
Virtual machine soft lockup - CPU gets stuck for XX seconds
| Affects | Status | Importance | Assigned to | Milestone | |
|---|---|---|---|---|---|
| linux (Ubuntu) |
Won't Fix
|
Undecided
|
Unassigned | ||
Bug Description
I am running a virtual machine using KVM (managed via libvirt, installed with vmbuilder).
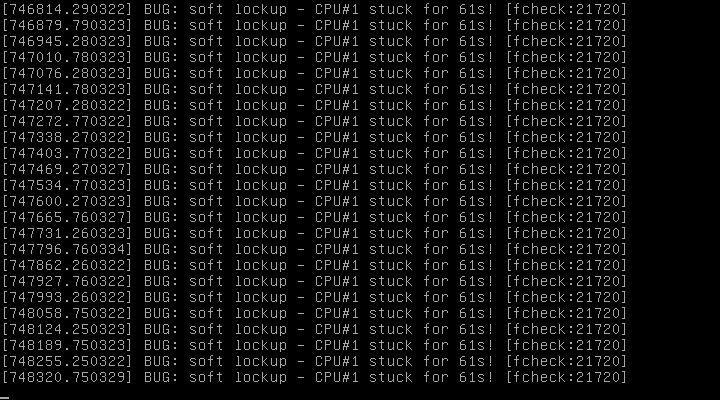
For one particular virtual machine only on the host (so far), it randomly stops responding occasionally and needs a reboot. On the screen (when I VNC to it) I get messages like "BUG: soft lockup - CPU#1 stuck for 61s! [fcheck:7246]"
but it doesn't have to be fcheck, it can be any process.
The other virtual machine on the host doesn't crash at the same time - it hasn't actually crashed yet at all since it was installed, although it uses the same kernel, was installed with the same commands and has the same versions of everything. The virtual machine that crashes is fine for days, even weeks, but then crashes.
I am graphing both the virtual machine and the host via Munin and nothing unusual is happening around the times of these crashes, the load on both is very low. I have attached the logs (/var/log/syslog) for two example crashes.

{kind=link}
{kind=link}
Sorry if you got lots of e-mails there, I couldn't see how to add multiple attachments.
I have more information on this.
For the virtual server host where none of our virtual machines suffer from this, we are running the 2.6.27-7-server kernel.
For the virtual server host where just one of our virtual machines suffer from this, we are running the 2.6.27-11-server kernel.
Are there any changes between the two versions that could cause something like this? Would you recommend I try the older kernel?