
disk detection is real slow with some hardware (timout shell drops)
| Affects | Status | Importance | Assigned to | Milestone | |
|---|---|---|---|---|---|
| initramfs-tools (Ubuntu) |
Won't Fix
|
Undecided
|
Unassigned | ||
| linux (Ubuntu) |
Expired
|
Undecided
|
Unassigned | ||
| mdadm (Ubuntu) |
Invalid
|
Undecided
|
Unassigned | ||
| mountall (Ubuntu) |
Invalid
|
Wishlist
|
Unassigned | ||
Bug Description
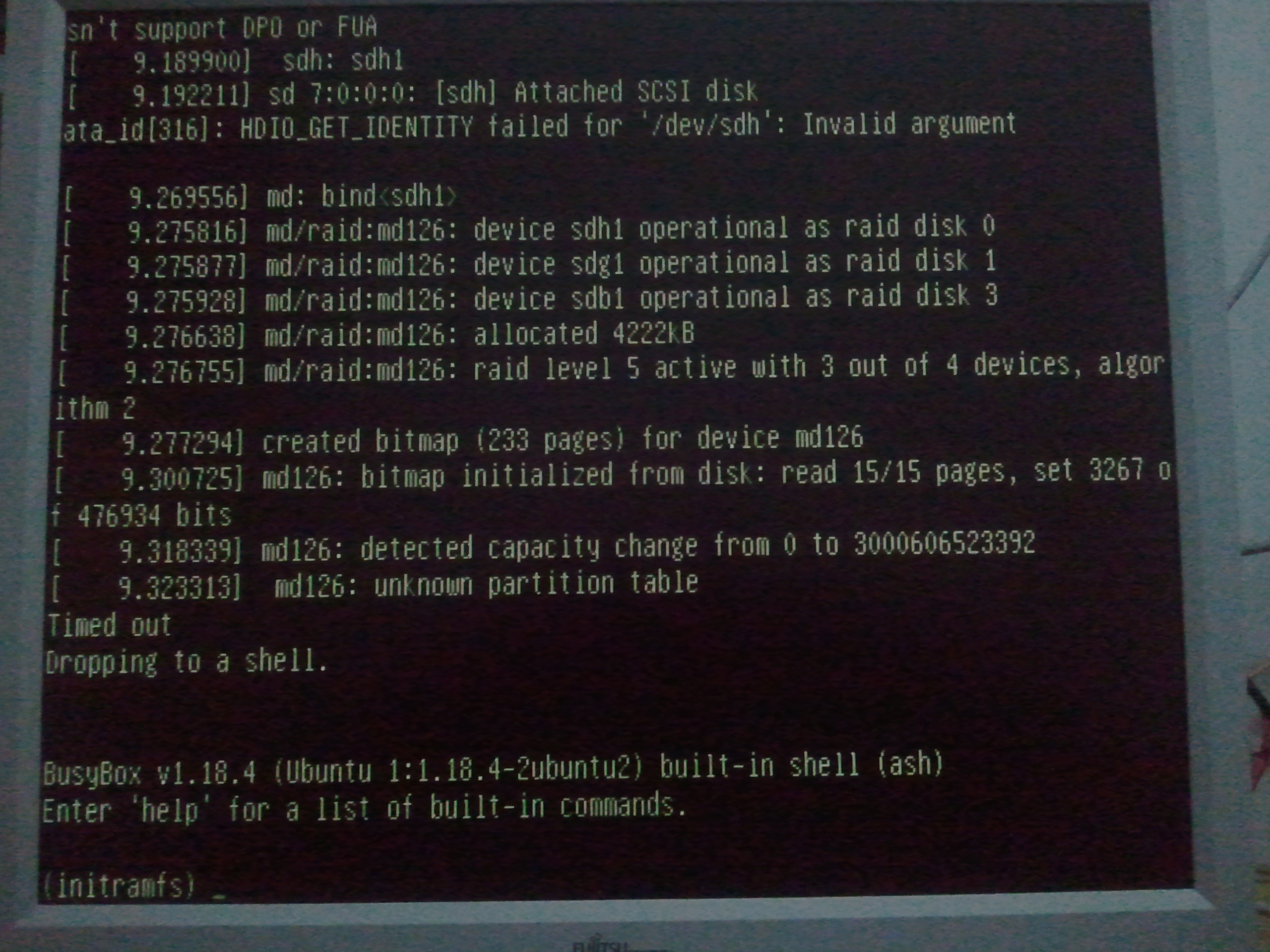
I have installed Intrepid server i386 beta on a Dell PowerEdge 600SC. Everything seemed to install fine but upon boot it always drops into the BusyBox shell. The RAID is *not* degraded. At the BusyBox prompt if I type 'exit' it will proceed to boot normally and both RAID1 drives show healthy with all members. I have tried the install twice.
This has shown to be a timeout issue with slow hardware.
* initramfs: Default rootdelay may need to be larger and event driven upstart used.
* linux: The long delay may have its cause here.
* mdadm: As RAIDs may take minutes until they come up, but regular ones are quick, this should be handled nicely:
* This functionality is similar to and could most easily be added with upstart events (the temporary tool) mountall:
"NOTICE: /dev/mdX required for the root filesystem didn't get up within the last 10 seconds.
We continue to wait up to a total of xxx seconds complying to the ATA spec
before attempting to start the array degraded.
(You can lower this timeout by setting the rootdelay= parameter.)
<countdown> seconds to go.
Press [ESC] to stop waiting and to enter a rescue shell.

| description: | updated |
| Changed in mountall (Ubuntu): | |
| importance: | Undecided → Wishlist |
| status: | New → Triaged |
| tags: | added: review-request |
{kind=link}
Michael-
Can you also:
$ cat /etc/initramfs-
and post here.
:-Dustin