lshw 100%CPU usage every minute
| Affects | Status | Importance | Assigned to | Milestone | |
|---|---|---|---|---|---|
| Mirantis OpenStack |
Confirmed
|
High
|
Stanislav Kolenkin | ||
| 8.0.x |
Confirmed
|
High
|
Stanislav Kolenkin | ||
| 9.x |
Confirmed
|
High
|
Stanislav Kolenkin | ||
Bug Description
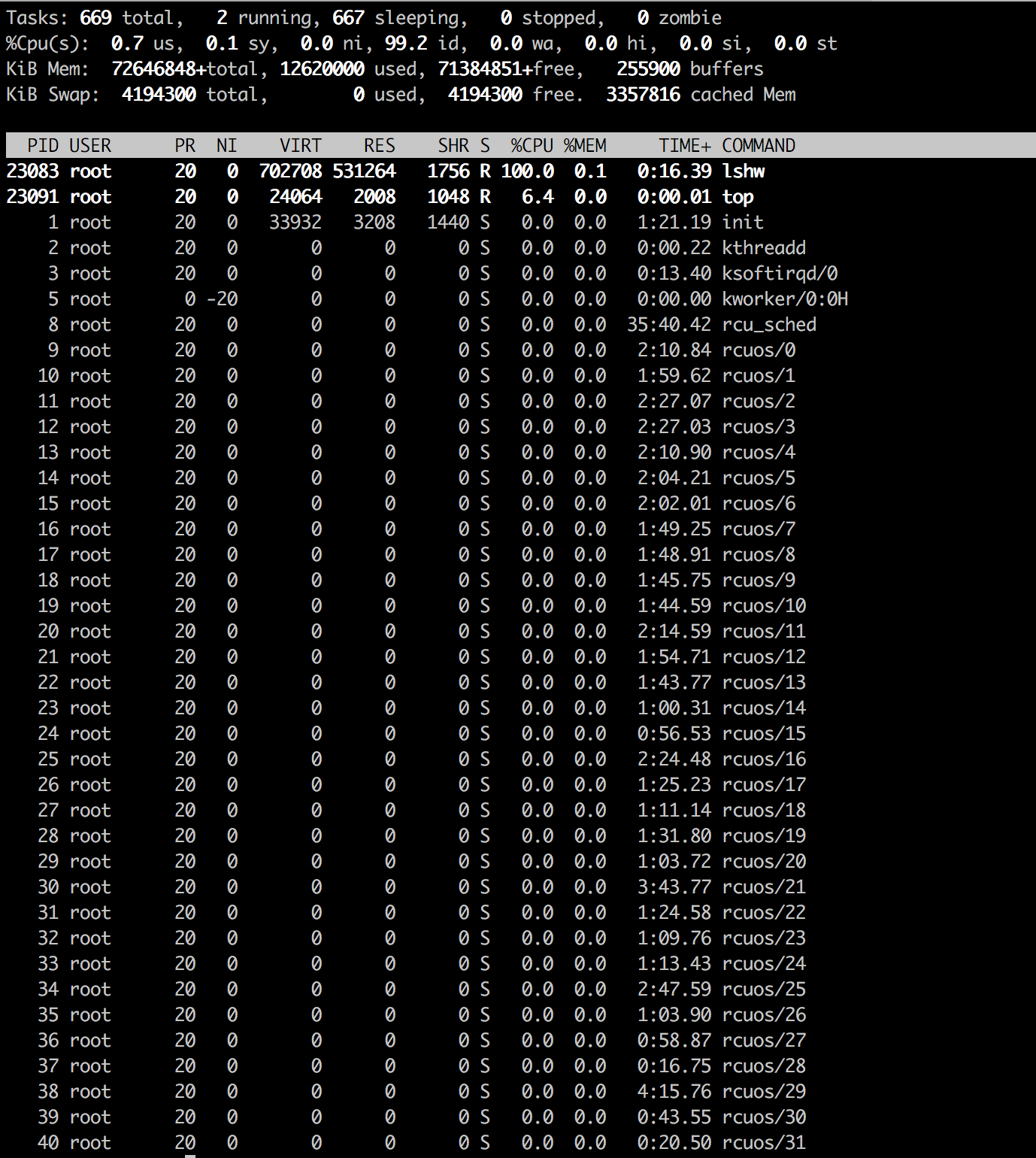
I have found that lshw process is started every minute and uses 100% CPU on any cloud-related node.
date && ps axuwww |grep lshw
Wed Aug 17 09:54:07 AST 2016
root 25790 111 0.0 61924 41372 ? R 09:54 0:01 /usr/bin/lshw -json
root 25794 0.0 0.0 10432 928 pts/8 S+ 09:54 0:00 grep --color=auto lshw
date && ps axuwww |grep lshw
Wed Aug 17 09:54:26 AST 2016
root 25819 0.0 0.0 10432 924 pts/8 S+ 09:54 0:00 grep --color=auto lshw
date && ps axuwww |grep lshw
Wed Aug 17 09:55:27 AST 2016
root 26283 32.0 0.0 23084 8792 ? R 09:55 0:00 /usr/bin/lshw -json
root 26287 0.0 0.0 10432 928 pts/8 S+ 09:55 0:00 grep --color=auto lshw
lshw --version
Hardware Lister (lshw) - B.02.16
Screenshot in the attachment.

{kind=link}
| description: | updated |
| tags: | added: customer-found |
| tags: | added: support |
Stanislav, please add more details on the topic. What is the impact? How does it affect workloads? Are there any failures?