Composing a VM in MAAS with exactly 2048 MB RAM causes the VM to kernel panic
| Affects | Status | Importance | Assigned to | Milestone | |
|---|---|---|---|---|---|
| MAAS |
Invalid
|
Undecided
|
Unassigned | ||
| linux (Ubuntu) |
Confirmed
|
Undecided
|
Unassigned | ||
| qemu (Ubuntu) |
Incomplete
|
Undecided
|
Unassigned | ||
Bug Description
Using latest MAAS master, I'm unable to compose a VM over the UI successfully when composed with 2048 MB of RAM. By that I mean that the VM is created, but it fails with a kernel panic.
So far this only occurred in MAAS environments and often went away with e.g. the next daily images. Therefore to reproduce and finally debug/fix this issue we'd need data from anyone being affected. This list will grow as we identify more that is needed.
If you are affected, please attach to the bug
- the kernel used to boot the guest
- the initrd used to boot the guest
- libvirt guest XML used to define the guest
- PXE config provided to the guest
- the cloud image used to start the guest (That will likely not fit as bug
attachment, consider storing it somewhere and contact us)
TODO: The Maas Team will outline how to get all these artifacts.
TODO: add reference to the comment outlining this (once added)

| Andres Rodriguez (andreserl) wrote : Re: [2.5, UI] Composing a VM over the UI is broken - VM has kernel panic | #1 |
{kind=link}
| summary: |
- [2.5, UI] Composing a VM over the UI is broken + [2.5, UI] Composing a VM over the UI is broken - VM has kernel panic |
| Changed in maas: | |
| milestone: | none → 2.5.0rc1 |
| importance: | Undecided → Critical |
| status: | New → Triaged |
| tags: | added: ui |
| Anthony Dillon (ya-bo-ng) wrote : | #2 |
| Mike Pontillo (mpontillo) wrote : | #3 |
I can't reproduce this crash. Does the kernel panic happen at commissioning time or later?
Can you attach the output of `virsh dumpxml <vm-name>` for the both the working VM composed over the API, and the non-working VM composed with the UI?
| Changed in maas: | |
| status: | Triaged → Incomplete |
| Mike Pontillo (mpontillo) wrote : Re: [2.5] Composing a VM with 2048 MB RAM causes kernel panic | #4 |
Adding the linux package; we should narrow down the issue to see if it's in kernel space or user space.
| summary: |
- [2.5, UI] Composing a VM over the UI is broken - VM has kernel panic + [2.5] Composing a VM with 2048 MB RAM causes kernel panic |
| Changed in maas: | |
| status: | Incomplete → Invalid |
| Changed in linux (Ubuntu): | |
| status: | New → Incomplete |
| Mike Pontillo (mpontillo) wrote : Re: [2.5] Composing a VM with 2048 MB RAM causes kernel panic | #6 |
To be clear, the kernel panic is seen when a VM is composed in MAAS with exactly 2048 MB of RAM. Composing with 2047 or 2049 MB RAM results in a working VM.
| Mike Pontillo (mpontillo) wrote : | #7 |
We can't run apport-collect since the machine doesn't boot, but this was seen with a non-tainted 4.15.0.36-generic kernel in my environment.
| Changed in linux (Ubuntu): | |
| status: | Incomplete → New |
| summary: |
- [2.5] Composing a VM with 2048 MB RAM causes kernel panic + Composing a VM in MAAS with exactly 2048 MB RAM causes kernel panic |
| tags: | removed: ui |
| summary: |
- Composing a VM in MAAS with exactly 2048 MB RAM causes kernel panic + Composing a VM in MAAS with exactly 2048 MB RAM causes the VM to kernel + panic |
| Ryan Harper (raharper) wrote : | #8 |
Can you attach the guest xml and host kernel/qemu/libvirt packages?
| Changed in linux (Ubuntu): | |
| status: | New → Incomplete |
| Mike Pontillo (mpontillo) wrote : | #10 |
Here's an example of working XML (with 2047 MB RAM) that MAAS generated:
https:/
And here's an example of non-working XML (with 2048 MB RAM) that MAAS generated:
| Changed in linux (Ubuntu): | |
| status: | Incomplete → Confirmed |
| Mike Pontillo (mpontillo) wrote : | #11 |
Here's the version information.
libvirt-bin:
Installed: 4.0.0-1ubuntu8.5
Candidate: 4.0.0-1ubuntu8.5
Version table:
*** 4.0.0-1ubuntu8.5 500
500 http://
100 /var/lib/
4.
500 http://
4.0.0-1ubuntu8 500
500 http://
qemu-kvm:
Installed: 1:2.11+
Candidate: 1:2.11+
Version table:
*** 1:2.11+
500 http://
100 /var/lib/
1:
500 http://
1:
500 http://
qemu-system-x86:
Installed: 1:2.11+
Candidate: 1:2.11+
Version table:
*** 1:2.11+
500 http://
100 /var/lib/
1:
500 http://
1:
500 http://
linux-image-
Installed: 4.15.0-34.37
Candidate: 4.15.0-34.37
Version table:
*** 4.15.0-34.37 500
500 http://
500 http://
100 /var/lib/
4.
500 http://
| Ryan Harper (raharper) wrote : | #12 |
And /var/log/
| Mike Pontillo (mpontillo) wrote : | #13 |
Here's the log from the failing VM. Doesn't look too unusual to me...
| description: | updated |
| Ryan Harper (raharper) wrote : | #14 |
The backing image:
/var/lib/
What boot image is that? Can I get a copy of that from maas-images? or how is it created?
On the node with the vm that fails, can you:
virsh start <vm-name> --console
Assuming it's a normal ubuntu image which has normal console= settings, it should dump the boot console to the terminal so we can capture the full boot to panic.
| Ryan Harper (raharper) wrote : | #15 |
I'm unable to recreate with a daily bionic cloud-image on a bionic host with the same versions.
% sudo apt install uvtool libvirt
% uvt-simplestrea
% uvt-kvm create --memory 2048 --cpu 1 --disk 10 rharper-b1 label=daily release=bionic
% virsh dumpxml rharper-b1 | grep Mem
<currentMemory unit='KiB'
| Mike Pontillo (mpontillo) wrote : | #16 |
It's an empty image - MAAS PXE boots the VM.
Could you give it a try with MAAS? I can help you with the setup if needed - just ping me on IRC.
| Mike Pontillo (mpontillo) wrote : | #17 |
Here's a full console log from the failure.
| Christian Ehrhardt (paelzer) wrote : | #18 |
As Ryan I can not reproduce locally - hrm.
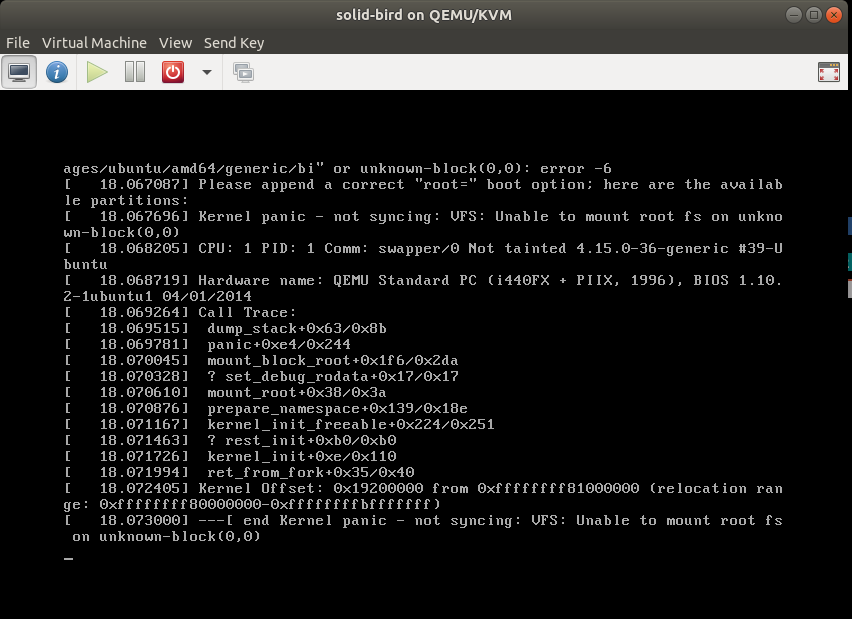
The crash in your log is the root-fs mount.
[ 22.524541] VFS: Cannot open root device "squash:http://
[ 22.575588] Please append a correct "root=" boot option; here are the available partitions:
[ 22.583909] Kernel panic - not syncing: VFS: Unable to mount root fs on unknown-block(0,0)
Also we have to stick to exactly your values (one of the repros had a slightly different value)
<memory unit='KiB'
<currentMemory unit='KiB'
I tried with the exact numbers above but "normal" cloud image boot is still ok.
I wonder if the kernel has an off by one error e.g. aligning the squash at the lowest 2G but with just this amount of memory choosing a place it would not fit.
We'd need to set up a local http and serve squashfs, to boot into that.
With some luck we can reproduce there and then eliminate libvirt and maas out of the equation.
Repro:
- I started off as Ryan did with a Cloud Image test via UVTool.
- Next I extracted the kernel+initrd from the guest to provide those from the host (as you do via PXE)
- installed nginx
- made initrd available on /var/www/
- made kernel available on /var/www/
- The address of the Host on the libvirt net is 192.168.122.1, verify the guest can http from there
- get matching squash (see below for details)
- get an empty qemu disk via qemu-img like the type raw that maas uses
sudo qemu-img create -f raw /var/lib/
- With that, modify the guest to use these kernel/
XML of the guest: http://
I have a dependency issue for my repro, that is IP being configured in /scripts/
http://
I can even fetch the squashfs from the initramfs, wouldn't you be affected by the same ordering issue? I need to find how you usually get around that to continue the repro that hopefully eventually helps to focus on the root cause.
I experimented a bit more and asked around on IRC.
But so far I can't get past the ordering issue that IP is initialized to late and due to that squash is failing.
-- Appendix --
Get Squash:
To continue I'd need the current squashfs instead of the disk image.
My uvtool spawned this for me:
$ uvt-simplestrea
release=bionic arch=amd64 label=daily (20181012)
So lets get the mathcing suqash URL and fetch that.
$ sstream-query --output-
http://
$ sudo wget -O /var/www/
Note: That setup is available on server horsea
| Christian Ehrhardt (paelzer) wrote : | #19 |
After DHCP is up it works just fine.
(initramfs) wget http://
Connecting to 192.168.122.1:80 (192.168.122.1:80)
squashfs 100% |******
(initramfs) mount -t squashfs squashfs /root
(initramfs) mount
rootfs on / type rootfs (rw)
sysfs on /sys type sysfs (rw,nosuid,
proc on /proc type proc (rw,nosuid,
udev on /dev type devtmpfs (rw,nosuid,
devpts on /dev/pts type devpts (rw,nosuid,
tmpfs on /run type tmpfs (rw,nosuid,
tmpfs-root on /media/root-rw type tmpfs (rw,relatime)
copymods on /root/lib/modules type tmpfs (rw,relatime)
/dev/loop0 on /root type squashfs (ro,relatime)
So if anyone has a good hint how to get out of the ip/squash-root ordering issue let me know.
That would - as mentioned - help to most likely exclude maas and libvirt from the suspects to be able to debug further.
| Christian Ehrhardt (paelzer) wrote : | #20 |
Working on this I found by accident that I actually can reproduce:
VFS: Cannot open root device "squash:http://
But the way I got there lets assume some more potential reasons.
I got there by breaking my initramfs :-)
After realizing this I removed the initramfs from the guest definition and got to just the same error.
The reason is that without initramfs the kernel is responsible to handle root= and it has no idea of squashfs.
With that knowledge I re-checked your log at: https:/
It also has no entry like:
Loading, please wait...
starting version 237
Which you'd see if systemd in the initrd would take over.
So your bad case also fails to load the initramfs!
That said, why could that be special for just this memory size?
Theories related to the guest size impacting this:
- initrd is placed explicit in PXE config now conflicting with kernel allocations
- initrd is misplaced/misread by PXE code in qemu
@Mike - I'd want to know your exact PXE config
@Mike - It would be great to attach your kernel+
Hopefully we can reproduce by providing kernel+initrd via PXE and varying the guest size.
| Changed in qemu (Ubuntu): | |
| status: | New → Incomplete |
| Ryan Harper (raharper) wrote : | #21 |
[ 0.943808] Unpacking initramfs...
[ 20.690329] Initramfs unpacking failed: junk in compressed archive
[ 20.703673] Freeing initrd memory: 56612K
Looks like the initrd was compromised, possibly a networking hiccup? Can you confirm the checksums on the source and attempt to download the URL ?
I can't see why the size of the VMs ram makes a difference though. But I don't think this is a qemu issue any more.
| Christian Ehrhardt (paelzer) wrote : | #22 |
Since it is reproducible maybe not a networking hiccup.
But maybe a hiccup of the PXE setup (thats why I asked for it).
Or a hiccup of the quite complex shim loading if signed kernels are used.
@Mike - in addition to my questions above could you use a non signed/shim load pattern as well to check if that might be part of the reason?
| Changed in maas: | |
| milestone: | 2.5.0rc1 → none |
| Mike Pontillo (mpontillo) wrote : | #23 |
I agree that this doesn't look like a QEMU issue, and I agree that it doesn't look like a [general] networking hiccup.
@paelzer, the easiest way to get the exact configs you need would be to install MAAS similar to how I've described on our discourse forum[1]. The PXE config will be /similar/ to this[2] (copied/pasted from /usr/lib/
[1]: MAAS setup instructions
https:/
[2]: PXE config
https:/
| Changed in qemu (Ubuntu): | |
| status: | Incomplete → Invalid |
| Ryan Harper (raharper) wrote : | #24 |
Does this fail with other releases? like trusty? I was wondering if initrd size plays a factor here:
precise/hwe-t: 25M
trusty/hwe-x: 35M
xenial/ga: 39M
xenial/hwe: 53M
xenial/edge: 53M
bionic/ga: 55M
cosmic/ga: 57M
That might be faster for you to test than for us to replicate setup.
| Mike Pontillo (mpontillo) wrote : | #25 |
Good idea @rharper. It's easy for MAAS to attempt commissioning on Xenial or Bionic, so I gave Xenial a try. It works fine![1]
[1]: Console log -
https:/
| Mike Pontillo (mpontillo) wrote : | #26 |
I just tried Xenial with the HWE kernel - same result (success). FYI.
| Mike Pontillo (mpontillo) wrote : | #27 |
... it's interesting that [practically?] the same kernel version that fails consistently with Bionic works just fine with Xenial.
| Christian Ehrhardt (paelzer) wrote : | #28 |
I must admit, compared to you just sharing your kernel/
Waiting for a sync here, setting up users there, sorting out how to make us provide PXE and such on the "maas" virtual network, ... - it just isn't one click and ready.
Initially things worked other than the unexpected "wait for image sync".
I've got a Pod registered and working to get to libvirt data.
But compose blocks at:
"Pod unable to compose machine: Please add a 'default' or 'maas' network whose bridge is on a MAAS DHCP enabled VLAN. Ensure that libvirt DHCP is not enabled."
Well that is clear, but a link where/how to get MAAS dhcp/pxe to own that vlan would be nice.
Maybe something small and easy for you that would help to be added.
When I go to subnets to create one (to have maas own it) for 172.16.99.0/24 that I created following your link it tells me the subnet already exists "Error: Subnet with this Cidr already exists." - but it isn't in the subnet overview so I can't enable DHCP/PXE on it :-/
My overview suffers a bit from the links you had adding sample-data, I cleaned up a lot of demo-BS and can now see more clearly. I'd want to add a subnet to my fabric that I called "libvirt-maas" being the virbr1 "maas" definition by libvirt.
Afterwards I still get "Error: Subnet with this Cidr already exists."
Well it might conflict with the "172.16.99.1" set up by.
Lets try to set up another subnet, that worked.
Also added a range of IPs in the hope that this would switch DHCP on, but it didn't
So on the subnet's own page "managed allocation" is enabled.
But when clicking on the top menu subnets the column for DHCP in the table is "disabled"
Anyway, lets try to compose something ...
No, still blocked at "Pod unable to compose machine: Please add a 'default' or 'maas' network whose bridge is on a MAAS DHCP enabled VLAN. Ensure that libvirt DHCP is not enabled."
That exceeds what I can find on [2] for DHCP enabling, but still refuses me.
Since reusing maas DHCP/PXE setup is exactly what I wanted to debug for/with you I'm stuck, lost time and we are not a bit further on this bug here :-/
Now trying to squeeze your PXE config into tftp/libvirt manually without MAAS - lets see if I can reproduce via that.
[1]: https:/
[2]: https:/
| Christian Ehrhardt (paelzer) wrote : | #29 |
I didn't let me calm down - I found in the doc [1] that the switch might be on the VLAN and not the subnet (Hrm why?)
It was on the vlan
http://
Not on the subnet
http://
There I found the "provide dhcp" entry \o/
That unlocked some understanding of what the range allocations would be like on vland/subnets.
I reconfigured the range allocation and hit the "provide DHCP" switch.
Looking back all is reasonable, just some stumbling on my first maas setup from scratch :-/
Must be funny for you seeing me struggle doing so :-)
With that in place I created three pods with 2047/2048/2049 MB memory.
ubuntu@
<memory unit='KiB'
<currentMemory unit='KiB'
ubuntu@
<memory unit='KiB'
<currentMemory unit='KiB'
ubuntu@
<memory unit='KiB'
<currentMemory unit='KiB'
They all went into the commissioning phase, but who would be surprised got stuck somewhere in there :-/
OTOH the bug says "composing crashes" so we might be at the right place, lets take a look at these three guests.
[1]: https:/
| Christian Ehrhardt (paelzer) wrote : | #30 |
I didn't see any guests crashing, instead they all just hang finding nothing to boot.
I reduced this to just qemu (for debugging later on) but it reliably breaks finding nothing from PXE.
Guest Console:
iPXE (PCI 00:03.0) starting execution...ok
iPXE initialising devices...ok
iPXE 1.0.0+git-
-- http://
Features: DNS HTTP HTTPS iSCSI NFS TFTP AoE ELF MBOOT PXE bzImage Menu PXEXT
net0: 52:54:00:3b:72:0a using virtio-net on 0000:00:03.0 (open)
[Link:up, TX:0 TXE:0 RX:0 RXE:0]
Configuring (net0 52:54:00:
succeeded (http://
No more network devices
Corresponding command to start qemu:
#!/bin/bash
/usr/bin/
-chardev socket,
-mon chardev=
-chardev stdio,mux=
-device isa-serial,
-drive file=/var/
-device virtio-
\
-boot order=n,strict=on \
\
-net bridge,
This is the mac that is also in the libvirt XML.
The bridge is the one served by MAAS and it seems there is just no PXE responding to it.
Since the two other guests as started by maas+libvirt hang just the same way it most likely is a general MAAS setup issue.
Please help me to get MAAS to reply the way you would usually expect it, to then be able to go on with debugging.
| Christian Ehrhardt (paelzer) wrote : | #31 |
Taking the x86 pxelinux.0 from /usr/lib/
With that instead of pushing things from libvirt via kernel/initrd tags I now provide it via PXE similar to your config.
TL;DR
- tftp serves: lpxelinux.0 + pxe modules + PXEconfig
- nginx serves: kernel/
- qemu started directly without libvirt
Still gets the inintial kernel booting fine and then failing to mount the squash:
mount: mounting squash:http://
I can from the initramfs mount it:
(initramfs) wget http://
Connecting to 192.168.122.1:80 (192.168.122.1:80)
squashfs 100% |******
(initramfs) mount -t squashfs squashfs /root/
It is mounted just fine:
/dev/loop0 on /root type squashfs (ro,relatime)
It is possible that I'm back at the same ordering issue that I had of the IP coming up too late to mount the squashfs, but later works fine.
I mounted it with 2047/2048/2049 mb gusts without a problem.
Despite all work on this I'd still need a better reproducer :-/
I might take a look at rebuilding a more verbose initramfs for that after lunch.
--- config details ---
$ find /srv/tftp/
/srv/tftp/
/srv/tftp/squashfs
/srv/tftp/
/srv/tftp/
/srv/tftp/
/srv/tftp/
/srv/tftp/
/srv/tftp/
Kernel/
# modified to get scrollable direct console (but no iPXE VGA output)
#!/bin/bash
/usr/bin/
\
-nographic -serial mon:stdio \
\
-drive file=/var/
-device virtio-
\
-boot order=n,strict=on \
\
-net bridge,
# For access to the iPXE / lpxelinux graphical output
#-curses \
#-chardev stdio,mux=
#-serial chardev:charserial0 \
#-mon chardev=
# For access to a scrollable direct console and monitor
# -nographic -serial mon:stdio
$ cat /srv/tftp/
DEFAULT execute
LABEL execute
SAY Booting under MY direction...
KERNEL http://
INITRD http://
APPEND console=ttyS0 nomodeset ro root=squash:http://
| Christian Ehrhardt (paelzer) wrote : | #32 |
There actually is no need to debug further on my non-maas PXE setup.
As identified before - your setup breaks due to
[ 20.690329] Initramfs unpacking failed: junk in compressed archive
Everything else is a follow on issue, with eventually:
[ 22.524541] VFS: Cannot open root device "squash:http://
But since my setup as outlined in comment #31 PXE-boots the kernel+initramfs just fine I don't have to debug the rest.
I already passed the point where it breaks for you.
Can you use the above hints to get your breaking setup to also one-by-one remove components.
I'd assume that removing libvirt makes no difference to your case.
But you could maybe end up with:
- PXE-served by MAAS = bad
- PXE serverd by tftpd = good
Or anything like it.
So please follow the hints above (or get in touch if you need me to do so) and convert your setup until you can identify which component makes the decision for good/bad case.
Also still I'd be open to get your kernel/
| Changed in linux (Ubuntu): | |
| status: | Confirmed → Incomplete |
| Changed in maas: | |
| status: | Invalid → Incomplete |
| Changed in qemu (Ubuntu): | |
| status: | Invalid → Incomplete |
| Mike Pontillo (mpontillo) wrote : | #33 |
After triaging this again on a call with Andres (who originally reported this) this morning, we determined that this issue is no longer reproducible with MAAS. The only way for me to explain it at this point was that there was something wrong with the daily image MAAS was using last week, and a subsequent update fixed it. (It looks like the images were updated yesterday.)
Sorting my /var/lib/
https:/
@paelzer, if you'd like to test with any of those images, I've made copies. (Not sure where to put them, though - I wonder if your MAAS synced them as well?)
Still very weird that it worked in all cases we tested except when we allocated 2048 MB RAM.
I'd like to thank Ryan and Christian for their efforts on this "heisenbug". We should think about how to better handle issues like this, so that it's easier to peel back the layers and get to a point where everyone's environment can be consistent without this much effort. And we'll reopen this if it returns.
| Mike Pontillo (mpontillo) wrote : | #34 |
Looking again at the date stamps, I don't see any squashfs filesystems older than October 15th. The kernels are all from ~September 25th. So I feel like this must have been an interaction between the kernel September 25th and whatever the previous squashfs was.
| Christian Ehrhardt (paelzer) wrote : | #35 |
Hi,
thanks for your feedback.
We are at least much closer to what happened and thereby should be faster if it reoccurs.
I don't think it is an interaction of the Kernel and Squashfs as we found that already initramfs unpack was broken. That is before Squash comes into play.
I'll keep my test setup until I need to re-deploy the host, which usually is about every 1-2 weeks.
If you ever find old kernel/initrd combinations or any new one to trigger it again - please share them via e.g. internal private fileshare - I sent you some details on IRC.
Lets see if it comes up again.
| Vladimir Grevtsev (vlgrevtsev) wrote : | #36 |
Reproduced today on MAAS 2.5 / latest Bionic.
qemu/maas versions: https:/
good vm dump: http://
good vm log: http://
good vm serial output: http://
bad vm dump: http://
bad vm log: http://
bad vm serial output: http://
| Changed in maas: | |
| status: | Incomplete → Confirmed |
| Changed in linux (Ubuntu): | |
| status: | Incomplete → New |
| Changed in qemu (Ubuntu): | |
| status: | Incomplete → New |
| tags: | added: cpe-onsite |
| tags: | added: field-medium |
| Changed in maas: | |
| status: | Confirmed → Incomplete |
| Vladimir Grevtsev (vlgrevtsev) wrote : | #37 |
Subscribing field-medium as workaround (e.g not to use 2048mb ram VMs) exists, but solution still need to be found.
Also, before yesterday (e.g on libvirt 1:2.11+
| Andres Rodriguez (andreserl) wrote : | #38 |
Setting this back to incomplete for MAAS because there is not enough information to determine this is a MAAS Bug. That said, given that this work with any VM other than one with 2048 of RAM, the issue may appear to be the kernel or libvirt.
| Launchpad Janitor (janitor) wrote : | #39 |
Status changed to 'Confirmed' because the bug affects multiple users.
| Changed in linux (Ubuntu): | |
| status: | New → Confirmed |
| Changed in qemu (Ubuntu): | |
| status: | New → Confirmed |
| Christian Ehrhardt (paelzer) wrote : | #41 |
Again it seems to break on initramfs being bad:
[ 0.840153] Initramfs unpacking failed: no cpio magic
@Mike/Andres - can you reproduce it on your own test env this time?
@Vladimir - could you internally share exactly your kernel and initrd that is tried to be booted in this case? Last time we wondered if the issue could be "in there" so it would be great to have exactly those that fail for you shared to try reproducing on them.
| Ryan Harper (raharper) wrote : Re: [Bug 1797581] Re: Composing a VM in MAAS with exactly 2048 MB RAM causes the VM to kernel panic | #42 |
One other oddity in the xml is the cgroup construction in the "bad" case.
<resource>
<partition>
</resource>
>
>
> To manage notifications about this bug go to:
> https:/
>
| Christian Ehrhardt (paelzer) wrote : | #43 |
@Ryan - the resource and other bits being different is because in the bad case the domain was up and in the good case down. That in itself is not a problem.
| Raphael Derosso Pereira (raphaelpereira) wrote : | #44 |
Reproduced today on MAAS 2.5 latest bionic
It is not reproduced if switch from ga-18.04 kernel to ga--18.
| Thiago Martins (martinx) wrote : | #45 |
I'm also facing this problem.
My workaround is to compose VMs using Virt-Manager, Firmware = UEFI for the VM and then, refreshing the MaaS Pod.
There is a need to install ovmf
sudo apt install ovmf
On MaaS Pod.
Then, no more Kernel Panic!
Details:
https:/
| Ryan Harper (raharper) wrote : | #46 |
@Thiago,
Can you attach your guest XML that's working successfully with 2048MB?
| Thiago Martins (martinx) wrote : | #47 |
- vunft-1.xml Edit (3.7 KiB, application/xml)
@Ryan,
The working XML file is attached here, with 2048 MB of RAM.
NOTE: This XML was created using Virt-Manager, then, MaaS took it over after being "refreshed".
Cheers!
Thiago
| Ryan Harper (raharper) wrote : | #48 |
On Mon, Jan 14, 2019 at 1:55 PM Thiago Martins <email address hidden>
wrote:
> @Ryan,
>
> The working XML file is attached here, with 2048 MB of RAM.
>
> NOTE: This XML was created using Virt-Manager, then, MaaS took it over
> after being "refreshed".
>
Thanks!
If you drop the <os> section (which is what tells libvirt to boot via UEFI)
does your VM still work?
<os>
<type arch="x86_64" machine=
<loader readonly="yes" type="pflash"
<nvram>
</os>
Note that MAAS boots UEFI images with grub2[1], not pxeboot/
so I think we can narrow down the
error to the non-uefi case which may help find the issue.
1.
http://
>
> Cheers!
> Thiago
>
> ** Attachment added: "vunft-1.xml"
>
> https:/
>
> --
> You received this bug notification because you are subscribed to qemu in
> Ubuntu.
> https:/
>
> Title:
> Composing a VM in MAAS with exactly 2048 MB RAM causes the VM to
> kernel panic
>
> To manage notifications about this bug go to:
> https:/
>
| Thiago Martins (martinx) wrote : | #49 |
Ryan,
If I remove the UEFI line (back to BIOS), the machine enters in Kernel Panic during the boot / commissioning.
That was actually, the very test that I executed in first place (add UEFI to see)! Then, I came with this UEFI workaround, which is even better for me.
Cheers!
Thiago
| Changed in maas: | |
| importance: | Critical → Undecided |
| Jason Hobbs (jason-hobbs) wrote : | #50 |
Bumped to field-high as we ran into this again in testing.
We have a workaround, but it's to not use 2G VM's, which is really silly and hard to remember when we go and add new deployments, especially because the failure mode is not obvious at all.
| Christian Ehrhardt (paelzer) wrote : | #51 |
Jason,
thanks for chiming in - so far this was non-reproducible every time we looked at it. We had plenty of approaches with the MAAS team to this and later on with Thiago, but still miss the right data to continue.
Last time I asked - I think it was still Mike - that I'd really like to get the full set of binaries involved, but then IIRC he couldn't reproduce it with the newer images/kernel of that day. Maybe we can use this issue hitting you now as a new chance to get what we need to continue debugging to reach a resolution.
@Jason - can I get from you the full set of elements used when you hit it?
That would be:
- which release are you on?
- which qemu/libvirt/
- can you share the XML that the guest is defined with
We have the above from different cases, but it might be important to know which ones exactly are active in your case, so better check them. Finally - and that was what was missing before so far:
- can you attach the set of binaries that are used which should be
- cloud-img
- kernel (as maas provides that directly to the guest in guest XML)
- initrd (as maas provides that directly to the guest in guest XML)
- describe your KVM Host server HW (so that we can test on something similar)
As an alternative - can you provide a login on such a host which has a breaking guest defined. There we could work together fetching the required data?
| Jason Hobbs (jason-hobbs) wrote : | #52 |
@Christian
- release: bionic
- seabios: 1.10.2-1ubuntu1
- qemu: 1:2.11+
- libvirt: 4.0.0-1ubuntu8.8
- ovmf - this is a uefi thing right? we're not using it.
- kernel 2019-03-
I don't have copies of the binaries from this run - it was from daily maas images:
2019-03-
I don't see anything in the logs to indicate an ID number for the kernel, initrd, or image coming there.
| Christian Ehrhardt (paelzer) wrote : | #53 |
Ok, thanks Jason.
That is great info, but about as much as we had so far :-/
Can you set your deployment up in a way that if that happens again you can collect these binaries?
If it right now still triggers if you (re)deploy a 2G guest use the chance to finally give us the bits that we will need to reach the next stage of debugging.
Lesson learned from before on this bug, it might already be gone by tomorrow, so I hope you have time and chance to get those xml+image+
| Dmitrii Shcherbakov (dmitriis) wrote : | #54 |
Just reproduced it on my env (where things used to work) after updating from MAAS 2.5.0~rc2 to 2.5.2.
https:/
[ 15.458594] VFS: Cannot open root device "squash:http://
tree /var/lib/
/var/lib/
# ...
├── current -> snapshot-
└── snapshot-
Which binaries do I need to have uploaded?
sha256sum /var/lib/
69ca457a119fe30
166853ad9342fdf
1e7841d7fca13ef
ii seabios 1.10.2-1ubuntu1 all Legacy BIOS implementation
ii ipxe-qemu 1.0.0+git-
ii qemu-kvm 1:2.11+
ii libvirt0:amd64 4.0.0-1ubuntu8.8 amd64 library for interfacing with different virtualization systems
| Dmitrii Shcherbakov (dmitriis) wrote : | #55 |
echo -n 'BOOT_IMAGE=http://
576
arch/x86/
#define COMMAND_LINE_SIZE 2048
#define PARAM_SIZE 4096 /* sizeof(struct boot_params) */
Doesn't look like we are any close to the kernel limits on parameters.
However, the root argument as printed in the panic message looks like a 64-byte string (last byte for null termination):
echo -n 'squash:http://
63
It looks like this is coming from the following code (strlcpy into a 64-byte array):
static char __initdata saved_root_
static int __init root_dev_setup(char *line)
{
strlcpy(
return 1;
}
__setup("root=", root_dev_setup);
And the overall code-path (judging by the md auto-detection log messages):
https:/
prepare_namespace ->
if (saved_
root_device_name = saved_root_name; // <---- (!) usage of a cut-down root param
if (!strncmp(
!
mount_
Does not look like we are hitting either EACCES or EINVAL and so we fall through to panic():
https:/
void __init mount_block_
// ...
for (p = fs_names; *p; p += strlen(p)+1) {
int err = do_mount_root(name, p, flags, root_mount_data);
switch (err) {
case 0:
goto out;
case -EACCES:
case -EINVAL:
continue;
}
/*
* Allow the user to distinguish between failed sys_open
* and bad superblock on root device.
* and give them a list of the available devices
*/
#ifdef CONFIG_BLOCK
__bdevname(
#endif
printk("VFS: Cannot open root device \"%s\" or %s: error %d\n",
root_
printk("Please append a correct \"root=\" boot option; here are the available partitions:\n");
printk_
#ifdef CONFIG_
printk(
"explicit textual name for \"root=\" boot option.\n");
#endif
panic("VFS: Unable to mount root fs on %s", b);
| Dmitrii Shcherbakov (dmitriis) wrote : | #56 |
- boot-initrd Edit (55.3 MiB, application/octet-stream)
The kernel code path mentioned in #55 is only executed if there is no "early userspace init" - in other words, if there is no /init on initrd:
/*
* check if there is an early userspace init. If yes, let it do all
* the work
*/
if (!ramdisk_
ramdisk_
if (sys_access((const char __user *) ramdisk_
ramdisk_
prepare_
}
However, I can see that the initrd used in my case contains the init script (so sys_access should be successful):
initrd=http://
lsinitramfs /var/lib/
init
If I increase the memory allocation from 2048 to 2049 MiB the machine starts to boot just fine.
Unsuccessful boot log (2048 MiB): https:/
Successful boot log (2049 MiB): https:/
Attached boot-initrd.
| Dmitrii Shcherbakov (dmitriis) wrote : | #57 |
I cannot reproduce the same with a xenial (GA kernel) image with 2048 MiB of RAM allocated to a VM.
So it seems to me that this is a kernel issue.
| Dmitrii Shcherbakov (dmitriis) wrote : | #58 |
Found something interesting.
Bionic + 2048 MiB of RAM (bad):
[ 1.520243] Unpacking initramfs...
[ 14.712821] Initramfs unpacking failed: broken padding
[ 14.723088] Freeing initrd memory: 56636K
Bionic + 2049 MiB of RAM (good):
[ 0.752624] Unpacking initramfs...
[ 5.572407] Freeing initrd memory: 56636K
Xenial HWE + 2048 MiB of RAM (bad):
[ 5.598647] Unpacking initramfs...
[ 84.494431] Initramfs unpacking failed: junk in compressed archive
[ 84.503565] Freeing initrd memory: 54564K
| Dmitrii Shcherbakov (dmitriis) wrote : | #59 |
Tested bionic-hwe - the issue does not occur with 2048 MiB.
The closest issue filed upstream I found is this: https:/
| Changed in qemu (Ubuntu): | |
| status: | Confirmed → Incomplete |
| Christian Ehrhardt (paelzer) wrote : | #60 |
@Dmitrii - we were at the "junk in ..." in comment #21 already.
The "broken padding" is interesting but might be the same issue with a different message as the newer kernel understands slightly more about it.
That it does only occur with Xenial-HWE but on the same initrd not with the base Xenial kernel is interesting as well. I agree that this is worth the kernel task on this bug (it was the same initrd in this test right)?.
The question is if the initrd really is broken (unlikely since it works with other mem sizes) or that it is broken by qemu/seabios/... when passed to the guest (likely).
Having such a *full set* of affected files would be great.
What we'd need is that you'd copy the kernel+
I have seen you have attached the initrd of your case at least in comment #56 - thanks!
I'll taken another look at the issue with that initrd that you attached, will let you know if I need more.
| Christian Ehrhardt (paelzer) wrote : | #61 |
Ran with:
- the cloud-image of Xenial of 20190419 [1]
- XML with a memory definition of:
<memory unit='KiB'
<currentMemory unit='KiB'
- kernel&initrd are from the host
<kernel>
<initrd>
- The attached broken initrd of comment #56
- Otherwise it is a uvtool kvm guest as it is created on Bionic
- Host is Bionic
- different kernels:
- xenial
- xenial hwe
- bionic
- bionic-hwe
Actually after above yielded no useful results I decided to even exclude libvirt from the equation for now (we don't even need a disk, just need to know if the kernel can extract the initrd):
$ sudo qemu-system-x86_64 -enable-kvm -m 2048M -nographic -serial mon:stdio -append 'console=ttyS0' -kernel bug-1797581-bionic-hwe -initrd bug-1797581-bad-initrd
All kernels loaded the attached broken initrd just fine.
:-/ no repro yet
@Dmitrii:
- in the past we were unsure if this padding would be mangled by bootloaders, tfp or anything like it. Do you reproduce that locally or through maas still?
- The ramdisk that you attached is bionic it seems - is that correct?
- Please test the same without a disk, it should not matter and saves a lot of space when attaching files here.
- Would you mind attaching the full set of a broken case (kernel+initrd+xml)
- report the full commandline that the broken boot called qemu with?
- If you run this in maas or libvirt still, would you mind to step by step check if the same occurs
a) without maas (only in libvirt)
b) without libvirt (probably check which args e.g. -m it exactly passes to qemu)
[1]: https:/
| Christian Ehrhardt (paelzer) wrote : | #62 |
Fro experimenting with sizes things can easily be padded with zeros:
$ truncate -s 80000000 bug-1797581-bad-initrd-
$ truncate -s 9000000 bug-1797581-xenial-
Boots just as well afterwards.
| Dmitrii Shcherbakov (dmitriis) wrote : | #63 |
- boot-resources-20190419-115735-amd64-generic-bionic.tar.gz Edit (242.7 MiB, application/x-tar)
tar -czvf boot-resources-
boot-resources/
boot-resources/
boot-resources/
boot-resources/
boot-resources/
| Dmitrii Shcherbakov (dmitriis) wrote : | #64 |
The bionic/ga files from #63 need to be placed into both dirs:
1) /var/lib/
2) /var/lib/
The sha256 of the *initrd file* that triggers the issue is
69ca457a119fe30
Be careful with daily image auto-updates because a recent update have overridden the files for me and the issue was no longer possible to reproduce.
| Dmitrii Shcherbakov (dmitriis) wrote : | #65 |
- maas-vhost6-libvirt-direct-boot.xml Edit (11.8 KiB, application/xml)
Tried using direct kernel boot with QEMU and couldn't reproduce it:
sha256sum /mnt/libvirt-
69ca457a119fe30
30463 qemu-system-x86_64 -enable-kvm -name guest=maas-
| Christian Ehrhardt (paelzer) wrote : | #66 |
After a longer session on IRC this is now also for Dmitrii un-reproducible.
Lets summarize the current status for the next oen coming by:
Current ideas still are:
a) at 2G the placement of kernel/initrd is too close (as placed by pxelinux), then when the kernel unpacks it overwrites the initrd
b) maas pxe backend might add some bits in transmission that break it
=> both of the above might depend on there kernel/initrd size (which would be why some kernels/daily images are affected)
We would be back needing a case that reliable triggers outside of MAAS.
If affected read through the former comments
0. safe and attach here your kernel/initrd/xml to help reproducing it in some debuggable way
0. state the Host OS version and components libvirt/qemu/maas used
1. check if it does reproduce reliably for you (retry a few times)
2. try to do the same without PXE booting (so far always resolved the case)
(see above for details)
3a. if you get it recreated without PXE report here how you did so
3b. if only with MAAS then try to modify sizes of the roms (comment #62)
... (per discussion)
| Christian Ehrhardt (paelzer) wrote : | #67 |
@sfeole Thanks for the Dup hit that as well now - as all others I ask you to please help to catch the data needed to finally recreate and debug this.
From IRC:
[07:00] <cpaelzer> sfeole: please attach your guest XML, and the used initrd and kernel to the bug
[07:02] <cpaelzer> best would be also the pxeconfig that is provided
@MAAS Team
So far this only occurred with MAAS and all other tries to recreate worked.
I wonder if either TFTP or the PXE loader used could be the trigger of the bug.
Therefore (from IRC as well):
[07:02] <cpaelzer> roaksoax: on this bug one of the components we still have to verify if it is related is the way you provide the TFP
[07:02] <cpaelzer> could you outline on the bug how users once they hit the bug could extract that and attach it to the bug
[07:03] <cpaelzer> that way we can hopefully finally recreate the case
I tried so back in comment #31, but that was only trying to recreate your setup.
For PXEconfig (I was guessing) and TFTP (I used the normal tftpd package) we could still get more similar to your setup.
I'll add a section to the description of the bug what users are supposed to attach, it would be great if you could help to outline how users can get those.
@MAAS Team
[07:03] <cpaelzer> and IIRC you don't use tftpd or such but something maas internal for tftpd is that right - could you outline how one could use/setup this so that we can compare tftpd vs maas-tftpd as well?
That is an extra question to that above, if you could help here as well that would be great.
| description: | updated |
| Christian Ehrhardt (paelzer) wrote : | #68 |
Added to the description what we need from anyone affected.
@Maas Team see former comment for the requested guiding of users how to get this data.
The Maas task is back from incomplete to confirmed for providing these howto's
| Changed in maas: | |
| status: | Incomplete → Confirmed |
| Reto Glauser (rglauser) wrote : | #69 |
- Diff of virsh vm configuration Edit (2.0 KiB, text/plain)
I can also confirm the reported issue. I've tried with Juju and plain MAAS to create a VM with just 2048MB and it fails in both cases. Creating, registering and commissioning the machine works, but it cannot be deployed.
System information: 18.04.2 LTS up-to-date
MAAS version: 2.5.3 (7533-g65952b41
Kernel version: 5.1.3 (Ukuu)
I don't see what information we have to provide (last comment from @paelzer)?
I've added a diff of the VM configuration ($ virsh dumpxml vm), but I don't see any unexpected difference. The VM with 4096MB memory specification boots and can be deployed while the 2048MB VM cannot.
| Christian Ehrhardt (paelzer) wrote : | #70 |
Yeah, it seems to only occur with the TFTP setup that maas creates - and in all former cases it resolved a few days later - most likely by size of images changing.
That is the reason we need the files from an affected case.
@Reto - please see in the bug description above, there is a section "If you are affected, please attach to the bug"
P.S. I'm still waiting on help by the Maas Team to better explain how to get these artifacts, but get what you can and attach it - if it works finally to reproduce it outside of Maas I can work on it, otherwise I'm still bound on waiting for the Maas Team to debug it.
| Kellen Renshaw (krenshaw) wrote : | #71 |
Ran into this today, attaching the information requested in #51.
Unable to commission/install 18.04 with "No minimum kernel"
MAAS version: maas 2.5.3-7533-
Guests kernel paniced on two hosts (host1 and host2), dpkg -l attached for each host.
Console output from each failed guest (vm*_console.log)
Libvirt xml from each failed guest (vm*.xml)
attaching squashfs, boot-kernel, and boot-initrd used by MAAS for the failed boots.
Running host kernels:
host1: Linux host1 5.0.0-17-generic #18~18.04.1-Ubuntu SMP Wed Jun 5 12:43:23 UTC 2019 x86_64 x86_64 x86_64 GNU/Linux
host2: Linux host2 4.15.0-52-generic #56-Ubuntu SMP Tue Jun 4 22:49:08 UTC 2019 x86_64 x86_64 x86_64 GNU/Linux
regiond log of latest image download:
2019-06-22 23:14:06 regiond: [info] 127.0.0.1 GET /MAAS/images-
agent: python-
2019-06-22 23:14:09 regiond: [info] 127.0.0.1 GET /MAAS/images-
.1 --> 200 OK (referrer: -; agent: python-
2019-06-22 23:14:09 regiond: [info] 127.0.0.1 GET /MAAS/images-
.1 --> 200 OK (referrer: -; agent: python-
2019-06-22 23:14:19 regiond: [info] 127.0.0.1 GET /MAAS/images-
--> 200 OK (referrer: -; agent: python-
2019-06-22 23:14:22 regiond: [info] 127.0.0.1 GET /MAAS/images-
OK (referrer: -; agent: python-
2019-06-22 23:14:23 regiond: [info] 127.0.0.1 GET /MAAS/images-
OK (referrer: -; agent: python-
2019-06-22 23:14:27 regiond: [info] 127.0.0.1 GET /MAAS/images-
> 200 OK (referrer: -; agent: python-
2019-06-22 23:14:27 regiond: [info] 127.0.0.1 GET /MAAS/images-
> 200 OK (referrer: -; agent: python-
2019-06-22 23:14:30 regiond: [info] 127.0.0.1 GET /MAAS/images-
HTTP/1.1 --> 200 OK (referrer: -; agent: python-
2019-06-22 23:14:31 regiond: [info] 127.0.0.1 GET /MAAS/images-
HTTP/1.1 --> 200 OK (referrer: -; agent: python-
2019-06-22 23:14:31 regiond: [info] 127.0.0.1 GET /MAAS/rpc/ HTTP/1.1 --> 200 OK (referrer: -; agent: provisioningser
ce.ClusterClien
2019-06-22 23:14:35 regiond: [info] 127.0.0.1 GET /MAAS/images-
1.1 --> 200 OK (referrer: -; agent: python-
2019-06-22 23:14:35 regiond: [info] 127.0.0.1 GET /MAAS/images-
1.1 --> ...
| Kellen Renshaw (krenshaw) wrote : | #72 |
| Kellen Renshaw (krenshaw) wrote : | #73 |
| Kellen Renshaw (krenshaw) wrote : | #74 |
| Kellen Renshaw (krenshaw) wrote : | #75 |
| Kellen Renshaw (krenshaw) wrote : | #76 |
| Kellen Renshaw (krenshaw) wrote : | #77 |
| Kellen Renshaw (krenshaw) wrote : | #78 |
| Kellen Renshaw (krenshaw) wrote : | #79 |
| Kellen Renshaw (krenshaw) wrote : | #80 |
| Christian Ehrhardt (paelzer) wrote : | #81 |
Thanks Kellen,
I took your kernel/initrd and IPXE booted it fine via http from qemu's IPXE on a 2G guest.
In the past we tried more (use squash, use tftp instead of http, use the same parmlines as maas, ...), but it all comes down to the same thing every time - only occurs inside Maas.
Therefore we are again back at my request to the Maas team to help me with this issue as it continues to not show up without Maas being involved.
We had many discussions about this in the past, but I realized that with Mike many of these thoughts might have left. In a perfect world a Maas team member would set up a system using the Artifacts that @Krenshaw provided to reliable recreate the issue (with Maas) on an internal. Then we'd start a full afternoon debugging together (hangout with both of us on the same system) to one by one replace components of the Maas setup in order to finally get this to be debuggable without Maas (or have an idea where/what in side Maas things might break).
| tags: | added: cscc |
| Christian Ehrhardt (paelzer) wrote : | #82 |
It was already clear on the bug that for qemu I can't do much more as-is.
So I had a discussion with the Maas Team today.
To core issue for me stays that it seems it is unreproducible outside of Maas.
We agree that:
- they try to recreate it in a MAAS
- Once they can we sync and find day(s) to sit together working on this
- The mission then is to eliminate maas components and replace them with "usual" ipxe setups one by one and thereby either identify the maas component to analyze OR get finally a reproducible case for qemu development
- There is a fallback if until the next sprint in early 2020 the case is still not reproducible then MAAS will also consider it incomplete/
| Joshua Powers (powersj) wrote : | #83 |
As this is subscribed to field-high and field-medium I am unsubscribing field-high. There has been no update for 9 months to this bug. If folks are still seeing this then additional logs and help reproducing would be much appreciated.
| Alberto Donato (ack) wrote : | #84 |
Setting this to incomplete for maas as weel, since we couldn't reproduce the issue with maas 2.7.
Please reopen if it happens again, with steps on how to reproduce
| Changed in maas: | |
| status: | Confirmed → Incomplete |
| Changed in maas: | |
| status: | Incomplete → New |
| status: | New → Incomplete |
| Changed in maas: | |
| status: | Incomplete → Invalid |
| Thorsten Merten (thorsten-merten) wrote : | #85 |
Cannot reproduce this on any recent MAAS.
This doesn't appear to be a UI issue. Steve, has taken a look into the templates but it all seems to be displaying correctly.