[2.3, service-tracking] Network partition breaks HA rack controller which doesn't stop services
| Affects | Status | Importance | Assigned to | Milestone | |
|---|---|---|---|---|---|
| MAAS |
Fix Released
|
High
|
Blake Rouse | ||
| 2.3 |
Triaged
|
High
|
Unassigned | ||
Bug Description
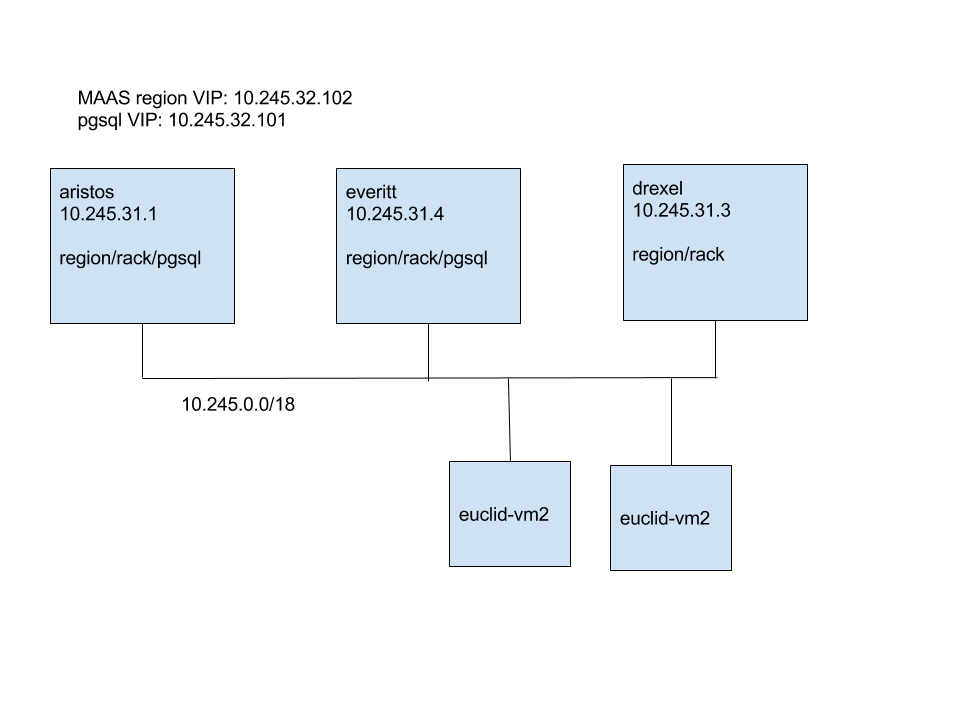
I have an HA setup with 3 MAAS controllers, each running rack controllers and region controllers.
On two of the three controllers, I used iptables to drop traffic from the third, to simulate a network partition.
Then I instructed MAAS to deploy a node. The node powered on fine, but when it started PXE booting, the third isolated rack controller responded to the DHCP request, gave it an IP, and told it to talk to it via tftp to get its pxelinux.cfg.
That rack controller was unable to provide the pxelinux.cfg because it couldn't reach the region controller via the VIP due to the network partition, and the node failed to PXE boot.
I think that the isolated rack controller should not be running DHCP. If a rack controller can't reach the region controller, it can't handle PXE booting a node, and shouldn't try. If it would not have responded, one of the functional rack controllers would have and it would be fine.
In the attached logs, 10.245.31.4 is the node that was isolated. I started the isolation at about 21:15.
This is with 2.3.0-6434-
Related branches
- Andres Rodriguez (community): Approve
- MAAS Lander: Approve
-
Diff: 276 lines (+160/-8)5 files modifiedsrc/provisioningserver/plugin.py (+9/-0)
src/provisioningserver/rpc/clusterservice.py (+54/-5)
src/provisioningserver/rpc/common.py (+20/-0)
src/provisioningserver/rpc/tests/test_clusterservice.py (+67/-1)
src/provisioningserver/tests/test_plugin.py (+10/-2)

| Changed in maas: | |
| status: | New → Incomplete |
{kind=link}
| summary: |
- [2.3, ha] rack controller HA fails during a network partition + [2.3, ha] Network partition for HA rack controller doesn't stop services |
| summary: |
- [2.3, ha] Network partition for HA rack controller doesn't stop services + [2.3, ha] Network partition breaks HA rack controller which doesn't stop + services |
| Changed in maas: | |
| milestone: | 2.4.0alpha1 → 2.4.0alpha2 |
| Changed in maas: | |
| milestone: | 2.4.0alpha2 → 2.4.0beta1 |
| summary: |
- [2.3, ha] Network partition breaks HA rack controller which doesn't stop - services + [2.3, ha, b1] Network partition breaks HA rack controller which doesn't + stop services |
| summary: |
- [2.3, ha, b1] Network partition breaks HA rack controller which doesn't - stop services + [2.4, service-tracking, 2.3] Network partition breaks HA rack controller + which doesn't stop services |
| Changed in maas: | |
| milestone: | 2.4.0beta1 → 2.4.0beta2 |
| summary: |
- [2.4, service-tracking, 2.3] Network partition breaks HA rack controller + [2.3, service-tracking] Network partition breaks HA rack controller which doesn't stop services |
| Changed in maas: | |
| assignee: | nobody → Blake Rouse (blake-rouse) |
| status: | Triaged → In Progress |
| Changed in maas: | |
| milestone: | 2.4.0beta2 → 2.4.0beta3 |
| milestone: | 2.4.0beta3 → 2.4.0rc1 |
| Changed in maas: | |
| status: | In Progress → Fix Committed |
| Changed in maas: | |
| milestone: | 2.4.0rc1 → 2.4.0beta3 |
| Changed in maas: | |
| status: | Fix Committed → Fix Released |
Hey Jason,
The information you provide is not enough for us to determine the configuration that you have. Since you now have a set environment, it would be ideal to have a graph or something that show us how you are configuring your MAAS HA environment, as it is difficult to understand without having a picture of how things are physically connected.
That said. I have a few questions. As I understand, you have 1 rack controller isolated from the *VIP* of the region controller. I guess this means that rackd.conf points to the VIP. But:
1. Can the rack controller connect to the region controllers directly ?
2. What is the state of the rack controller once it cannot connect to the VIP?
3. Is this rack controller a secondary for DHCP HA?