[Acer AR320 F1 and Acer AR160 F1] Halting shortly after booting with 10.04.3
Bug #897773 reported by
Brendan Donegan
This bug affects 2 people
| Affects | Status | Importance | Assigned to | Milestone | |
|---|---|---|---|---|---|
| HW-labs |
Fix Released
|
High
|
Jeff Lane | ||
Bug Description
We have two Acer servers which, when they have the Lucid 10.04.3 halt shortly after booting, this didn't happen with 10.04.2
The message 'Uhhuh. NMI received for unknown reason 21 on CPU 0.' has been seen shortly before the halting occurred on one of the systems (the AR320).
We have not been able to reproduce the behaviour with the release Lucid kernel, no matter how long we wait.
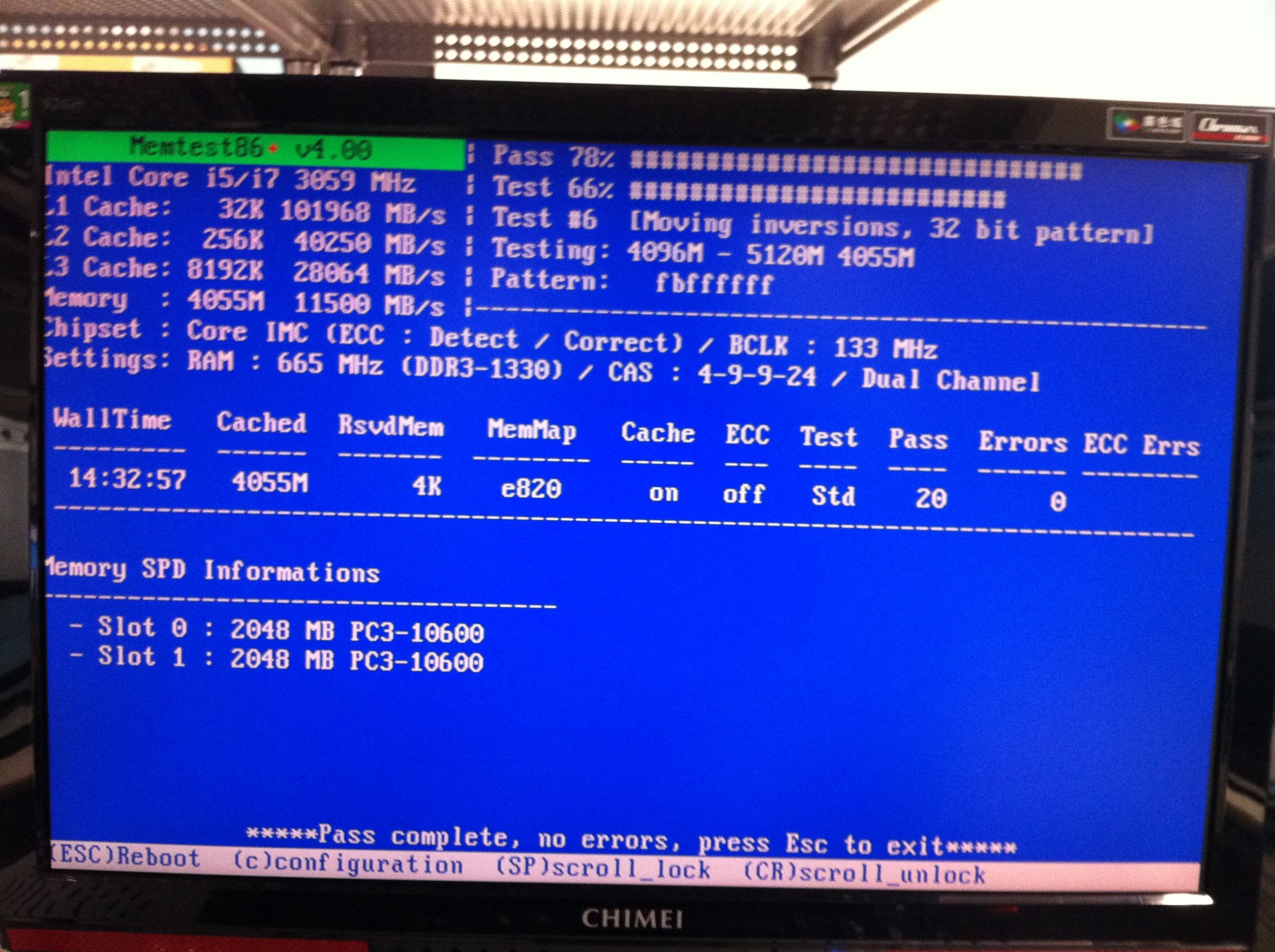
Next steps are to run 'memtest' on both systems and do an apport-collect if possible.
| summary: |
- [Acer AR320 F1 and Acer AR160 F1] Halting shortly after booting + [Acer AR320 F1 and Acer AR160 F1] Halting shortly after booting with + Lucid (2.6.32-36.79) -proposed kernel |

| Changed in linux (Ubuntu): | |
| importance: | Undecided → High |
| status: | Incomplete → New |
| tags: | added: bot-stop-nagging |
| summary: |
[Acer AR320 F1 and Acer AR160 F1] Halting shortly after booting with - Lucid (2.6.32-36.79) -proposed kernel + 10.04.3 |
| tags: | removed: bot-stop-nagging |
{kind=link}
To post a comment you must log in.
This bug is missing log files that will aid in diagnosing the problem. From a terminal window please run:
apport-collect 897773
and then change the status of the bug to 'Confirmed'.
If, due to the nature of the issue you have encountered, you are unable to run this command, please add a comment stating that fact and change the bug status to 'Confirmed'.
This change has been made by an automated script, maintained by the Ubuntu Kernel Team.