VM isn't connected to tenant network
| Affects | Status | Importance | Assigned to | Milestone | |
|---|---|---|---|---|---|
| fuel-ccp |
Triaged
|
High
|
Fuel CCP Bug Team | ||
Bug Description
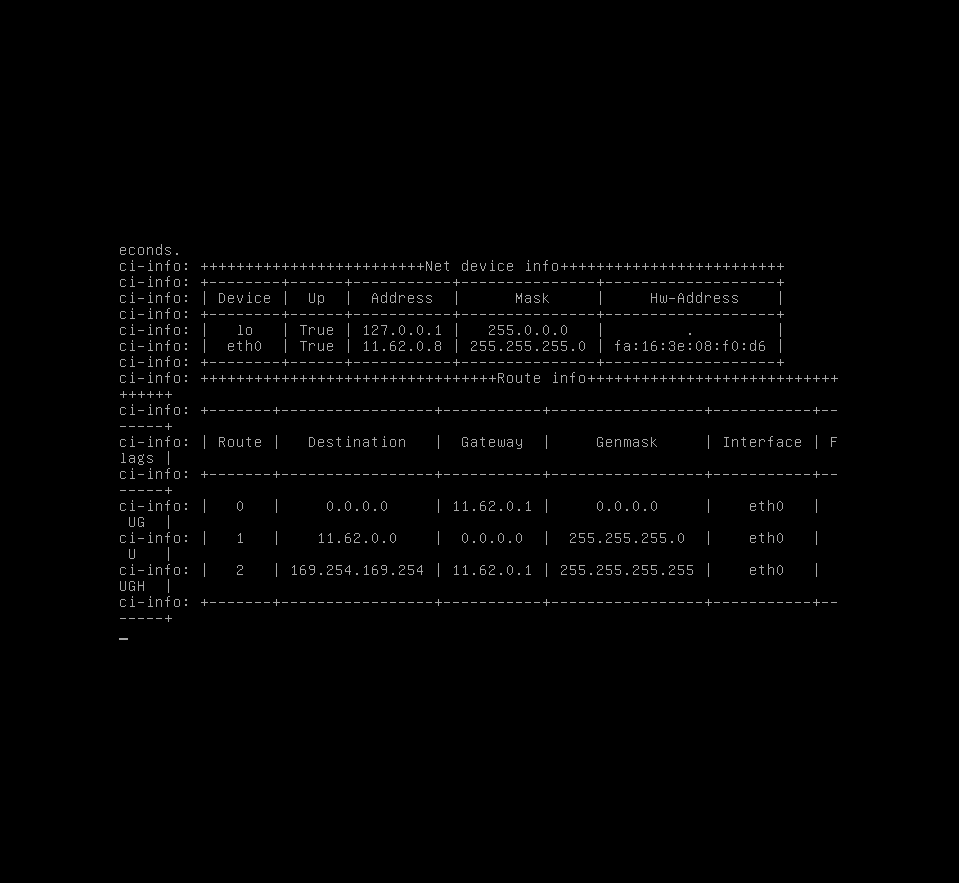
We spawned 72 VMs on top of 3 compute nodes, using heat (24 VMs per one node).
Some instances weren't reachable via tenant network. For example:
| 93b95c73-
root@node1:~# ssh -i .ssh/slace ubuntu@10.144.1.35
Connection closed by 10.144.1.35 port 22
it's unreachable from tenant network as well. For example from instance b1946719-
Environment description:
k8s deployed by Kargo on top of 200 hardware nodes.
logs from OpenStack pods and outputs of some commands have been dumped by this script: http://
and attached here: http://
| description: | updated |

{kind=link}
| Changed in fuel-ccp: | |
| status: | New → Triaged |
| importance: | Undecided → High |
| Changed in fuel-ccp: | |
| assignee: | nobody → Elena Ezhova (eezhova) |
Tried to reboot the VM. It seems the VM reached metadata (see screenshot), but steel unreachable from the tenant network