
Poor system performance under I/O load
| Affects | Status | Importance | Assigned to | Milestone | |
|---|---|---|---|---|---|
| linux (Ubuntu) |
Invalid
|
Undecided
|
Unassigned | ||
Bug Description
This bug seems to particularly affect the Dell Latitude D420, D430 and (from the kernel.org bug) at least the D830 laptop models; but others have been reported.
Under I/O load, which need not be excessive - running usb-creator or even just checking one's email - the system performs remarkably poorly, far less than other laptop users see. It can often take minutes to open a window, and sometimes the screen isn't repainted. Certainly most applications are "dimmed" by Compiz under I/O.
It also appears to massively negatively affect boot performance, with one core spending its entire time in I/O wait - something we don't see elsewhere.

|
|
#20 |
|
|
#21 |
For the record, this is even reproducible with Linus's master.
|
|
#22 |
I'm also having this problem.
Latest working kernel version: 2.6.18.8 with config:
http://
Currently working on 2.6.25.20 with config:
http://
Tested also with 2.6.28 and felt no significant performance improvement.
--
During heavy disk IO's like running 'svn up' hogs the system avoiding the start a new shell, browse on the internet, do some text editing using vim, etc.
For example, after being able to open a text buffer with vim, 4-5 seconds delays happens between consecutive search attempts.
|
|
#23 |
Hello Ben,
I don't known where to post it exactly. Why Linux Memory Management? Or why -mm and not mainstream? Can you do it for me please?
I have added a second test case, which using threads with pthread_mutex and pthread_cond instead of processes with pipes for communicating, to ensure it is a cpu scheduler issue.
I have repeated the tests with some vanilla kernels again, as there is a remark in the bug report for tainted or distro kernels. As I got a segmentation fault with the 2.6.28 kernel, I added the result of the Ubuntu 9.04 kernel (see attachment). The results are not comparable to the results posted before, as I have changed the time handling (doubles instead of int32_t as some echo messages takes more than one second).
The first three results are 2*100, 2*50 and 2*20 processes exchanging 100k, 200k and 1M messages over a pipe. The last three results are 2*100, 2*50, and 2*20 threads exchanging 100k, 200k and 1M messages with pthread_mutex and pthread_cond. I have added a 10 second pause at the beginning of every thread/process to assure the 2*100 processes or threads are all created and start to exchange the messages nearby at the same time. This was not the case at the old test-case with 2*100 processes, as the first thread was already destroyed before the last was created.
With the second test-case with threads, I got the problems (threads:
The meaning of the results:
- min message time
- average message time (80% of the messages)
- message time at median
- maximal message time
- test duration
Here the result.
Linux balrog704 2.6.20.21 #1 SMP Wed Jan 14 10:11:34 CET 2009 x86_64 GNU/Linux
min:0.000ms|
min:0.002ms|
min:0.002ms|
min:0.002ms|
min:0.002ms|
min:0.002ms|
Linux balrog704 2.6.22.19 #1 SMP Wed Jan 14 10:16:43 CET 2009 x86_64 GNU/Linux
min:0.003ms|
min:0.003ms|
min:0.003ms|
min:0.003ms|
min:0.003ms|
min:0.003ms|
Linux balrog704 2.6.24.7 #1 SMP Wed Jan 14 10:21:04 CET 2009 x86_64 GNU/Linux
min:0.003ms|
min:0.003ms|
min:0.003ms|
min:0.003ms|
min:0.004ms|
min:0.003ms|
|
|
#24 |
Created attachment 19795
test case with processes and pipes
|
|
#25 |
Created attachment 19796
test case with threads and mutexes
|
|
#26 |
Created attachment 19797
All testresult on Core2 T7700 @ 2.40GHz / 4GB RAM
|
|
#27 |
I guess the high I/O wait time and the poor responsiveness are the same problem, caused by the cpu scheduler, as I can produce the same symptoms without disc I/O.
Since 2.6.26/27 everyone should be affected by this issue.
What I did not understand is:
Why takes the test with threads and mutexes twice as long as the test with processes and pipes, but stresses the system much more? The mouses freezes nearby immediately, while the test with processes and pipes allows to move the windows.
|
|
#28 |
I've met the high I/O wait problem with 3ware cards on Centos 5.x.
This is related to pci_try_set_mwi. More information here:
https:/
Now Thomas seems to have found another source for the problem. Maybe mwi is adding on top of that (not every controller driver sets MWI - BIOS is supposed to do so, but I've met a couple of boards that do not).
HTH.
|
|
#29 |
If I run "google desktop indexer", then I get the long waits. E.G. vim goes away for up to 5-30 seconds, repeatably!
So, I don't run "google desktop indexer". No problem since 12/15/08!
|
|
#30 |
You can also add the task:
- copy a file from a compactflash card through usb adaptor or pcmcia card. The
computer is not usable until the copy of the file (3 to 5 megas) is finish. It
doesn't matter if it copy the whole card or only a file. It seems to be similar
to the description of the bug here.
|
|
#31 |
I have found that this may be an issue with the Complete Fair Queuing I/O scheduler that was introduced as default in 2.6.18 (when most started observing this performance issue). Reverting back to the old AS scheduler for me seems to have resolved the problem.
To use the AS scheduler and test for yourself, just specify "elevator=as" as a boot option.
|
|
#32 |
(In reply to comment #2)
> I'm also having this problem.
>
> Latest working kernel version: 2.6.18.8 with config:
>
> http://
>
> Currently working on 2.6.25.20 with config:
>
> http://
>
> Tested also with 2.6.28 and felt no significant performance improvement.
>
> --
>
> During heavy disk IO's like running 'svn up' hogs the system avoiding the
> start
> a new shell, browse on the internet, do some text editing using vim, etc.
>
> For example, after being able to open a text buffer with vim, 4-5 seconds
> delays happens between consecutive search attempts.
You seem to be able to reproduce the bug easily, and have found a non affected kernel version.
Can you git bisect between those kernels to at least isolate the culprit commit?
|
|
#33 |
(In reply to comment #3)
>
> With the second test-case with threads, I got the problems
> (threads:
> 2.6.20.21 was fine with both test-cases.
I'm not sure that's the same issue I had when I posted but 7372, but since you seem to be a programmer you should git bisect between those kernels to isolate the culprit commit.
|
|
#34 |
I'm not sure if this is related or not, but I'm getting similar behaviour on my own system, but *only* when copying files *from* my USB memory stick (a 4 GB Corsair Flash Voyager) *to* the internal SSD on my Asus Eee PC 900 running Ubuntu 8.10 with a custom build of Linux 2.6.27 (probably slightly patched) provided by array.org.
I.e. reading a file from the USB stick to /dev/null, no slowdown.
Writing /dev/zero to USB stick, no slowdown.
Reading a file from the internal SSD to /dev/null, no slowdown.
Writing /dev/zero to internal SSD, no slowdown.
Copying a file from internal SSD to USB stick, no slowdown.
Copying a file from USB stick to internal SSD, I get massive slowdowns on interactive performance. Launching a terminal, which usually takes a few seconds, suddenly takes the better part of a minute.
Linux used is 2.6.27-8-eeepc on i686 SMP, as prebuilt by http://
The filesystem on the internal SSD is ext3, running on LVM, running on LUKS (encrypted filesystem). As set up by the Ubuntu 8.10 installer. Swap is also on the same encrypted LVM.
The filesystem on the USB stick is vfat. Nothing fancy at all.
I should also add that the read performance of my USB stick is faster (about 25 MB/s) than the write performance on the built-in SSD (about 10 MB/s).
If you feel that it is useful, I can provide dumps of lspci/lsusb/lsmod or any other information. As for the exact build options and patches, that should be determinable by checking the web site specified above.
Hope more data makes it possible to determine a pattern to this bug.
|
|
#35 |
I tried the solution of Mike the comment http://
|
|
#36 |
I tried elevator=as on my system, and it did not change the behaviour. Copying files from external USB to internal encrypted SSD still totally smashes interactive performance. So this issue might be unrelated.
|
|
#37 |
(In reply to comment #16)
> I tried elevator=as on my system, and it did not change the behaviour.
> Copying
> files from external USB to internal encrypted SSD still totally smashes
> interactive performance. So this issue might be unrelated.
>
This may be an unrelated issue having to do with USB I/O - since USB seems to be more CPU intensive anyway.
When I experienced this bug (prior to switching from CFQ), it would happen whenever I copied a large file on ATA or SCSI devices and I noticed extremely high I/O wait times - with very low CPU usage. Not only during copying - but during any disk-intensive operation. Everything on my affected machines would come to a grinding halt until the operation was complete. Using AS for me so far has seemed to resolve the issue - as my machines are now responsive as they should be during heavy disk I/O.
|
|
#38 |
I have had a very similar problem to this. I still have it often, but not as
much from when I changed from EXT3 to ReiserFS. For the Scheduler, I've been
using BFQ or V(R) thats included in the Zen Patchset. I have tried the stock
kernel, and same problem exists, however I can't remember which scheduler I
used at that point, I believe Deadline.
Most of the IOWait I get comes when either I'm copying files to the local
drives, or using multiple VM's (generally Windows as thats what is needed for
work). I'm willing to try about anything to get this fixed. It's a little
better since I switched FS's on my VM Drive, but still isn't totally fixed.
|
|
#39 |
(In reply to comment #11)
> I have found that this may be an issue with the Complete Fair Queuing I/O
> scheduler that was introduced as default in 2.6.18 (when most started
> observing
> this performance issue). Reverting back to the old AS scheduler for me seems
> to have resolved the problem.
>
> To use the AS scheduler and test for yourself, just specify "elevator=as" as
> a
> boot option.
>
Fwiw, I've never used the CFQ scheduler. I'm on the deadline scheduler with my 3ware 9560SE and still see this problem crop up from time to time, usually when doing a file copy large enough to fill the page cache.
|
|
#40 |
I too have found that the choice of I/O scheduler makes little difference. Using AS generally yields no noticable improvement.
|
38 comments hidden
Loading more comments
|
view all 695 comments |
| Scott James Remnant (Canonical) (canonical-scott) wrote : | #1 |
{kind=link}
| Changed in linux: | |
| status: | Unknown → Confirmed |
| Scott James Remnant (Canonical) (canonical-scott) wrote : [Fwd: Re: [Fwd: I/O performance regression]] | #2 |
-------- Forwarded Message --------
From: Andy Whitcroft <email address hidden>
To: Scott James Remnant <email address hidden>
Cc: Tim Gardner <email address hidden>, Pete Graner
<email address hidden>
Subject: Re: [Fwd: I/O performance regression]
Date: Mon, 2 Mar 2009 11:37:24 +0000
On Sat, Feb 28, 2009 at 01:06:26PM -0500, Pete Graner wrote:
> Scott was making reference to seeing poor I/O performance, and this being a
> limiting factor for boot time. He pointed to this bug:
>
> http://
Well the first thing to note about this bug is that it is not a report
of poor IO performance, quite the opposite, that IO is perfectly good but
interactivity goes to hell as IO fairness goes out the window. I suppose
if the issue is that new programs and shells are delayed as a result that
might impact boot performance if we have a background readahead in play.
During some experimentation I did notice that one of my build boxes has
its io scheduler set to deadline? Not something I have done deliberatly,
and differing from an almost identicle build box made and upgraded from
the same media in lockstep:
apw@lana$ dmesg | grep io\ scheduler
[ 1.253192] io scheduler noop registered
[ 1.253193] io scheduler anticipatory registered
[ 1.253195] io scheduler deadline registered (default)
[ 1.253248] io scheduler cfq registered
apw@lana$ cat /sys/block/
noop anticipatory [deadline] cfq
I have tried the suggested trigger in the bug running a big dd (which
is a write version of readahead case) and that cirtainly buggers things
up badly if you are using deadline, it is almost impossible to create
new windows or switch to an alternative VT. I tried using ionice in
combination to little effect. Switching to cfq improved things hugely.
We should check the default that has been picked up on your test rig.
There is much conjecture in the bug you link about bugs in both the IO
schedulers and the cpu scheduling too. It has been suggested that
changing time source can help. So it might also we worth switching
timesource for comparison.
apw@dm$ cat /sys/devices/
hpet acpi_pm jiffies tsc
hpet
In theory at least you should be able to boot with clocksource=
for each of the ones listed on the first line there, and confirm it is
enabled.
It would also be interesting to see how adjusting the queue depth for
the disk affects these delays, try the test with the queue at 128 (the
default) 64, 32, and 16 and see how that affects the latencies you see:
echo N > /sys/block/
It is entirly possible we would need different parameters for the boot
phase to typicial desktop usage.
Finally which kernel is this testing occuring on.
-apw
--
Scott James Remnant
<email address hidden>
| Scott James Remnant (Canonical) (canonical-scott) wrote : Re: [Fwd: I/O performance regression] | #3 |
On Mon, 2009-03-02 at 11:37 +0000, Andy Whitcroft wrote:
> During some experimentation I did notice that one of my build boxes has
> its io scheduler set to deadline? Not something I have done deliberatly,
> and differing from an almost identicle build box made and upgraded from
> the same media in lockstep:
>
CFQ appears as the default in dmesg, and is the one assigned to /dev/sda
Scott
--
Scott James Remnant
<email address hidden>
| Scott James Remnant (Canonical) (canonical-scott) wrote : | #4 |
wing-commander scott% dmesg | grep io\ scheduler
[ 2.099335] io scheduler noop registered
[ 2.099339] io scheduler anticipatory registered
[ 2.099343] io scheduler deadline registered
[ 2.099366] io scheduler cfq registered (default)
wing-commander scott% cat /sys/block/
noop anticipatory deadline [cfq]
| Scott James Remnant (Canonical) (canonical-scott) wrote : | #5 |
Default clock source is HPET
wing-commander scott% cat /sys/devices/
hpet acpi_pm jiffies tsc
hpet
| Scott James Remnant (Canonical) (canonical-scott) wrote : | #6 |
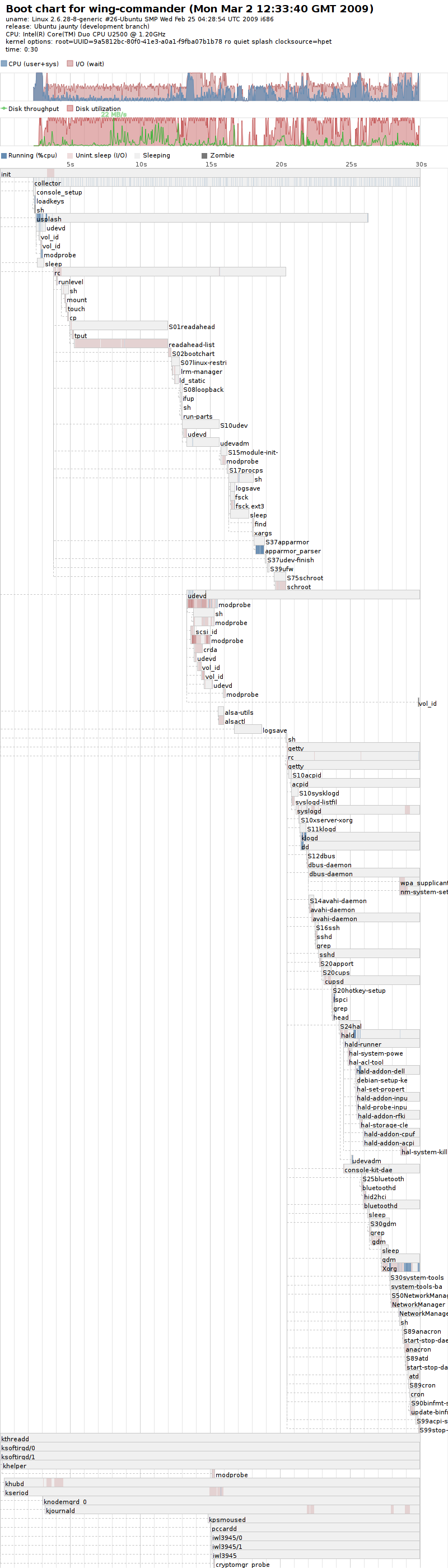{kind=link}
| Scott James Remnant (Canonical) (canonical-scott) wrote : | #7 |
{kind=link}
| Scott James Remnant (Canonical) (canonical-scott) wrote : | #8 |
No different when changing clocksource between hpet and acpi_pm
Either X or compiz FAIL when using jiffies or tsc, or I'm impatient ;)
| Scott James Remnant (Canonical) (canonical-scott) wrote : | #9 |
{kind=link}
| Scott James Remnant (Canonical) (canonical-scott) wrote : | #10 |
{kind=link}
| Scott James Remnant (Canonical) (canonical-scott) wrote : | #11 |
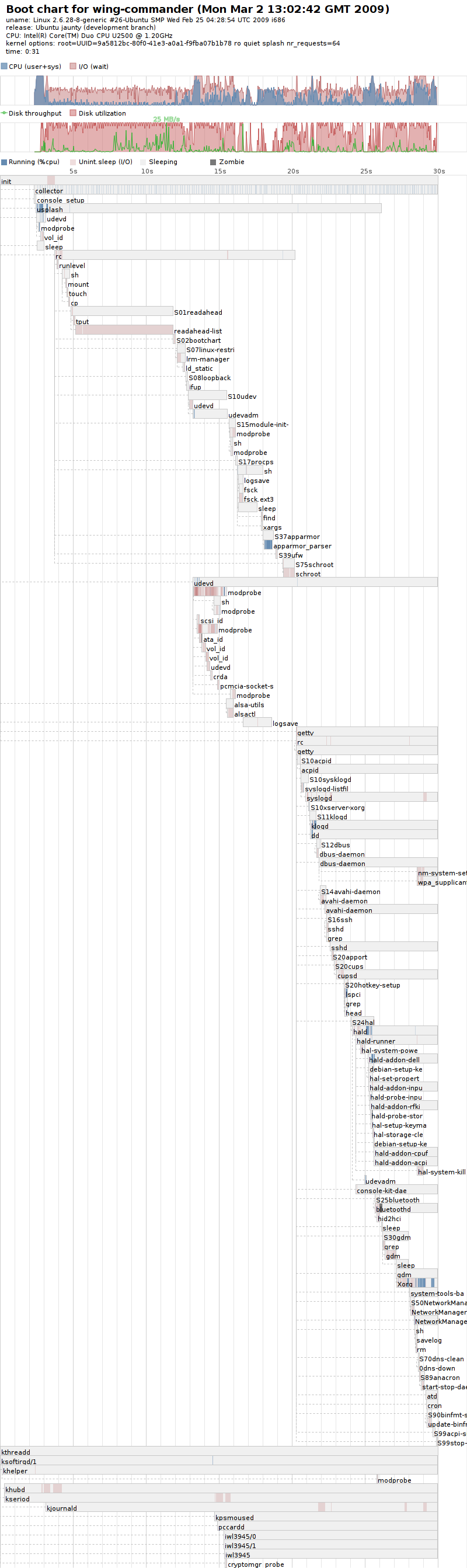{kind=link}
| Scott James Remnant (Canonical) (canonical-scott) wrote : | #12 |
{kind=link}
| Scott James Remnant (Canonical) (canonical-scott) wrote : | #13 |
I added an initramfs script to let me vary the nr_requests value from the kernel command-line, but it doesn't seem to make a difference
| Scott James Remnant (Canonical) (canonical-scott) wrote : | #14 |
This is all occuring on:
Linux wing-commander 2.6.28-8-generic #26-Ubuntu SMP Wed Feb 25 04:28:54 UTC 2009 i686 GNU/Linux
(as you can see from the bootcharts :p)
| Changed in linux: | |
| status: | New → Triaged |
| Andy Whitcroft (apw) wrote : | #15 |
this is a serious issue but only affects limited hardware therefore marking Medium importance
| Changed in linux: | |
| importance: | Undecided → Medium |
| Changed in linux: | |
| status: | Confirmed → Invalid |
| Jeremy Foshee (jeremyfoshee) wrote : | #16 |
This bug report was marked as Triaged a while ago but has not had any updated comments for quite some time. Please let us know if this issue remains in the current Ubuntu release, http://
[This is an automated message. Apologies if it has reached you inappropriately; please just reply to this message indicating so.]
| tags: | added: kj-triage |
| Changed in linux (Ubuntu): | |
| status: | Triaged → Incomplete |
| aurelien (saurelien) wrote : | #17 |
It seems to me that I have the same issue: high I/O but low cpu utilization as well as high disk utilization but low throughput. My bootup times are very slow (up to 5min for the desktop to fully load).
I had the issue under 9.10 and it is still there after upgrading to 10.04. (both amd64)
I have a laptop samsung q320 with P8600 and 4GB ram
| John Doe (b2109455) wrote : | #18 |
Posted a comment concerning my D430 here:
https:/
| penalvch (penalvch) wrote : | #19 |
Scott James Remnant, this bug was reported a while ago and there hasn't been any activity in it recently. We were wondering if this is still an issue? If so, could you please test for this with the latest development release of Ubuntu? ISO images are available from http://
If it remains an issue, could you please run the following command in the development release from a Terminal (Applications-
apport-collect -p linux <replace-
Also, could you please test the latest upstream kernel available (not the daily folder) following https:/
kernel-
kernel-
where VERSION-NUMBER is the version number of the kernel you tested. For example:
kernel-
This can be done by clicking on the yellow circle with a black pencil icon next to the word Tags located at the bottom of the bug description. As well, please remove the tag:
needs-upstream-
If the mainline kernel does not fix this bug, please add the following tags:
kernel-
kernel-
As well, please remove the tag:
needs-upstream-
Once testing of the upstream kernel is complete, please mark this bug's Status as Confirmed. Please let us know your results. Thank you for your understanding.
| tags: | added: needs-kernel-logs needs-upstream-testing |
|
636 comments hidden
Loading more comments
|
view all 695 comments |
|
|
#656 |
I'm still seeing this.
Setup: Debian 7 Wheezy, amd64 backports kernel (3.11-0.
Observation: The machine (32-core Xeon E5-4650, 192 GB RAM), primarily servicing multiple interactive users via SSH, x2go and SunRay sessions, gets completely unusable during and quite some time after the rsync transfer. TCP connections to SunRay clients time out, IRC connections are dropped, even simple tools like "htop" don't do anything but clear the screen after being started. "iotop" shows a [jbd2/dm-1-8] process on top, reportedly doing "99.99%" I/O (but not reading or writing a single byte, maybe because it's a kernel thread?).
Once I switch from the default CFQ I/O scheduler to "deadline" (echo deadline > /sys/block/
|
|
#657 |
Still face this bug. Kernel 3.16
Is it possible to preserve 5% of IO for user/othe processes needs? Any fast download or copying eats 99.99 of IO and system is hard to use.
|
|
#658 |
I'm curious: this bug was ostensibly fixed years ago however I dare everyone, who owns an Android smartphone, run a simple test. Invoke any terminal emulator and execute this command:
$ cat < /dev/zero > /sdcard/EMPTY
What's terribly unpleasant is that _all_ CPU cores become busy (more than 75% load), and the CPU jumps into the highest performance state, i.e. frequency, i.e. power consumption. Obviously this is wrong, bad and shouldn't happen. This test is kinda artificial as no Android app can create such a high IO load, but then there are multiple phones out there with either 5GHz MIMO 802.11n or 802.11ac chips which allow up to 80MB/sec throughput which can easily saturate most if not all internal MMC cards and have the same effect as the above command.
Perhaps vanilla kernel bugzilla is not a place to discuss bugs in Android, but latest Android releases usually feature kernels 3.10.x and 4.1.x without that many patches, so this bug is still there. Both these kernels are currently maintained and supported. Android by default never uses SWAP (one of the reasons for this bug).
Go figure.
P.S. Sample apps from Google Play:
* CPU Stats by takke
* Terminal Emulator by Jack Palevich
|
|
#659 |
I've just experienced this issue with 3.19.0-32-generic on Ubuntu.
My KTorrent downloaded files to NTFS filesystem on SATA3 drive (fuse, download speed was about 100Mbit/s), simultaneously I copied files from that filesystem to USB3.0 flash drive with NTFS filesystem. That resulted poor interactive performance, mouse and windows lags. The workaround was to suspend torrent downloa until files copied.
Hardware: One AMD FX(tm)-8320 Eight-Core Processor, 8 GB RAM.
|
|
#660 |
This bug is definitely not fixed. A simple cp from one drive to another makes a huge impact on my desktop. Trying to do an rsync is even worse. It seems to mainly be a problem with large files. My system is old (Athlon II 250) but even an old P3 running Win98 doesn't lag this bad from just copying files.
|
|
#661 |
I'm trying to copy 50gb from one tower to another via USB 3.0 and it is really no fun. If I would copy all files at once the speed is decreasing constantly. After 30 minutes it copies with 1.0MB/s. If I copy a bunch of directories it is a littlebit better but also decreases in speed. For 2GB my Linux system needs more than an hour. This bug is definitely not fixed. On Windows this USB Stick is working without that speed loss.
OS: Fedora 24
Kernel: 4.8.15
|
|
#662 |
I've noticed that this happens not everytime when I use exact the same USB stick. For my 2GB files (Eclipse with workspace and a project) I needed one hour to copy. It startet with 60MB/s and decreased to 500KB/s. Now I copy 16gb (android studio and some other projects) and it only needs about 15minutes. The copy speed startet with 70MB/s and at the end it was 22MB/s fast. So it also decreases but not as fast as in my 2GB copy process.
|
|
#663 |
It seems Kernel developers not look this topic here, much better to write to the mailing list.
|
|
#664 |
Does Jens' buffered writeback throttling patchset solve your issue?
|
|
#665 |
(In reply to bes1002t from comment #642)
> I'm trying to copy 50gb from one tower to another via USB 3.0 and it is
> really no fun. If I would copy all files at once the speed is decreasing
> constantly. After 30 minutes it copies with 1.0MB/s. If I copy a bunch of
> directories it is a littlebit better but also decreases in speed. For 2GB my
> Linux system needs more than an hour. This bug is definitely not fixed. On
> Windows this USB Stick is working without that speed loss.
>
> OS: Fedora 24
> Kernel: 4.8.15
This bug report has nothing to do with the speed of copying data to USB flash drive. It's about substantially degraded interactivity which manifests in slowness and it's hard to believe you can perceive it via an SSH session.
I'm inclined to believe your bug is related to other subsystems like USB.
> It seems Kernel developers not look this topic here, much better to write to
> the mailing list.
Kernel bugzilla has always been neglected. Thousands of bug reports which have zero comments from prospective developers. LKML is a hit and miss too. Your developer skipped your e-mail because he/she was busy? Bad luck.
|
|
#666 |
@bes1002t: I think throughput is a different issue than this, although it might well be related.
But most important would be for someone to create a I/O concurrency / latency benchmark. Maybe the Phoronix Test Suite is an adequate tool for that? It can also be used for automatic bisecting..
I clearly remember pre-2.6.18 times where I had a much inferior machine and while gent0o's emerge was compiling stuff in the background with multiple threads, I could browse the web switch between programs and play a HD stream without any hickup or stalling.
|
|
#667 |
@bes1002t: Copying to a USB device always starts with the speed of the harddrive as all is cached till the write cache is full and ends with the speed of the usb drive. The write process has to wait till all data is written.
@Artem S. Tashkinov: The stall problems on a ssh session exists or existed. I have migrated an old server with CentOS 6 and copied some vm images. The ssh responsiveness was very bad. I had to wait for up to 20 seconds for tab auto to complete.
I many cases it was a swap problem, as the buffers are full and the caches need a long time to be written to a slow usb device. The server starts to swap process data. It's only a very small amount of data. I could increase the overall desktop performance with an RAM upgrade.
|
|
#668 |
Try Kernel 4.10.
>Improved writeback management
>
>Since the dawn of time, the way Linux synchronizes to disk the data written to
>memory by processes (aka. background writeback) has sucked. When Linux writes
>all that data in the background, it should have little impact on foreground
>activity. That's the definition of background activity...But for a long as it
>can be remembered, heavy buffered writers have not behaved like that. For
>instance, if you do something like $ dd if=/dev/zero of=foo bs=1M count=10k,
>or try to copy files to USB storage, and then try and start a browser or any
>other large app, it basically won't start before the buffered writeback is
>done, and your desktop, or command shell, feels unreponsive. These problems
>happen because heavy writes -the kind of write activity caused by the
>background writeback- fill up the block layer, and other IO requests have to
>wait a lot to be attended (for more details, see the LWN article).
>
>This release adds a mechanism that throttles back buffered writeback, which
>makes more difficult for heavy writers to monopolize the IO requests queue,
>and thus provides a smoother experience in Linux desktops and shells than what
>people was used to. The algorithm for when to throttle can monitor the
>latencies of requests, and shrinks or grows the request queue depth
>accordingly, which means that it's auto-tunable, and generally, a user would
>not have to touch the settings. This feature needs to be enabled explicitly in
>the configuration (and, as it should be expected, there can be regressions)
|
|
#669 |
Hi..
Thank you for your email.
I am sorry, but this email will soon be disabled..
Please send everything work related to <email address hidden>
Please send private mails to <email address hidden>
bye m.
|
|
#670 |
> Try Kernel 4.10.
It not helps in my work load :(
still freezing mouse pointer and keyboard input
|
|
#671 |
Make sure your kernel has that option enabled.
>This feature needs to be enabled explicitly in
>the configuration (and, as it should be expected, there can be regressions)
|
|
#672 |
I read this https:/
|
|
#673 |
Created attachment 255491
$ cat /boot/config-`uname -r`
|
|
#674 |
(In reply to Mikhail from comment #651)
First, I'd recommend trying to disable SWAP completely - it might help:
$ sudo swapoff -a
If you compile your own kernel or your distro hasn't enabled them for you, here's the list of the options you need to enable:
BLK_WBT, enable support for block device writeback throttling
BLK_WBT_MQ, multiqueue writeback throttling
BLK_WBT_SQ, single queue writeback throttling
They are all under "Enable the block layer".
If disabling swap and enabling these options have no effect, please ***create a new bug report*** and provide the following information:
CPU
Motherboard and BIOS version
RAM type and volume
Storage and its type
Kernel version and its .config
And also the complete output of these utilities:
dmesg
lspci -vvv
lshw
free
vmstat (when the bug is exposed)
cat /proc/interrupts
cat /proc/iomem
cat /proc/meminfo
cat /proc/mttr
|
|
#675 |
>CONFIG_BLK_WBT=y
># CONFIG_BLK_WBT_SQ is not set
>CONFIG_
So writeback throttling is enabled only for multi queue devices in your case. I suppose you need to use blk-mq for your sd* devices to activate writeback throttling (scsi_mod.
|
|
#676 |
Created attachment 255501
all required files in one archive
|
|
#677 |
After setting boot flag "scsi_mod.
I'm also catch vmstat output when freeze occurred:
# vmstat
procs -------
r b swpd free buff cache si so bi bo in cs us sy id wa st
2 6 15947052 205136 112592 4087608 32 41 93 119 7 23 43 19 37 1 0
|
|
#678 |
Twice I asked you you to try disabling SWAP altogether and you still haven't.
I'm unsubscribing from this bug report.
|
|
#679 |
Created attachment 274511
Per deice dirty ration configuration support
Per device dirty bytes configuration
|
|
#680 |
Per device dirty bytes configuration. Patch is not ideal, i'm make it for smoothly flash drive wriring by passing smaller value of dirty byte per removeable device.
>> Path
# ls /sys/block/sdc/bdi/
dirty_backgroun
>> udev Rule for removeables device
# cat /etc/udev/
ACTION=
|
|
#681 |
Hello Ben,
I was trying to figure out the issue but not really sure what exactly the error here. Is the bug fixed already? Or do we have some sources that maybe help us? Thank you
Carlo B.
https:/
| Changed in linux: | |
| importance: | Unknown → High |
| status: | Invalid → Fix Released |
|
|
#682 |
Was this bug actually fixed? The status shows CLOSED CODE_FIX with a last modified date of Dec 5 2018. I don't see any updates as to what was corrected, and what version the fix will be put into?
|
|
#683 |
Created attachment 282477
attachment-
This was never fixed and since bug state cheating with no commit info ever
provided even if asked directly, will never be fixed. Nobody just cares and
I guess nobody even figured out who broke the kernel by which changeset and
when. Just buy another couple of Xeons for your zupa-dupa web-serfing
desktop and pray it's enough for loads of waits when you format your
diskette. Another approach is to buy enough ram to hold whole your block
devices set there so write-outs are quick enough and you won't see
microsecond lags. This is complete workaround list they provided since the
bug opened.
вт, 23 апр. 2019 г., 18:21 <email address hidden>:
> https:/
>
> protivakid (<email address hidden>) changed:
>
> What |Removed |Added
>
> -------
> CC| |<email address hidden>
>
> --- Comment #663 from protivakid (<email address hidden>) ---
> Was this bug actually fixed? The status shows CLOSED CODE_FIX with a last
> modified date of Dec 5 2018. I don't see any updates as to what was
> corrected,
> and what version the fix will be put into?
>
> --
> You are receiving this mail because:
> You are on the CC list for the bug.
|
|
#684 |
As far as I understand, this is kind of meta-bug: there are multiple causes and multiple fixes.
"I do bulk IO and it gets slow" sounds rather general, and problem that can resurface anytime due to some new underlying issue. So the problem cannot be really "closed for good" no matter how much technical progress is made.
For me 12309 basically stopped happening unless I deliberately tune "/proc/
I don't expect meaningful technical discussion to be happen in this thread. It should just serve as a hub for linking to specific new issues.
|
|
#685 |
Sure it's a meta bug, but for me 12309 is still actual, and I don't use any tuning for I/O subsystem at all.
Not as bad as years ago when it happens for the first time, but I still have to throttle rtorrent to download at 2.5MB/sec maximum instead of usual 10MB/s if I like to view films in mplayer at same time without jitter/freeze/lag. And that's on powerful and modern enough system with kernel 4.19.27, CPU i7-2600K @ 4.5GHz, RAM 24GB, and HDD 3TB Western Digital Caviar Green WD30EZRX-00D. This is annoying, and I remember time before 12309 when rtorrent without any throttling won't make mplayer to freeze on less powerful hardware.
|
|
#686 |
Created attachment 282483
attachment-
Well, I've tried to report a new bug to investigate my own "my CPU does
nothing because waiting is too hard for it". Of no interest of any kernel
dev. So, just as Linus once said "f**k you Nvidia", the very same goes back
to linux itself. Pity some devs think that make their software linux-bound
(via udev only binding or alsa only sound out) is a good idea (gnome and
even parts of KDE). They forgot 15 years ago they picketed Adobe for having
flash for win only. Now one has to use 12309-bound crap for not having a
way to run his software on another platform.
вт, 23 апр. 2019 г., 21:29 <email address hidden>:
> https:/
>
> --- Comment #665 from _Vi (<email address hidden>) ---
> As far as I understand, this is kind of meta-bug: there are multiple
> causes and
> multiple fixes.
>
> "I do bulk IO and it gets slow" sounds rather general, and problem that can
> resurface anytime due to some new underlying issue. So the problem cannot
> be
> really "closed for good" no matter how much technical progress is made.
>
> For me 12309 basically stopped happening unless I deliberately tune
> "/proc/
> them
> back. I see system controllably slowing down processes doing bulk IO so the
> system in general stays reasonable. This behaviour is one of outcomes of
> this
> bug.
>
> I don't expect meaningful technical discussion to be happen in this
> thread. It
> should just serve as a hub for linking to specific new issues.
>
> --
> You are receiving this mail because:
> You are on the CC list for the bug.
|
|
#687 |
Can 'someone' please open a bounty on creation of a VM test case, f.e. with `vagrant` or `phoronix test suite`?
Basically, a way to reproduce and quantify the perceived/actual performance difference between
> Linux 2.6.17 Released 17 June, 2006
and
> Linux 5.0 Released Sun, 3 Mar 2019
…
(In reply to Alex Efros from comment #666)
> Not as bad as years ago […]
> And that's on powerful and modern enough system with
> kernel 4.19.27, CPU i7-2600K @ 4.5GHz, RAM 24GB, and HDD 3TB […]
> This is annoying, and I remember time before
> 12309 when rtorrent without any throttling won't make mplayer to freeze on
> less powerful hardware.
Oh yeah, this... i can clearly remember back then when on a then mid-range machine with a lot of compiling (gentoo => 100% cpu �[U+1F923]�) and filesystem work, VLC used to play an HD video stream even under heavy load without any hiccups and micro-stuttering.. It was impressive at the time.. and then.. it broke �[U+1F928]�
|
|
#688 |
https:/
https:/
https:/
https:/
https:/
https:/
https:/
http://
https:/
https:/
https:/
https:/
https:/
https:/
https:/
https:/
https:/
http://
https:/
https:/
https:/
https:/
https:/
https:/
|
|
#689 |
amzing website, love it. great work done. Thanx for sharing with us, keep postings
https:/
https:/
http://
http://
http://
http://
https:/
|
|
#690 |
According to my attempts to fix this bug, I totally disagree with you.
This bug is caused by pure design of current block dev layer. Methods which are good to develop code is absolutely improper for developing ideas. It's probably the key problem of the Linux Comunity. Currently, there is merged WA for block devices with a good queue such as Samsung Pro NVMe.
WBR,
Vitaly
(In reply to _Vi from comment #665)
> As far as I understand, this is kind of meta-bug: there are multiple causes
> and multiple fixes.
>
> "I do bulk IO and it gets slow" sounds rather general, and problem that can
> resurface anytime due to some new underlying issue. So the problem cannot be
> really "closed for good" no matter how much technical progress is made.
>
> For me 12309 basically stopped happening unless I deliberately tune
> "/proc/
> them back. I see system controllably slowing down processes doing bulk IO so
> the system in general stays reasonable. This behaviour is one of outcomes of
> this bug.
>
> I don't expect meaningful technical discussion to be happen in this thread.
> It should just serve as a hub for linking to specific new issues.
|
|
#691 |
Had this again 20 minutes ago.
Was dopying 8.7GiB of data from one directory to another directory on the same filesystem (ext4 (rw,relatime,
The KDE UI became unresponsive (Everything other than /home and user data in on a SSD), could not launch any new applications. Opening a new tab on Firefox to go to Youtube didnt load the page, and kept saying waiting for youtube.com in the status bar (network gets halted?).
dmesg shows these, are they important?
[25013.905943] INFO: task DOMCacheThread:
[25013.905945] Tainted: P OE 4.15.0-54-generic #58-Ubuntu
[25013.905947] "echo 0 > /proc/sys/
[25013.905949] DOMCacheThread D 0 17496 2243 0x00000000
[25013.905951] Call Trace:
[25013.905954] __schedule+
[25013.905957] schedule+0x2c/0x80
[25013.905959] jbd2_log_
[25013.905962] ? wait_woken+
[25013.905965] __jbd2_
[25013.905967] jbd2_journal_
[25013.905970] ext4_force_
[25013.905972] ext4_sync_
[25013.905975] vfs_fsync_
[25013.905977] do_fsync+0x3d/0x70
[25013.905980] SyS_fsync+0x10/0x20
[25013.905982] do_syscall_
[25013.905985] entry_SYSCALL_
[25013.905987] RIP: 0033:0x7fc9cb839b07
[25013.905988] RSP: 002b:00007fc9a7
[25013.905990] RAX: ffffffffffffffda RBX: 00000000000000a0 RCX: 00007fc9cb839b07
[25013.905992] RDX: 0000000000000000 RSI: 00007fc9a7aeaff0 RDI: 00000000000000a0
[25013.905993] RBP: 0000000000000000 R08: 0000000000000000 R09: 72732f656d6f682f
[25013.905994] R10: 0000000000000000 R11: 0000000000000293 R12: 00000000000001f6
[25013.905995] R13: 00007fc97fc5d038 R14: 00007fc9a7aeb340 R15: 00007fc987523380
|
|
#692 |
KDE have problem too, same copy via CLI or via Ultracopier (GUI) have no problem.
I note too KDE have UI more slow, plasma doing CPU usage in case I use the HDD...
|
|
#693 |
What's the value of `vm.dirty_
$ sysctl vm.dirty_
try setting it to 0 to disable it, ie.
`$ sudo sysctl -w vm.dirty_
I found that this helps my network transfer not stall/stop at all(for a few seconds when that is =1000 for example) while some kinda of non-async `sync`(
vm.dirty_
Coupled with the above I've been using another value:
`vm.dirty_
for both cases (when stall and not stall), so this one remained fixed to =1000.
vm.dirty_
Well, with the above, at least I'm not experiencing network stalls when copying GiB of data via Midnight Commander's sftp to my SSD until some kernel-caused sync-ing is completed in the background.
I don't know if this will work for others, but if curious about any of my other (sysctl)settings, they should be available for perusing [here](https:/
|
|
#694 |
correction:
> In this case it's 1 seconds.
*In this case it's 10 seconds.
Also, heads up:
I found that 'tlp' in `/etc/default/tlp`, on ArchLinux, will overwrite the values set in `/etc/sysctl.
MAX_LOST_
MAX_LOST_
will set:
vm.dirty_
vm.dirty_
regardless of what values you set them in `/etc/sysctl.
/etc/default/tlp is owned by tlp 1.2.2-1
Not setting those (eg. commenting them out) will have tlp set the to its default of 15 sec (aka =1500). So the workaround is to set them to =0 which makes tlp not set them at all, thus the values from `/etc/sysctl.
| penalvch (penalvch) wrote : | #695 |
Last response from OR 2009. Upstream code fix 2012. -> Invalid
| no longer affects: | linux (Ubuntu) |
| affects: | linux → linux (Ubuntu) |
| Changed in linux (Ubuntu): | |
| importance: | High → Undecided |
| status: | Fix Released → New |
| status: | New → Invalid |
This is an attempt at bringing sanity to bug #7372. Please only comment here is you are experiencing high I/O wait times and interactvity on reasonable workloads.
Latest working kernel version: 2.6.18?
Problem Description:
I/O operations on large files tend to produce extremely high iowait times and poor system I/O performance (degraded interactivity). This behavior can be seen to varying degrees in tasks such as,
- Backing up /home (40GB with numerous large files) with diffbackup to external USB hard drive
- Moving messages between large maildirs
- updatedb
- Upgrading large numbers of packages with rpm
Steps to reproduce:
The best synthetic reproduction case I have found is,
$ dd if=/dev/zero of=/tmp/test bs=1M count=1M
During this copy, IO wait times are very high (70-80%) with extremely degraded interactivity although throughput averages about 29MB/s (about the disk's capacity I think). Even starting a new shell takes minutes, especially after letting the machine copy for a while without being actively used. Could this mean it's a caching issue?