subiquity crashes upon reusing failed to assemble raid member partition
Bug #1835091 reported by
Dimitri John Ledkov
This bug affects 1 person
| Affects | Status | Importance | Assigned to | Milestone | |
|---|---|---|---|---|---|
| curtin |
Fix Released
|
High
|
Unassigned | ||
| subiquity |
Fix Released
|
Medium
|
Unassigned | ||
| probert (Ubuntu) |
Fix Released
|
High
|
Unassigned | ||
Bug Description
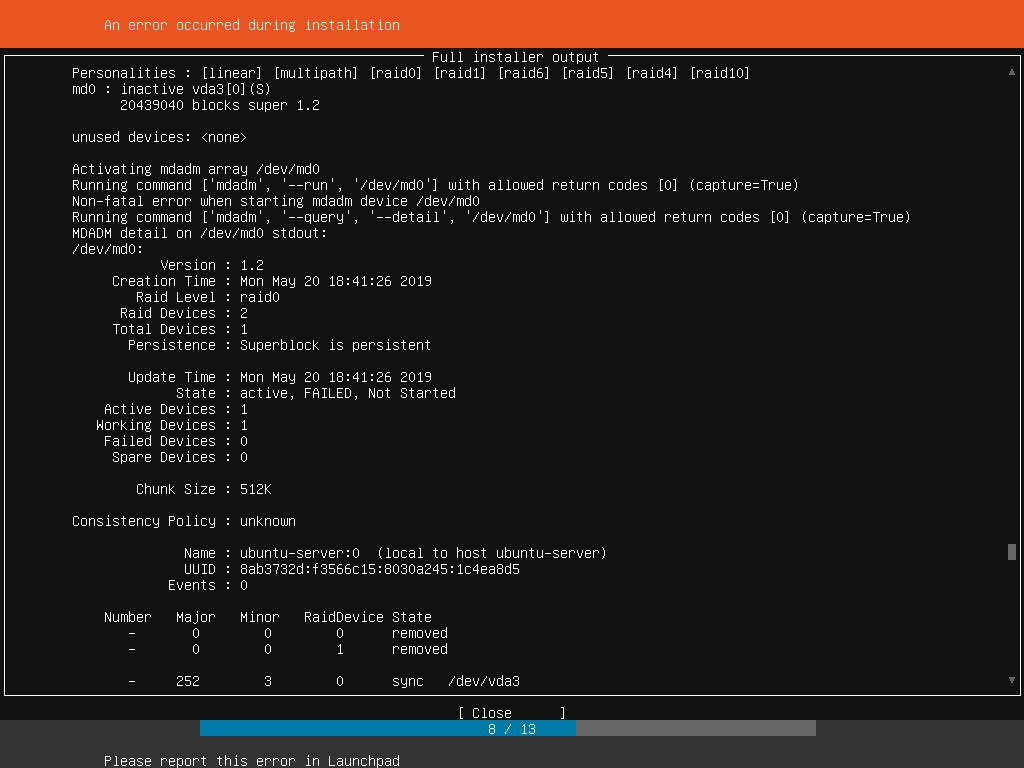
subiquity crashes upon reusing failed to assemble raid member partition
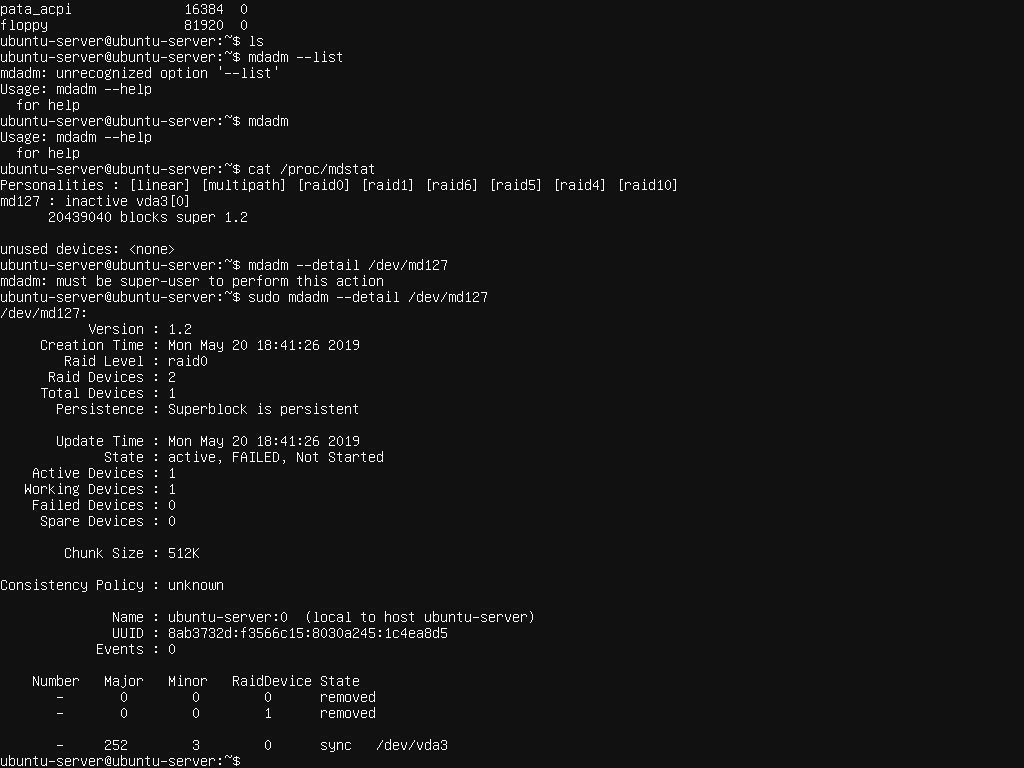
so following up from the previous bug #1835087 I removed the second drive, such that i only had:
- grub-partition
- /boot ext4 partition
- just half of a raid0 member as a partition
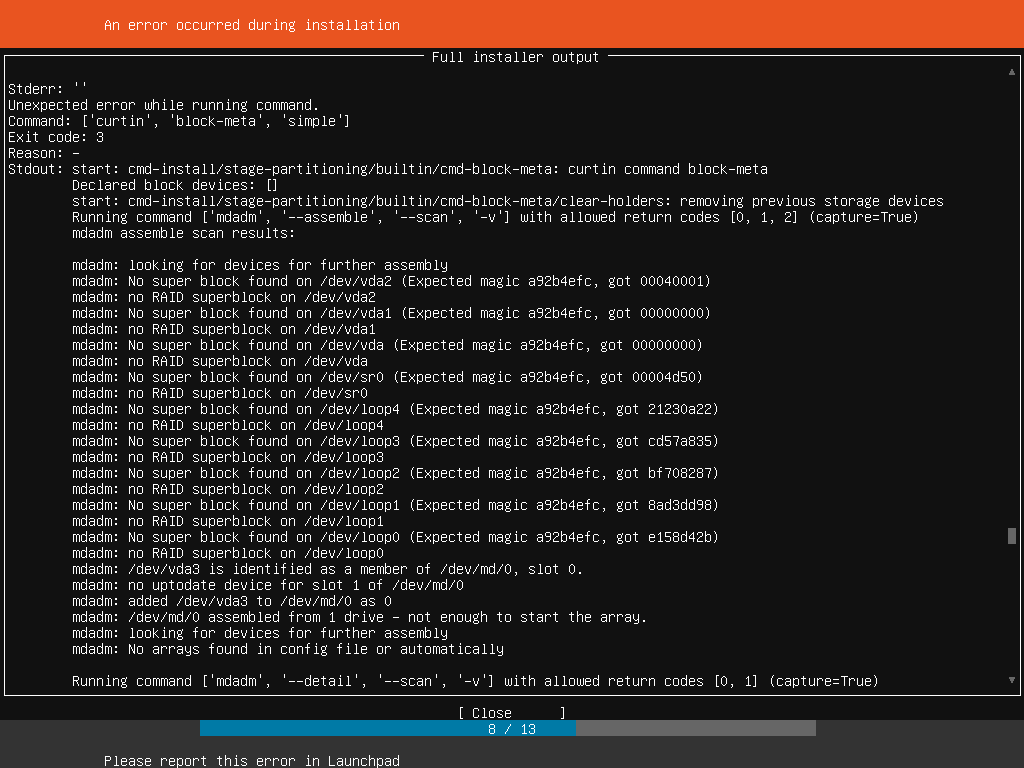
that raid0 member, got added to the failed-to-start md127 raid0. But otherwise failed to assemble into a functioning raid.
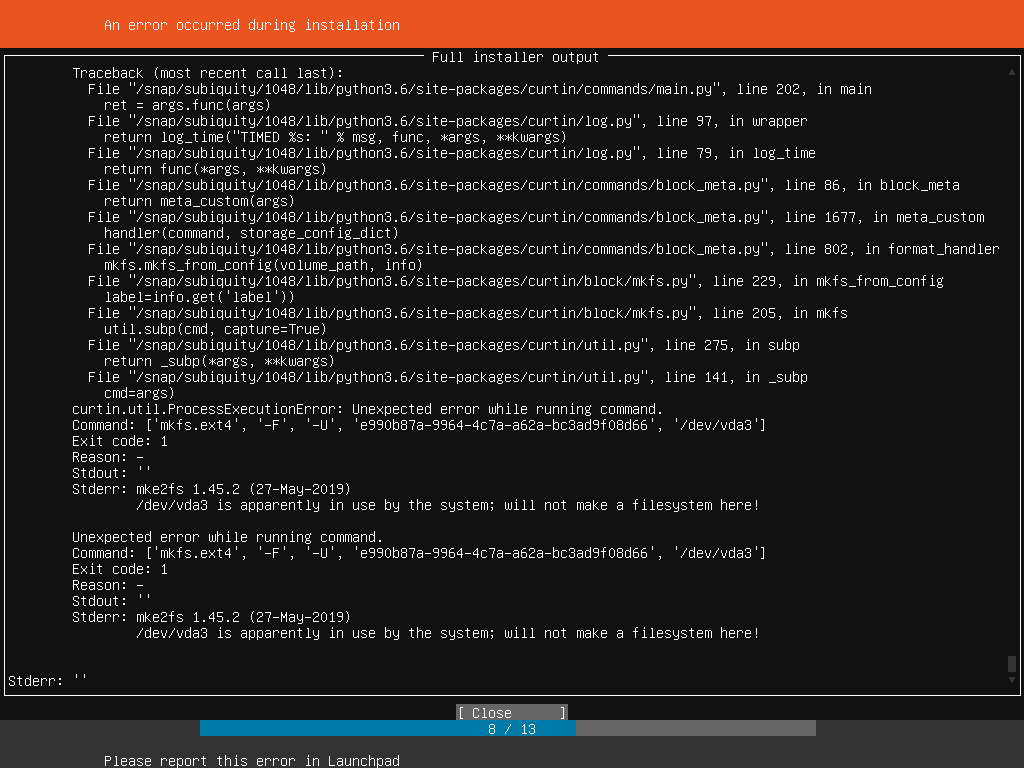
Upon reusing that partition for ext4 /, mke2fs failed, as vda3 is "in use" by mdadm.
Somehow, partial raid needs to be represented. Or we should try harder - remove device from raid, wipe raid signatures, then mke2fs.
Attaching screenshots.
Related branches
~raharper/curtin:mwhudson-vmtest-reuse-half-a-raid
- Server Team CI bot: Approve (continuous-integration)
- Dan Watkins (community): Approve
-
Diff: 345 lines (+250/-19)6 files modifiedcurtin/block/clear_holders.py (+20/-5)
curtin/commands/block_meta.py (+16/-12)
examples/tests/reuse-raid-member-partition.yaml (+73/-0)
examples/tests/reuse-raid-member-wipe.yaml (+71/-0)
tests/unittests/test_clear_holders.py (+8/-2)
tests/vmtests/test_reuse_raid_member.py (+62/-0)

{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Changed in subiquity: | |
| status: | New → Triaged |
| importance: | Undecided → Medium |
| tags: | added: reuse |
| tags: | added: id-5d40f920ea9865754db787bb |
| Changed in subiquity: | |
| status: | Triaged → Fix Released |
| Changed in probert (Ubuntu): | |
| status: | Triaged → Fix Released |
To post a comment you must log in.
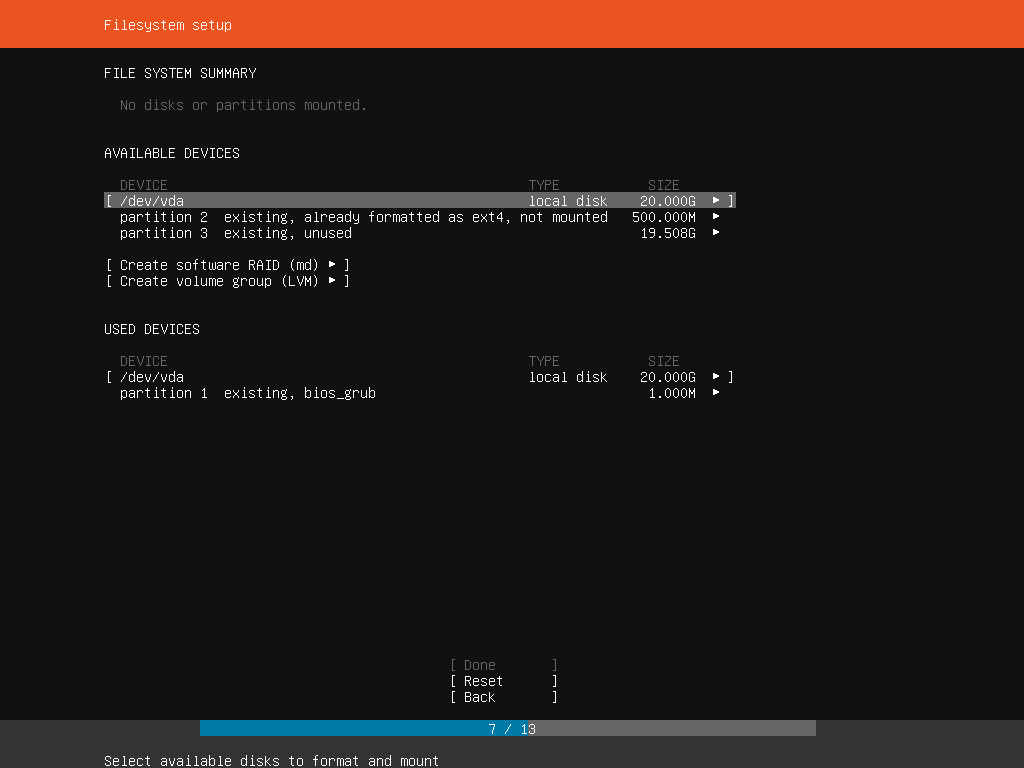
The partition marked unused, is actually in fact used by an active md127 that failed to start.