
boot-time race condition initializing md
| Affects | Status | Importance | Assigned to | Milestone | |
|---|---|---|---|---|---|
| initramfs-tools (Ubuntu) |
Fix Released
|
Critical
|
Scott James Remnant (Canonical) | ||
| mdadm (Ubuntu) |
Invalid
|
Undecided
|
Scott James Remnant (Canonical) | ||
| udev (Ubuntu) |
Invalid
|
Undecided
|
Unassigned | ||
Bug Description
Binary package hint: mdadm
I originally contributed some feedback to Bug #75681. It is currently reported as being fixed, but my problem still persists. The person that closed it recommended that we open new bugs if we're still having problems. I've reproduced my feedback here to save looking it up:
==========
FWIW, I have the problem, exactly as described, with a IDE-only system.
I attempted this with both an Edgy->Feisty upgrade (mid Februrary), and a fresh install of Herd5.
I'm running straight RAID1 for all my volumes:
md0 -> hda1/hdc1 -> /boot
md1 -> hda5/hdc5 -> /
md2 -> hda6/hdc6 -> /usr
md3 -> hda7/hdc7 -> /tmp
md4 -> hda8/hdc8 -> swap
md5 -> hda9/hdc9 -> /var
md6 -> hda10/hdc10 -> /export
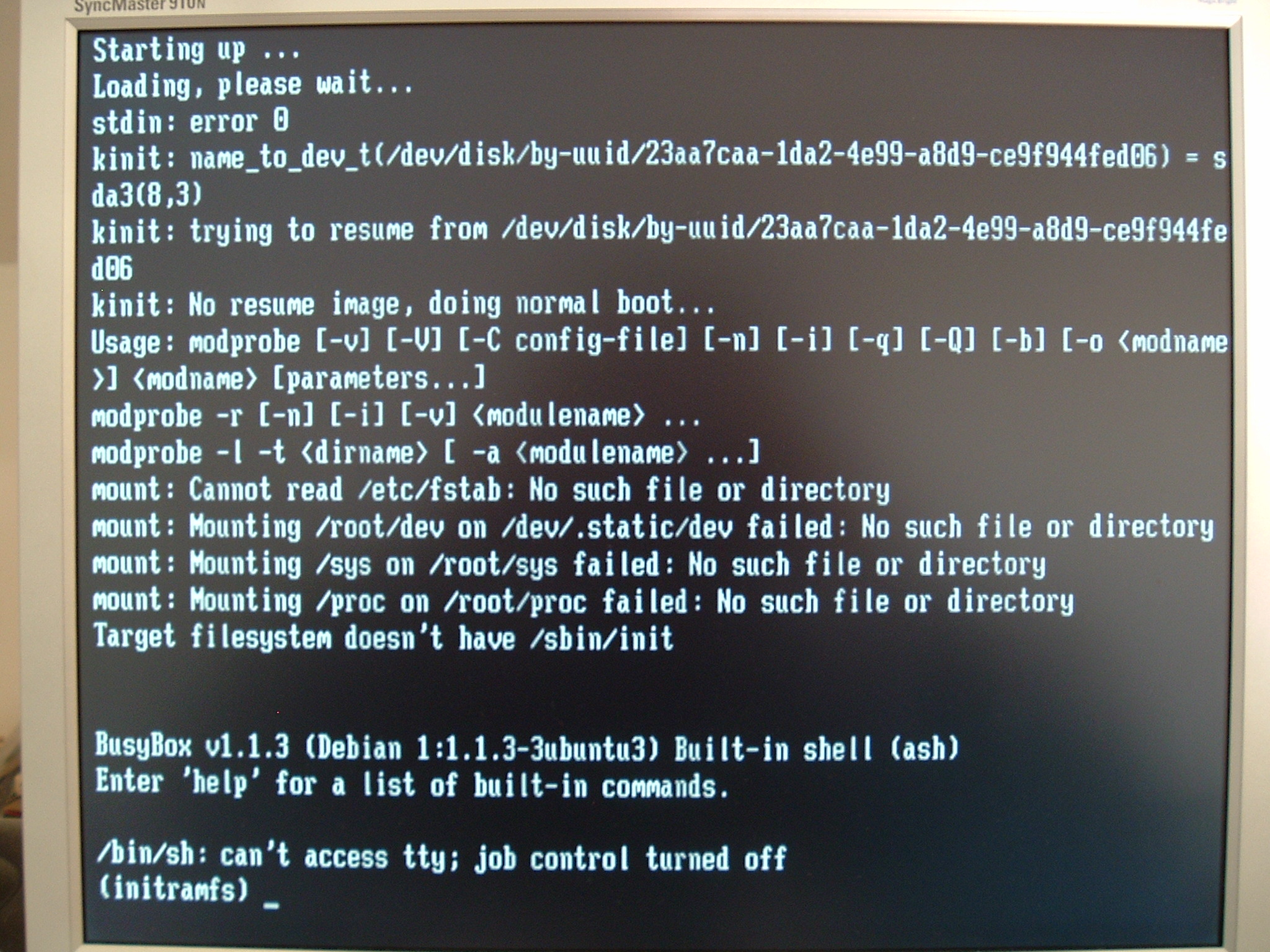
EVERY time I boot, mdadm complains that it can't build my arrays. It dumps me in the busybox shell where I discover that all /dev/hda* and /dev/hdc* devices are missing. I ran across a suggestion here: http://
Other than just to post a "me too", I thought my comments might help give a possible temporary workaround, as well as document the fact this isn't just a SATA problem.
============
I just updated to the latest packages as of approximately 4/5/07 00:50 EDT, and nothing has changed.
To fix it, I can follow the workaround here:
https:/
(Boot with break=premount
At the initramfs prompt:
udevd --verbose --suppress-syslog >/tmp/udev-output 2>&1 &
udevtrigger
)
or here:
http://
(add 'sleep 10' after 'log_begin_msg "Mounting root file system..."' in usr/share/
Either will allow me to boot (the latter without manual intervention).
Related branches

{kind=link}
| Changed in mdadm: | |
| status: | Unconfirmed → Confirmed |
| Changed in initramfs-tools: | |
| status: | Unconfirmed → Confirmed |
{kind=link}
{kind=link}
{kind=link}
| Changed in mdadm: | |
| assignee: | nobody → keybuk |
| Changed in initramfs-tools: | |
| assignee: | nobody → keybuk |
| status: | Confirmed → In Progress |
{kind=link}
Here are the versions of the related packages currently installed on my system:
dmsetup 1.02.08-1ubuntu10
libdevmapper1.02 1.02.08-1ubuntu10
libvolume-id0 108-0ubuntu3
lvm-common <none>
lvm2 <none>
mdadm 2.5.6-7ubuntu5
udev 108-0ubuntu3
volumeid 108-0ubuntu3