Cloud images fail to boot when a serial port is not available
Bug #1573095 reported by
zero
This bug affects 35 people
| Affects | Status | Importance | Assigned to | Milestone | |
|---|---|---|---|---|---|
| cloud-images |
Invalid
|
Undecided
|
Unassigned | ||
| cloud-init |
Invalid
|
Undecided
|
Unassigned | ||
| Ubuntu |
Invalid
|
Undecided
|
Unassigned | ||
| initramfs-tools (Ubuntu) |
Fix Released
|
Medium
|
Guilherme G. Piccoli | ||
Bug Description
I tried to launch a ubuntu 16.04 cloud image within KVM.
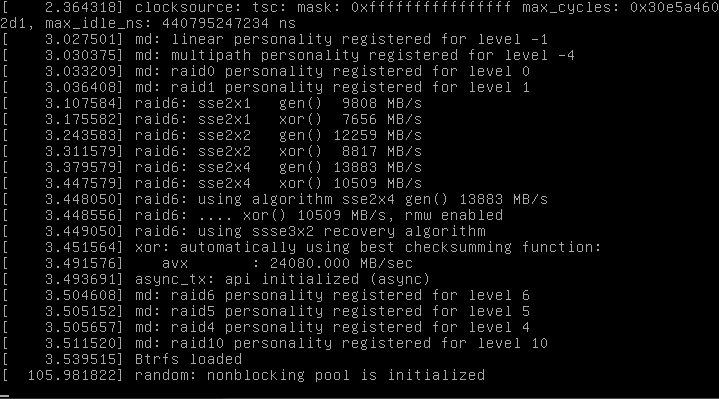
The image is not booting up and hangs at
"Btrfs loaded"
Hypervisor env is Proxmox 4.1
[racb: see comment 40 for minimal steps to reproduce using Ubuntu-provided tooling only]
Related bugs:
* bug 1016695: add console=tty1 to cloud-image kernel boot parameters
* bug 1123220: cloud-image VM causes kernel panic if image is resized
* bug 1061977: Machine fails to commission when console=ttyS0 is present on kernel opts
* bug 1573095: Cloud images fail to boot when a serial port is not available
* bug 1122245: booting from a cloud image hangs until virsh console is used
| affects: | livecd-rootfs (Ubuntu) → ubuntu |
| summary: |
- Cloud image hangs at first boot + 16.04 cloud image hangs at first boot |
| tags: | added: xenial |

{kind=link}
| Changed in cloud-images: | |
| status: | Incomplete → New |
| milestone: | none → y-2016-06-02 |
| Changed in cloud-init: | |
| status: | New → Fix Released |
| no longer affects: | tuxlab |
| Changed in cloud-images: | |
| milestone: | y-2016-06-02 → none |
| tags: | added: id-5b49154499e416396a3e983c |
| tags: | added: sts |
{kind=link}
To post a comment you must log in.
Can confirm this bug, attached is a screenshot. The VM will hang and have a CPU load of 100%, but the boot will never continue.