
Degraded RAID boot fails: kobject_add_internal failed for dev-sda1 with -EEXIST, don't try to register things with the same name in the same directory
Bug #334994 reported by
Dustin Kirkland
This bug affects 1 person
| Affects | Status | Importance | Assigned to | Milestone | |
|---|---|---|---|---|---|
| linux (Ubuntu) |
Fix Released
|
High
|
Andy Whitcroft | ||
| Jaunty |
Fix Released
|
High
|
Andy Whitcroft | ||
| mdadm (Ubuntu) |
Invalid
|
High
|
Canonical Server | ||
| Jaunty |
Invalid
|
High
|
Canonical Server | ||
Bug Description
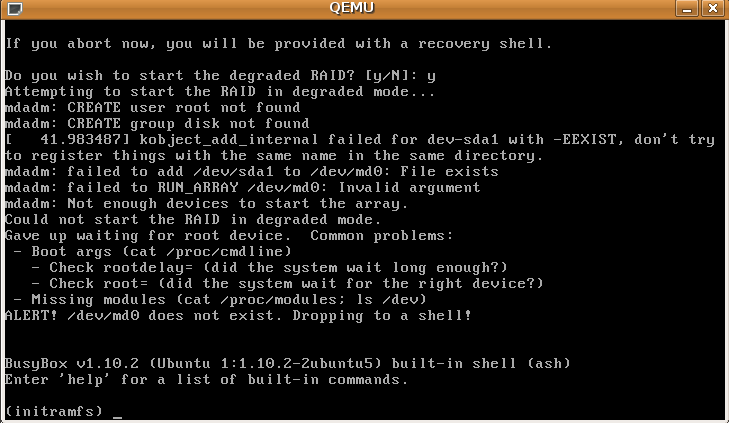
Booting degraded RAID has regressed in Jaunty.
When I try to boot a degraded RAID, I get the error messages in the attached screenshot.
There appears to be a nasty bug in the kernel md code that's causing this.
kobject_
This is on an up-to-date Jaunty server.
:-Dustin

{kind=link}
| Changed in linux (Ubuntu): | |
| milestone: | jaunty-alpha-6 → ubuntu-9.04-beta |
| Changed in linux (Ubuntu Jaunty): | |
| status: | In Progress → Invalid |
| Changed in mdadm: | |
| assignee: | nobody → canonical-server |
| status: | New → Triaged |
| Changed in linux: | |
| status: | Confirmed → In Progress |
| Changed in linux: | |
| milestone: | ubuntu-9.04-beta → ubuntu-9.04 |
| Changed in linux (Ubuntu Jaunty): | |
| status: | In Progress → Fix Committed |
To post a comment you must log in.
Screenshot attached.