
load spike on HA 2.2.6 controller following remove-application
Bug #1733708 reported by
Paul Collins
This bug affects 7 people
| Affects | Status | Importance | Assigned to | Milestone | |
|---|---|---|---|---|---|
| Canonical Juju |
Fix Released
|
High
|
Unassigned | ||
| 2.2 |
Won't Fix
|
High
|
Andrew Wilkins | ||
| 2.3 |
Fix Released
|
High
|
Andrew Wilkins | ||
Bug Description
One of our common deployments involved deploying a new Juju application, making its units active in haproxy, removing the previous application, and waiting for it to be removed.
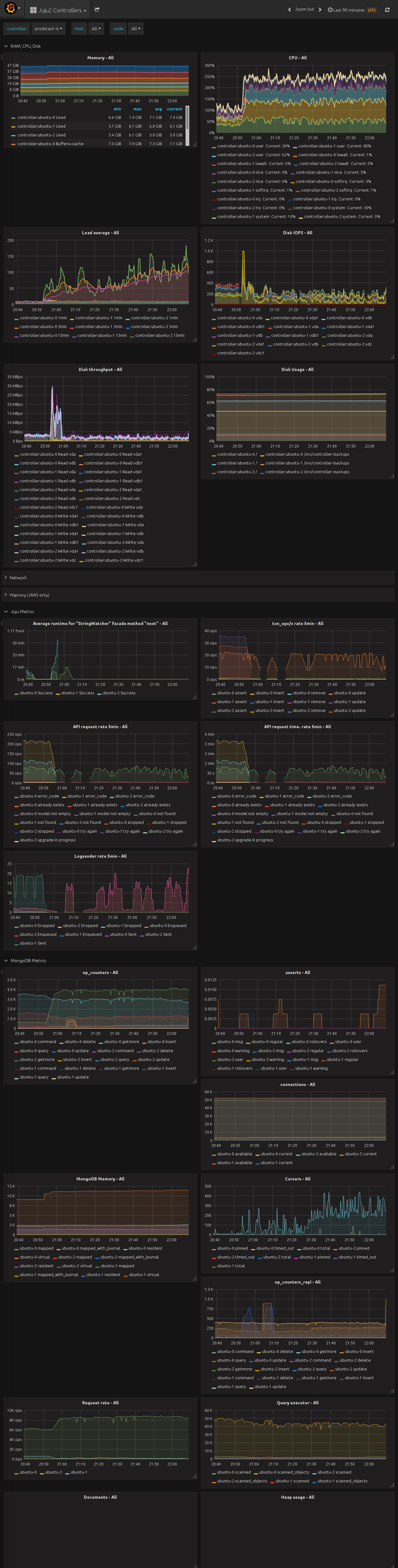
Today during such a deployment, our 3 x node 2.2.6 controller started registering increasing load and ever more mongodb operations, and increasingly poor response times, e.g. multiple minutes to request "juju status" of a single application (see attached Grafana screenshot).
The load spike lines up with one of the deployment scripts having issued juju remove-application after the new application was deployed and made active.

{kind=link}
| description: | updated |
| Changed in juju: | |
| status: | New → Triaged |
| importance: | Undecided → High |
| milestone: | none → 2.3.1 |
| Changed in juju: | |
| milestone: | 2.3.1 → none |
| Changed in juju: | |
| milestone: | none → 2.3.2 |
| Changed in juju: | |
| milestone: | 2.3.2 → 2.4-beta1 |
| status: | In Progress → Triaged |
| assignee: | Tim Penhey (thumper) → nobody |
{kind=link}
{kind=link}
| Changed in juju: | |
| status: | Fix Committed → Fix Released |
To post a comment you must log in.
some mongotop: https:/