Incorrect vowel & consonant position while typing in Thai
| Affects | Status | Importance | Assigned to | Milestone | |
|---|---|---|---|---|---|
| Inkscape |
In Progress
|
Medium
|
poju | ||
Bug Description
While typing in Thai, vowel named "Sara Um" is incorrectly positioned and causes other consonants to be misplaced. This bug occurs in Inkscape 0.91 while 0.48 is fine. I also attached a picture how this should be rendered.
OS: Ubuntu 15.04

| Phinitnan Chanasabaeng (crackerizer) wrote : | #1 |
{kind=link}
| su_v (suv-lp) wrote : | #2 |
| Changed in inkscape: | |
| status: | New → Incomplete |
| tags: | added: fonts regression text |
| description: | updated |
| Phinitnan Chanasabaeng (crackerizer) wrote : | #3 |
- drawing.svg Edit (3.1 KiB, image/svg+xml)
{kind=link}
I attached a test file with this comment. AFAIK, the bug affects all Thai fonts on my system. Viewing and importing it with Gnome image viewer and Gimp do not show the problem.
| Changed in inkscape: | |
| status: | Incomplete → New |
| su_v (suv-lp) wrote : | #4 |
- 1425387-0485-vs-091-osx-x11-2.png Edit (158.1 KiB, image/png)
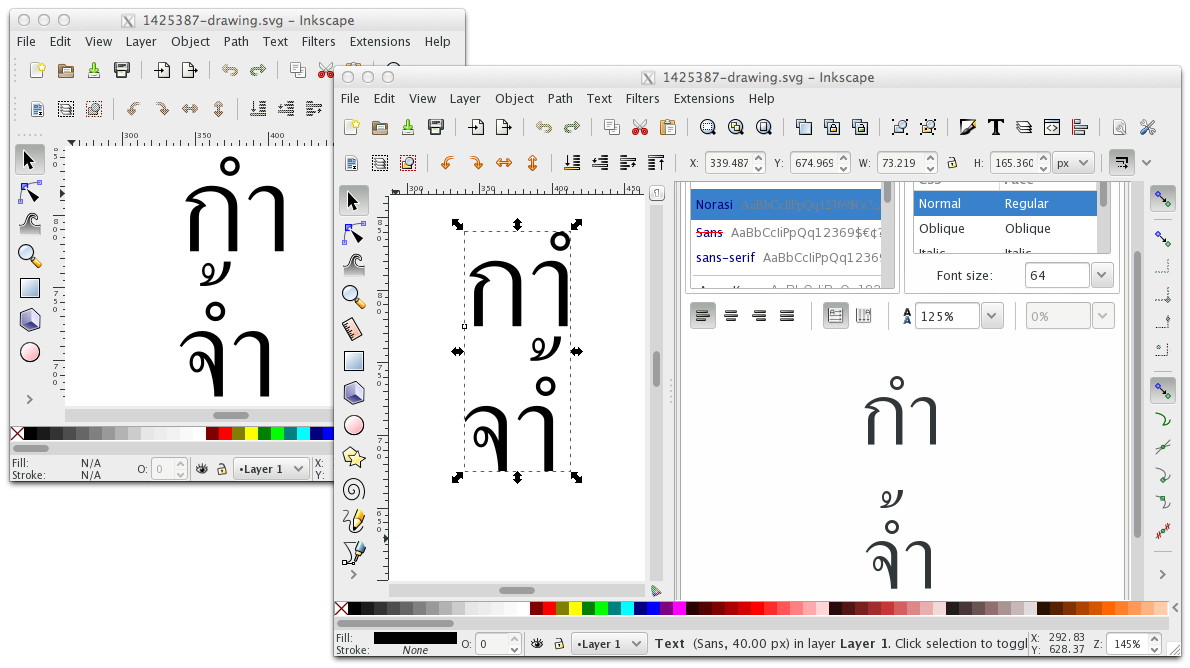{kind=link}
Reproduced with Inkscape 0.91 r13725 and 0.91+devel r13941 on OS X 10.7.5
Based on tests with archived builds:
- not reproduced with rev <= 13727,
- reproduced with rev >= 13729
this seems to be a recent regression introduced with the fix bug #1282968, bug #1304602 and bug #1382747:
http://
| Changed in inkscape: | |
| importance: | Undecided → Medium |
| status: | New → Confirmed |
| Changed in inkscape: | |
| milestone: | none → 0.92 |
| David Mathog (mathog) wrote : | #5 |
That a bug fix in this region of code caused a regression does not surprise me. The Inkscape code which was modified is a layer above Pango and this code is making assumptions about how languages behave - without knowing what language it is dealing with and which rules actually apply for that language. So that fixing a Telugu problem breaks Thai is not at all surprising. [This whole section of code should be thrown in the dust bin and replaced with, for instance, the equivalent section from LibreOffice, where there are more developers working in more languages. That would be a huge job, of course.]
Anyway, I took a quick look at it and see that I do not have enough information to understand what the actual problem is. I will at least need the following to have any chance of figuring it out:
1. Does this only happen with the Norasi font or does it also occur with other Thai fonts?
2. Is the issue only when you type text in on Inkscape, or is it a matter of the unicode string no matter where it comes from? For instance, could you cut that text from another application and paste it into Inkscape and have it look as it should?
3. ~suv's example shows that the fonts are on different characters in the drawing surface and the Text and Font.. display.
Which one is correct?
4. I opened drawing.svg on r13915 on Windows XP and it used "Norasi" font and it didn't look like either one of your examples. It does look like one pane in the one ~suv posted. See attachment. Since I have no idea what any of the
symbols mean I cannot work with that amount of variation. (Opening it in Firefox didn't help, it was a mess in there.) Please provide an SVG with a much longer section of Thai text. Something that uses all the consonants and vowels, if that is possible. If it will not fit on one line make them separate text boxes. Please put a couple of extra spaces between words, and provide a picture of what this should look like.
5. Are you aware of anything unusual, with respect to Unicode properties of the vowel in question, or the Thai language in general? Is the language L->R or R->L? Does it have any unusual grouping properties? Does it have modifiers that change the shape of base glyphs other than by placing a vowel marking on or near a base consonant?
6. Is it just that one vowel that causes this issue, or all vowels?
| David Mathog (mathog) wrote : | #6 |
{kind=link}
| poju (popjussi) wrote : | #7 |
- Screenshot from 2015-07-05 00:36:21.png Edit (36.3 KiB, image/png)
{kind=link}
1. This happens in many Thai fonts, not just Norasi. But it is not occurring with all Thai fonts.
2. Cut & paste also produce the problem.
3. The correct behavior is in the Text and Font panel.
4. This is call "Sara am" http://
5. Thai is L->R
I attached the structure of the character in fontforge screenshot to show that it's just a single glyph. It should work just like other consonants in most case.
| poju (popjussi) wrote : | #9 |
{kind=link}
| poju (popjussi) wrote : | #10 |
Please help me taking a look at 1.1.3 Substitution
http://
Thank you very much.
| poju (popjussi) wrote : | #11 |
(referring to inkscape-
the order of glyph pulled from unbroken_
(Now I hope you can see these glyphs below)
This is like decomposing 2 glyphs [ ท , ำ ] into 3 glyphs [ ท , ํ , า ] which should be the usual order but in the glyph array it seems the order is [ ท, า , ํ ] Is this intended? I tried to swap the order but so far I just got a long space before 'า' though the ( ํ ) seems to be in the right place.
| poju (popjussi) wrote : | #12 |
- Screenshot from 2015-07-05 14:51:48.png Edit (25.3 KiB, image/png)
{kind=link}
While I had no clue if it was the right approach, I tried to add an if() to catch the sequence right after for(), swapped their .glyph and .width, now I got this problem instead.
| poju (popjussi) wrote : | #13 |
I forgot to tell that the new problem is ( ้ ) was placed too far to the right. The correct result for this can be demonstrated by composing the string with char ( ํ ) + ( ้ ) + ( า ) instead of ( ้ ) + ( ำ ) or just see the Text & Font panel. I don't know why Inkscape don't just do exactly what Pango suggested for the positioning but there probably are good reasons for that.
| poju (popjussi) wrote : | #15 |
- Screenshot from 2015-07-05 20:44:25.png Edit (56.0 KiB, image/png)
{kind=link}
My current fix is just commenting this ligatures sorting out.. but I know it will break something else. Is there a way you can query the type of the script engine before deciding to sort those ligatures? Is there any chance that you can commit this and add the fixes Telugu later? Because the way you implement it looks a little hackish in my humble opinion and it should be bad to keep the hackish code that break Thai when Thai does follow the common practices correctly, doesn't it? But I'll try to help with Telugu as much as I can. Thank you.
--- Layout-
+++ Layout-
@@ -1271,9 +1271,11 @@
+ /*
+ */
| poju (popjussi) wrote : | #16 |
This shouldn't break the old hack. By caching the language pointer in _buildSpansForP
--- Layout-
+++ Layout-
@@ -1099,6 +1099,8 @@
TRACE(("build spans\n"));
para-
+ PangoLanguage* cache_pango_
+
for(
if (_flow.
@@ -1248,6 +1250,7 @@
+
@@ -1263,6 +1266,7 @@
+ const PangoLanguage* item_lang = para->pango_
@@ -1271,7 +1275,8 @@
- if(j - i){
+
+ if( item_lang && item_lang != cache_pango_
| poju (popjussi) wrote : | #19 |
- See my previous comments for descriptions. Edit (1.7 KiB, text/plain)
just bzr branch, so here's the patch.
| poju (popjussi) wrote : | #20 |
- patch-inkscape-r14232-fix-1425387.diff Edit (1.4 KiB, text/plain)
A bit of improvement, just skip the whole reclustering loop since it does nothing.
| jazzynico (jazzynico) wrote : | #21 |
@David - Could you please give your opinion on the patch proposed comment #20.
As explained by poju, it could be safer to apply the changes from rev. 13729 to Telugu only so that they don't break other languages.
| Changed in inkscape: | |
| assignee: | nobody → poju (popjussi) |
| status: | Confirmed → In Progress |
| poju (popjussi) wrote : | #22 |
- patch-inkscape-r14236-fix-1425387.diff Edit (6.7 KiB, text/plain)
This patch included the 2nd patch, and also try to solve some problems that the previous patch has not addressed.
The new problem was that once the 2nd patch bypassed the old loop that reset the "is_cluster_start"
it made the old flow builder to also use the old assumption that was indicated as a hack to survive ligature.
I create a new case only to apply to Thai by not to change the behavior of the cluster and treat the cluster
like a single and unbreakable glyph. This way the _flow._characters and _glyphs will be properly constructed
for Thai and won't have trouble like putting the text on path like my second patch has caused.
In this patch I mainly try to scope the problem into a block and didn't try hard to integrate itself into the
current logic. eg. The following glyphs in the cluster were generated in its own loop once Thai was detected,
along with the new characters.
Additional works to be decided by some Thai in future could be started around in this Thai block to avoid Latin assumptions
like to break the a particular Thai cluster that involve U+0E33, since it isn't a true ligature if you look at it.
Breaking the cluster would help with adding the extra space between characters when you need that.
So the layout won't avoid adding some spaces before U+0E33
Although you can avoid that by using Nikhahit (E+0E4D) + Sara AA (E+0E45) instead of U+0E33
to get the non-ligature effects.
| David Mathog (mathog) wrote : | #23 |
See the first paragraph of note 5 above. All of these little patches, yours and mine, are never going to settle into a system which works for all languages. Fix one thing, it will break another. Inkscape is only partly "pangofied" and while that could be beaten into submission for relatively simple European languages it keeps tripping up on languages which combine glyphs in inscrutable ways. As I've said before, fixing this looks like a lot of work. Minimally Inkscape would have to start "thinking" in logical clusters, the way Pango breaks unicode down into a glyph representation. That Inkscape works as well as it does for the European languages is because those logical clusters usually resolve to a single character, or at worst a single character with an accent or other mark above or below it. That allows for a simple "advance" view on a glyph by glyph basis with some exceptions thrown in for the accents, which don't advance. It seems to work out OK for Japanese and Chinese too, where again, I think the unicode maps a logical clusters to one glyph. However, it falls apart badly for Indic languages, and apparently Thai, which really need to operate on those logical clusters.
Basically every place you find a reference to a glyph's width needs some sort of change, so that it works instead on logical clusters and their widths.
This may also be relevant to some of your questions above:
https:/
| poju (popjussi) wrote : | #24 |
Hi David, while I understand your frustration, I don't really have time to redesign the text system of Inkscape with you at this point. In this case my patch already consult Pango for the Thai language use for each cluster so it shouldn't break the others. In case that there will be more languages we could just hash them. Also, I don't think this particular case has much to do with the Telugu bug. Because the chunk of my code seems to render Telugu just fine, as far as I look at it. May be I was wrong. But that doesn't prevent a Thai block for this.
Is it possible that you can revise and/or commit it? Because Thai isn't usable at the moment and my code shouldn't alter other languages' behavior. Thank you.
| poju (popjussi) wrote : | #25 |
OTOH I am fully aware of the pango-glyph-
| poju (popjussi) wrote : | #26 |
- flowRoot28.png Edit (132.7 KiB, image/png)
{kind=link}
I tested it in several ways, no problem for Thai so far. What you can do when you can't get the actual positions of the characters that were mapped like 3 characters to 4 glyphs is that you can just delete the whole cluster and type it. Thai clusters aren't long.
| Tavmjong Bah (tavmjong-free) wrote : | #27 |
In the end it would be best to spend the time to fix this properly so that we don't need to have language specific code. Pango should be able to do the right thing for any language.
For the short term, I think we can land poju's patch.
On a longer term we should either implement David's idea of using logical clusters or ask that Pango provide line by line layout of wrapped text (Pango can already handle fixed width wrapped text layout).
The Text and Font dialog uses Pango directly without clumping characters into separate blocks so the rendering in the dialog should be correct (or it's a Pango bug).
| Tavmjong Bah (tavmjong-free) wrote : | #28 |
Hmm, I am wondering why we need to reorder the glyphs at all. The whole section about reordering glyphs is because: "Pango_shape si not generating English language ligatures..." This should be retested as Pango does support the OpenType 'liga' and 'clig' tables where common English language ligature are defined.
The 1:1 correspondence between characters and glyphs is broken by ligatures (optional and mandatory) but SVG 1.1 defines how to handle this (for 'dx', 'dy'...).
I don't see why glyphs need to be reordered at all...
| Tavmjong Bah (tavmjong-free) wrote : | #29 |
Just commenting out the sort (L1303) seems to fix the Thai rendering.
| David Mathog (mathog) wrote : | #30 |
- hebrew_with_vowels_ezra.svg Edit (2.7 KiB, image/svg+xml)
{kind=link}
I believe the business about reordering glyphs was needed to make Hebrew (and probably Arabic) vowels work properly. If that is the section I think it is it is a hack I introduced to work around horrifically bad rendering of Hebrew, where the vowels which were supposed to be placed below the main character were instead following it like separate letters. Hebrew apparently also has some odd changing or singing marks which should be placed the same way. I'm pretty sure that if you remove/alter those sections of code it will break the attached example (which really needs to have Ezra SIL font installed to look right, if it falls over to Arial it will look pretty terrible). It may also break some European languages if they are coded as a base letter followed by a separate modifying glyph that is placed above or below that base letter.
Near as I can tell, "in the beginning", Inkscape was designed with European languages and a simple 1:1 correspondence between unicode characters and glyphs. This seems to have been the case before "pangoification". The logic fell apart with pango because it formats things in logical clusters. Until inkscape does things that way all of these little fixes are doomed to break some language or another.
| poju (popjussi) wrote : | #31 |
- hebrewss.jpg Edit (58.6 KiB, image/jpeg)
{kind=link}
Hi David, This is a SS of the text in the SVG taken from Ubuntu linux 14.04, these results among inkscape's text & font panel, drawing surface and with gnome-specimen look identical to me though I have no idea if that looks right. I don't have Ezra SIL font installed and I don't even know how to get the text working with Hebrew. So if this doesn't look like it should be corrected in Pango I guess? (I can't find a specific shaper engine for Hebrew) What the code I am using currently does is to #if 0 the whole block not just the sorting, ie.
#if 0
#endif
| poju (popjussi) wrote : | #32 |
(And commenting the part of the code shouldn't have anything to do with Hebrew as it was handled in the if-right-to-left section above)
| Tavmjong Bah (tavmjong-free) wrote : | #33 |
David, I've tested your file with Inkscape trunk and with Pango 1.36.8 and 1.37.1. With the sort commented out I see the same rendering as shown in Firefox and Chrome except that the exclamation point is on the opposite end.
I think we need to assemble a set of text files for different language. We should also include files that use of multiple 'x', 'y', 'dx', 'dy', attributes.
| David Mathog (mathog) wrote : | #34 |
- hebrew_examples.zip Edit (454.0 KiB, application/zip)
Here are four examples of Hebrew and mixed Hebrew/English in SVG and PNG. Two things to test for any change: 1) that it renders the same, 2) that it does the same thing when more Hebrew or English letters are pasted or typed in between existing letters of that type. (Inserting characters at the interface between two languages is, as I recall, really touchy and kind of unpredictable.)
I think these all use the Ezra Sil font, or Ezra Sil SR, those can be downloaded from here:
http://
If that font isn't present and it fails over to some other it will probably look dreadful.
I just noticed that for a single or multiple line Hebrew text string changing the justification R->C or L works OK, but doing another one right after it causes the text "box" to jump laterally. Testing..., yes it looks like changing from C or L justification is broken. I don't recall that happening in older versions. Easy to demonstrate with the formatted_text_he example. This was revision 14192. Testing with English text, yes, that has a similar problem. Just select some text with justification and click around on the R,C,L buttons and it will eventually jump. I need to report that.
| Tavmjong Bah (tavmjong-free) wrote : | #35 |
All four examples in hebrew_examples.zip render correctly with the "sorting" commented out.
The insertion of <tspan>s (changing color) should not cause rendering problems as the <tspan>s isolate characters from one another (no ligatures across <tspan>s). The more critical test is how multiple 'x', 'y', 'dx', 'dy', and 'rotate' attributes are handled as these do not break mandatory ligatures. The attribute values apply in the order the characters are given in the SVG file. This is probably why the code reverses the order of the glyph clusters from Pango for right to left scripts.
David, do you know why the exclamation point is rendered on the opposite line end in Inkscape relative to Firefox and Chrome?
I've also noticed an alignment problem with Arabic text.
| Tavmjong Bah (tavmjong-free) wrote : | #36 |
- complex_samples_embeded.svg Edit (43.4 KiB, image/svg+xml)
{kind=link}
Here is a test file for a variety of "complex" scripts.
Commenting out the "sort" functions does not change the rendering for the included scripts except for Thai, where commenting out the "sort" functions results in the correct Thai rendering.
Note: Inkscape does not handle the 'unicode-bidi' property thus the Hebrew input is reversed. Firefox and Chrome do handle 'unicode-bidi'.
| David Mathog (mathog) wrote : | #37 |
- two_shalom.svg Edit (2.5 KiB, image/svg+xml)
{kind=link}
Re 35, not sure. Hebrew is R->L and a sentence with an exclamation point should have it at the left end. If it is showing up on the other side it would probably be because the bidirectional code is kicking in, considering the "!" to be a L->R, and then doing something wrong when deciding how to arrange the L->R and R->L pieces.
Re 36. There is another problem in the complex_
The unicode you used for Shalom differs by one bit from one that works. See the attached file two_shalom.svg. This is od -c, which isn't the proper decoding, but at least shows the difference, look at 3'rd from last character.
327 251 327 201 326 270 327 234 327 225 326 271 327 235 (yours)
327 251 327 201 326 270 327 234 327 225 326 272 327 235 (mine)
| David Mathog (mathog) wrote : | #38 |
Oops, sent that too soon, sorry.
However that one bit isn't the problem. The problem is that it is using a font which has crap Hebrew support, which is most of them. Change the font in the one that doesn't work to Ezra Sil or Ezra Sil SR then it will render ok. Mysteriously, that also fixes the broken cut and paste.
| sandthorn (sandthorn) wrote : | #39 |
- sara-um_workaround.png Edit (96.9 KiB, image/png)
{kind=link}
> poju (popjussi) wrote on 2015-07-10:
>
>
> Although you can avoid that by using Nikhahit (E+0E4D) + Sara AA (E+0E45) instead of U+0E33
> to get the non-ligature effects.
>
This workaround doesn't work in Windows 10. After trying to input a Nikhahit character, rendered text disappears from inkscape viewport.
This is tested against Inkscape 0.91 x86_64.
| sandthorn (sandthorn) wrote : | #40 |
Correction for previous comment (#39).
The workaround works just fine indeed.
It was my bad cut&paste in the first place.
I'm sorry for false report.
| Changed in inkscape: | |
| milestone: | 0.92 → 0.93 |
| jeffmcneill (jeffmcneill) wrote : | #41 |
Any progress anticipated on the sara am bug? It is definitely still an issue in 0.92. Language-specific code, if it fixed a problem now, would be an improvement over language-
| jeffmcneill (jeffmcneill) wrote : | #42 |
Just fyi, re-reading this thread it sounds like some hack for Hebrew has broken Thai, though maybe not? In any case, Thai is broken and needs to be fixed. The work around for Thai is not acceptable since while it might render textually (depending upon font in use), it is using two different characters for another single character.
Instead of letting Thai remain broken, remove the hack code that broke it, and fix Hebrew as needed (that is, as a specific language/script).
| David Mathog (mathog) wrote : | #43 |
It looks like Inkscape was originally just for Latin languages and makes an assumption that the "next" glyph will have a width so that it is OK to calculate advance values by just adding glyph widths sequentially. Hebrew has diacritical marks (essentially vowels) which are in a cluster with the primary glyph. The problem was that these would come out in the wrong order, diacriticals first (probably because it is a R->L language), so the advance calculation, based on width, would fail when it looked at the diacritical marks. I believe the fix used was to sort within the cluster by width, because the primary was always wider and the diacriticals had zero width. However, other languages do completely different things with glyph clusters and this is what is probably breaking Thai and other languages.
If anybody has time to fix this (I do not) the correct solution would be to revert the sort "fix" and instead implement a smarter width calculation. My memory is fuzzy but I don't recall that the Inkscape code was carrying along the cluster information at the point the "advance" calculation is performed. Probably somewhere in the underlying libraries there is a "width of this cluster" function which may be employed. (Best person to ask would be Behdad Esfahbod, author of harfbuzz, http://
In other words, go from the current (as I recall, from the last time I looked at it):
glyph array (0->N-1, each with width information)
to
glyph array (0->N-1, each with width information, now ignored for "advance")
glyph cluster array (start,end, cluster width; 0->M-1, M<=N, now used for "advance")
For languages like English or French, where clusters are all 1 glyph, all this does is
move the width into a parallel array. However for more complex languages like Hebrew, Thai, or Hindi it would retain the proper width for glyph clusters all the way to the point where they are rendered.
Please add information about OS/platform to the bug description.
To ease further investigation on other systems, could you please also attach a test case (Inkscape SVG file with text which is affected as described) to the bug report, and provide information about any special fonts needed to reproduce?