |
I have the same problem on 13.04, which is solved by 2 steps (as mentioned above):
1) uninstalling ureadahead or adding "console none" to /etc/init/
2) killing dhclient in umountfs.
Indeed, why it has not been fixed for "years"....
| Vedran Rodic (vrodic) wrote : | #139 |
Dmitry, I confirm your solution. I already uninstalled ureadahead (no need for it with a SSD).
I added killall dhclient to my /etc/init.
This problem happens for me only when I use the regular wired ethernet on my ThinkPad X230 (not just when the laptop is docked to the UltraBase as I've reported earlier) . It doesn't happen when I'm using wireless.
| Vedran Rodic (vrodic) wrote : | #140 |
I've tried patches in mentioned in comment #137, but they didn't help.
| Christian Niemeyer (christian-niemeyer) wrote : | #141 |
This still happens in 13.10 (saucy). This time I installed the Beta-2 of Lubuntu (thus using an lxsession). Reboot or shutdown fails everytime. It hangs for around ten seconds, then it reboots and fsck shows "deleted orphaned inode".
Only helps to uninstall network-manager-*, nm-*, modemmanager, ureadahead.
How come this hasn't been fixed yet? It is reproduceable all the time for me. (My router is fine and network also. I had problems with my old router and dnsmasq in 12.04 but no unclean shutdowns.)
| Ivan Larionov (xeron-oskom) wrote : | #142 |
Yeah, still exists in 13.10.
| Robstarusa (rob-naseca) wrote : | #143 |
I'm seeing this in 13.10 as well.
| Christian Niemeyer (christian-niemeyer) wrote : | #144 |
It occurs that the problem did *not* exist after a recent clean install of 13.10 (64bit Desktop CD) on a friend's notebook. While it still happens on my desktop PC.
Differences:
On the notebook we used wireless (b43 out of the box) internet during installation. Reboot into new system, login, shutdown is clean.
On my desktop I have no wireless card at all. I use wired connection during installation. Reboot into new system, login, using system, shutdown is unclean.
I haven't double-checked this though. But it maybe is a hint, that this problem occurs on machines with no wireless possibilities.
| Steve Dodd (anarchetic) wrote : | #145 |
That sounds plausible - I would guess wireless connections are usually torn
down at the end of the user session (i.e. logout) whereas I assume wired
connections persist right to system shutdown??
On Oct 21, 2013 3:01 PM, "Christian Niemeyer" <email address hidden>
wrote:
> It occurs that the problem did *not* exist after a recent clean install
> of 13.10 (64bit Desktop CD) on a friend's notebook. While it still
> happens on my desktop PC.
>
> Differences:
>
> On the notebook we used wireless (b43 out of the box) internet during
> installation. Reboot into new system, login, shutdown is clean.
>
> On my desktop I have no wireless card at all. I use wired connection
> during installation. Reboot into new system, login, using system,
> shutdown is unclean.
>
> I haven't double-checked this though. But it maybe is a hint, that this
> problem occurs on machines with no wireless possibilities.
>
> --
> You received this bug notification because you are subscribed to the bug
> report.
> https:/
>
> Title:
> Ext4 corruption associated with shutdown of Ubuntu 12.10
>
> To manage notifications about this bug go to:
> https:/
>
| gweg (gweg) wrote : | #146 |
I did a bit of hacking on init.d/umountroot, adding lsof and ps -ef after the remount fails.
I could see that dhclient was still running, so I added before the remount: pkill -9 dhclient
After this change, dhclient was gone, but the remount still failed. In lsof output I can see:
init 1 root 15w REG 8,24 1134 438383 /var/log/
It seems like there is a problem in the upstart init where it is not closing files, besides the problem with dhclient.
| gweg (gweg) wrote : | #147 |
Sorry, forgot to added version info to #146
Ubuntu Saucy 32-bit, package version: upstart 1.10-0ubuntu7 i386
| Steve Langasek (vorlon) wrote : | #148 |
On Wed, Oct 23, 2013 at 10:15:46PM -0000, Gregor Larson wrote:
> init 1 root 15w REG 8,24 1134 438383
> /var/log/
mountall is a service that's supposed to run once at boot and then exit. If
mountall is still running when you shut the system down, then you probably
have a problem in your /etc/fstab (non-existent devices).
We could safeguard against this by making the mountall job exit when we
switch to runlevel 0 or 6. Could you please file a bug against the mountall
package for this issue?
> It seems like there is a problem in the upstart init where it is not
> closing files, besides the problem with dhclient.
There are many possible causes for the filesystem being held writable at
shutdown; it's best to identify each of these and address them individually,
rather than trying to track them all on a single metabug.
| Clint Byrum (clint-fewbar) wrote : | #149 |
Excerpts from Steve Dodd's message of 2013-10-21 16:16:29 UTC:
> That sounds plausible - I would guess wireless connections are usually torn
> down at the end of the user session (i.e. logout) whereas I assume wired
> connections persist right to system shutdown??
In theory they're brought down when network-manager is stopped. In
practice they may leave lingering bits briefly after that.
| Alexander (lxandr) wrote : | #150 |
Guys, come on!
What the heck network-manager and network connections are you talking about?!
This really pissed me off already!
As I've said earlier, the problem is NOT in network-manager!
https:/
because it appears even when network-manager is not installed.
I can assume (or even be sure), that network-manager HAVE some bug(s) associated with this problem, but the main cause - it's not a network-manager. And I'm sure it's in upstart. Believe me, I've spent a lot of time trying to debug this problem...
You can see my comments (and debug logs) about this problem above.
That was the boiling point.
I've moved to Debian.
| Steve Langasek (vorlon) wrote : | #151 |
So when I wrote 6 months ago that:
> If you can reproduce this issue, please file a new bug report against
> the sysvinit-utils package with details. It is certainly unrelated to the
> common issue being described here.
Rather than doing this to help yourself, you switch distros, decide that upstart is to blame for a part of the system that is clearly managed by another package, and stay subscribed to the bug so that you can yell at people who are experiencing the bug that was originally reported - a bug that is unrelated to the issue that you were experiencing?
This bug tracker is for helping users resolve bugs in Ubuntu. If you're not using Ubuntu, and you're not helping fix the bugs, your comments are not needed here.
| Clint Byrum (clint-fewbar) wrote : | #152 |
Excerpts from Alexander's message of 2013-10-25 05:39:16 UTC:
> Guys, come on!
> What the heck network-manager and network connections are you talking about?!
> This really pissed me off already!
> As I've said earlier, the problem is NOT in network-manager!
> https:/
> because it appears even when network-manager is not installed.
> I can assume (or even be sure), that network-manager HAVE some bug(s) associated with this problem, but the main cause - it's not a network-manager. And I'm sure it's in upstart. Believe me, I've spent a lot of time trying to debug this problem...
> You can see my comments (and debug logs) about this problem above.
>
> That was the boiling point.
> I've moved to Debian.
>
Alexander I was mistaken is all. Good luck in the future, and please
come back when you have helpful constructive comments.
(BTW the log files that are open are being held open not by upstart
directly, but by processes that are refusing to die and thus refusing to
close their stdout. Upstart would be in error if it were to just close
these log files while the process is still wanting to write to them.)
| Christian Niemeyer (christian-niemeyer) wrote : | #153 |
Regardless of that one comment above. But it is really frustrating if now the user's of ubuntu get blamed for not filing the correct bug. Dear folks at Canonical, you have so much information in this one thread, about how to reproduce this error. I'm not that experienced. So please, could someone reproduce this error (take a machine without any wireless capabilities) and then file the correct bug, if this bug report here is not "good enough" for you.
It's pretty amazing that a bug that causes **filesystem errors** (if minor or not minor) does not get fixed at all and now the users get partly blamed for not filing the bug on the correct package? Hello? A default installation causes filesystem errors, reproduceable. Would someone please take those hints in this thread seriously? Like: install on a machine with a wired connection on no wireless adapters. I can reproduce this 100%.
My fix is (taken from this thread): "console none" in /etc/init/
And more important in /etc/init/umountfs adding the following lines in the beginning of the file:
service networking stop
sleep 1
service networking start
sleep 1
service networking stop
sleep 1
killall dhclient
sleep 1
That worked for me. I don't know what package to file this bug against, because it seems that it happens out of certain hardware and interaction between different packages. I'm not blaming upstart at all. I just want this CRITICAL bug to be fixed. It is around since 12.04/12.10. That's "amazing".
| Andrej Mernik (r33d3m33r-deactivatedaccount) wrote : | #154 |
- Bootchart image Edit (427.4 KiB, image/png)
{kind=link}
I have tried some workarounds from the comments and nothing seems to work. Fsck still runs at every boot. Bootchart included.
| Bernd (midox) wrote : | #155 |
due the respawn of some processes i think they are (re)started again even on shutdown
so they are running if the / is remounted readonly
and that is why it fails
i think upstart should insure that all processes are killed (also the respawning) at the moment we mount / readonly on halt or reboot
my workaround(dirty hack) in the moment
is adding a killall5 -9 just before line 86 of /etc/rc6/umountroot
that works for me and gives no fsck's on my next (re)boots
conclusion for me it's not an NM or Kernel failure
its just a wrong way the shutdown procedure is handled by mixing upstart and sysv initscripts
| Clint Byrum (clint-fewbar) wrote : | #156 |
Excerpts from Bernd's message of 2014-01-05 21:37:21 UTC:
> due the respawn of some processes i think they are (re)started again even on shutdown
> so they are running if the / is remounted readonly
> and that is why it fails
>
> i think upstart should insure that all processes are killed (also the
> respawning) at the moment we mount / readonly on halt or reboot
>
> my workaround(dirty hack) in the moment
> is adding a killall5 -9 just before line 86 of /etc/rc6/umountroot
> that works for me and gives no fsck's on my next (re)boots
>
> conclusion for me it's not an NM or Kernel failure
> its just a wrong way the shutdown procedure is handled by mixing upstart and sysv initscripts
>
If you kill everything then the plymouth screen will go away, NFS rootmay
fail, etc. There are other reasons it works the way it does. What is
needed is a better mechanism to notify the user of what is going on and
help them deal with it, and to also report those situations as bugs so
we can deal with them.
| Bernd (midox) wrote : | #157 |
You are definivly right in that case
a bug is allready opened(Bug #1073433 ) as i writing a comment to it
The normal user wants a clean shutdown or reboot and as I wrote its a dirty hack until this problem is resolved by the maintainers
we know the schutdown process isn't working correctly as i can see 154 comments on this issue
and the @S60umountroot proccess is definitivly just before reboot/shutdown process
and as i understand it in the right way
@S20sendsigs should stop all running (upstart) processes after that we can
@S31umountnfs.sh which is run before
@S40umountfs which runs before
@S60umountroot which expects that there are no more running processes (or open files)(otherwise we can't remount or unmount) left and at last runs (on a normal system nothing is between them)
@S90reboot
if there ane running processes at that moment that root is remountet or unmounted at shutdown or halt then fsck will complain on next boot.
you could check with adding /bin/ps aux >> /ps_schutdown.log just before line 86 in the /etc/rc6/
i tried even adding a sleep 60 there to give the runnings some time to end but that wasn't working either because of the respawning ones
an killall5 -9 at that point shoulndt hurt because nfs and fs(tmpfs,run and so on) should be allready unmounted
plymouth is maybe the culprit if it because it stays alive till the bitter end so we have to kill it at this time
i dont mind to have a one or two second blackscreen just before the computer is off or reboots
an option could be that we load plymouth in to memory on shutdown so that there is no disk accces on shutdown
just my 2ct's on this
| Øyvind Stegard (oyvindstegard) wrote : | #158 |
- Output of lsof just before remount,ro of / Edit (29.9 KiB, text/plain)
In my case it's a dhclient process that likely respawns and prevents remount to read-only of root fs, due to a lease file opened for writing under /var/lib/
Attaching lsof output obtained just before call to umount in /etc/init.
As far as I can see, the only process having a regular file opened for writing on the root file system is dhclient:
dhclient 1317 root 4w REG 8,5 578 530637 /var/lib/
Clean Ubuntu 13.10 installation. This has certainly become an annoying and long lasting bug now.
| Øyvind Stegard (oyvindstegard) wrote : | #159 |
I'd guess patch in bug 1169614 would help in my case (dhclient process). Any progress on evaluating and possibly including the patch provided in that bug ?
| Benny (benny-malengier) wrote : | #160 |
Lennert of systemd refers to this bug on google+. He outlines a fix for the simple case: https:/
| Steve Dodd (anarchetic) wrote : | #161 |
This does seem to be getting kind of embarassing. With modern journalled
filesystems on relatively straightforward hardware configs an unclean
shutdown shouldn't be the end of the world (after all, power failures
can happen), but it's not "nice" either.
Unfortunately we also seem to have a hell of a lot of noise on Launchpad
about this, people conflating different issues and causes, not reading
previous posts properly, etc., etc.
I'll be upgrading to 14.04 from 12.04 for main machines when it comes
out, if the problem's still present then I will have another look. Last
time I did, my own problems were caused by dhclient and ureadahead.. I
can't remember which if any of those have now been fixed. If nothing
else, pushing those fixes out will show if there are other outstanding
shutdown problems affecting a lot of users.
On Wed, Jan 22, 2014 at 09:19:13AM -0000, Benny wrote:
> Lennert of systemd refers to this bug on google+. He outlines a fix for
> the simple case:
> https:/
>
> --
> You received this bug notification because you are subscribed to the bug
> report.
> https:/
>
> Title:
> Ext4 corruption associated with shutdown of Ubuntu 12.10
>
> To manage notifications about this bug go to:
> https:/
| Max (m-gorodok) wrote : | #162 |
Steve Dodd:
> Last time I did, my own problems were caused by dhclient and ureadahead..
It is not an ureadahead issue, it is an extra fork in upstart to launch shell for ureadahead if more than one partition mounted.
| Steve Langasek (vorlon) wrote : | #163 |
On Wed, Jan 22, 2014 at 09:19:13AM -0000, Benny wrote:
> Lennert of systemd refers to this bug on google+. He outlines a fix for
> the simple case:
The fix he outlines is not for this bug. It's not for a bug we have in
upstart in Ubuntu at all; we already reliably ensure telinit u on upgrade of
all of upstart's library dependencies, which are finite and accounted for.
| Clint Byrum (clint-fewbar) wrote : | #164 |
Excerpts from Steve Langasek's message of 2014-01-22 16:51:06 UTC:
> On Wed, Jan 22, 2014 at 09:19:13AM -0000, Benny wrote:
> > Lennert of systemd refers to this bug on google+. He outlines a fix for
> > the simple case:
>
> The fix he outlines is not for this bug. It's not for a bug we have in
> upstart in Ubuntu at all; we already reliably ensure telinit u on upgrade of
> all of upstart's library dependencies, which are finite and accounted for.
>
I feel like he outlined two bugs. That one, I agree, is handled and
"meh".
The other one is the one that would sweep up the mess we occasionally
see when something misbehaves.
I'd like to see Ubuntu's shutdown do more to protect against that
failure mode.
| Bernd Schubert (aakef) wrote : | #165 |
On 01/22/2014 05:51 PM, Steve Langasek wrote:
> On Wed, Jan 22, 2014 at 09:19:13AM -0000, Benny wrote:
>> Lennert of systemd refers to this bug on google+. He outlines a fix for
>> the simple case:
>
> The fix he outlines is not for this bug. It's not for a bug we have in
> upstart in Ubuntu at all; we already reliably ensure telinit u on upgrade of
> all of upstart's library dependencies, which are finite and accounted for.
Why shouldn't switching to an independent file system (tmpfs/initramfs)
and shutdown-
without exceptions. You can even entirely unmount the old root, no need
for remounting it read-only anymore.
| Steve Langasek (vorlon) wrote : | #166 |
On Wed, Jan 22, 2014 at 05:11:03PM -0000, Clint Byrum wrote:
> The other one is the one that would sweep up the mess we occasionally
> see when something misbehaves.
> I'd like to see Ubuntu's shutdown do more to protect against that
> failure mode.
I would, too, but I don't agree that the method he proposes actually does
this. Killing processes and unmounting devices in a loop is basically what
we do already; the key difference is that some filesystems - potentially
even including the root filesystem - may require additional daemon processes
for their operation. This is the case for example if you have network
filesystems mounted and are using NetworkManager, or if you use
gss-encrypted NFS, or iscsi. So "kill all processes and unmount all
filesystems in a loop" is not a reliable shutdown mechanism, it just moves
the problem cases somewhere that Lennart apparently isn't seeing them.
One of the problems we've seen repeatedly with trying to get clean shutdown
involves NetworkManager's child processes *being* killed while they're still
needed as part of managing the network. This is not a bug that's fixed by
killing more processes.
There may be other failure scenarios that need to be addressed. Part of the
problem has been a lack of information about what's actually holding the
root filesystem open in these cases. There's a pending merge proposal on
sysvinit that should help us gather this information.
| Steve Dodd (anarchetic) wrote : | #167 |
On Wed, Jan 22, 2014 at 04:13:19PM -0000, Max wrote:
> Steve Dodd:
> > Last time I did, my own problems were caused by dhclient and ureadahead..
>
> It is not an ureadahead issue, it is an extra fork in upstart to launch
> shell for ureadahead if more than one partition mounted.
Yes, I know - I was summarizing!
On Wed, Jan 22, 2014 at 04:51:06PM -0000, Steve Langasek wrote:
> On Wed, Jan 22, 2014 at 09:19:13AM -0000, Benny wrote:
> > Lennert of systemd refers to this bug on google+. He outlines a fix for
> > the simple case:
>
> The fix he outlines is not for this bug. It's not for a bug we have in
> upstart in Ubuntu at all; we already reliably ensure telinit u on upgrade of
> all of upstart's library dependencies, which are finite and accounted for.
Good to know, thank you.
On Wed, Jan 22, 2014 at 06:21:52PM -0000, Steve Langasek wrote:
[..]
> There may be other failure scenarios that need to be addressed. Part of the
> problem has been a lack of information about what's actually holding the
> root filesystem open in these cases. There's a pending merge proposal on
> sysvinit that should help us gather this information.
I had been going to suggest this a while back - automated apport
reporting of unclean shutdowns, with as much cause information as
possible?
I will try to do something constructive like boot into trusty and make
sure my personal issues have been resolved (I've not looked at this for
a few months.) I'm updating my images as we speak.
Steve
| Ivan Larionov (xeron-oskom) wrote : | #168 |
14.04 — it's still a problem (dhclient issue).
| tags: | added: trusty |
| Ivan Larionov (xeron-oskom) wrote : | #169 |
Looks like bug #1169614 was finally fixed.
But there's one more bug which cause same problem: bug #1307008
| Changed in network-manager (Ubuntu): | |
| status: | Triaged → Fix Released |
| Changed in linux (Ubuntu): | |
| status: | Incomplete → Invalid |
| Changed in upstart: | |
| status: | Confirmed → Invalid |
| Changed in upstart (Ubuntu): | |
| status: | Confirmed → Invalid |
| Changed in linux (Ubuntu): | |
| status: | Invalid → Incomplete |
| Changed in upstart: | |
| status: | Invalid → Confirmed |
| Changed in upstart (Ubuntu): | |
| status: | Invalid → Confirmed |
Would it be possible for you to test the latest upstream kernel? Refer to https:/
Once you've tested the upstream kernel, please remove the 'needs-
If this bug is fixed in the mainline kernel, please add the following tag 'kernel-
If the mainline kernel does not fix this bug, please add the tag: 'kernel-
If you are unable to test the mainline kernel, for example it will not boot, please add the tag: 'kernel-
Once testing of the upstream kernel is complete, please mark this bug as "Confirmed".
Thanks in advance.
[0] http://