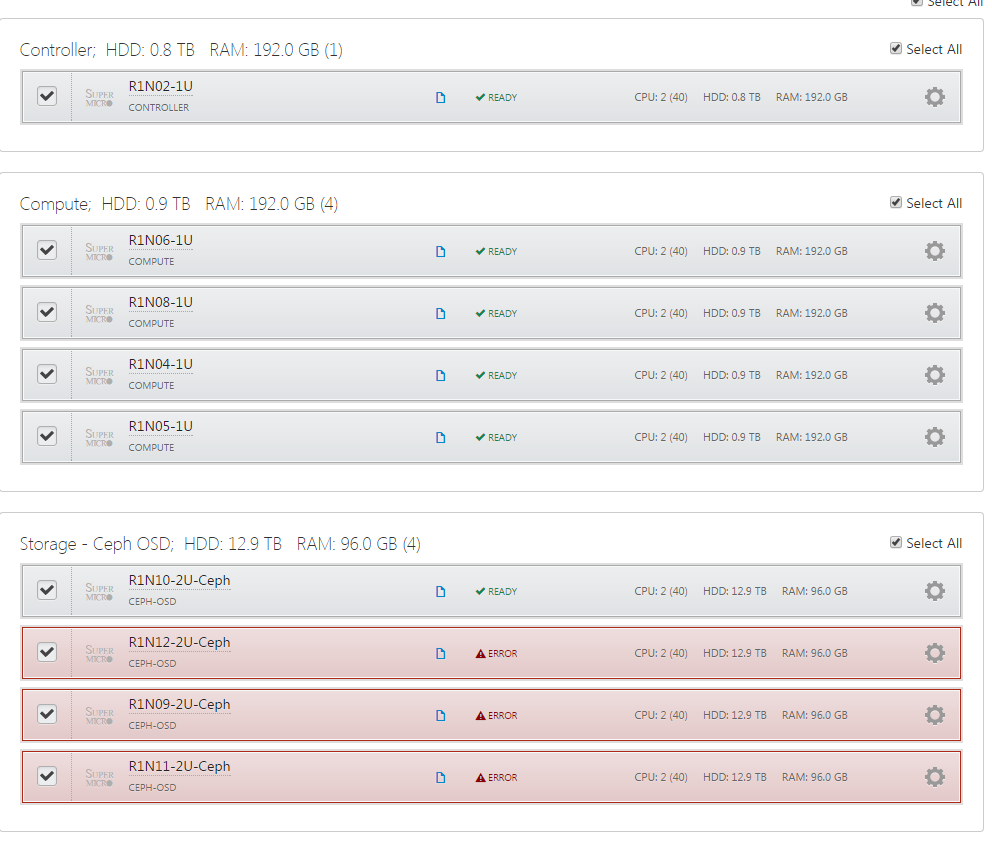
3 out of 4 Ceph OSD nodes failing to deploy
| Affects | Status | Importance | Assigned to | Milestone | |
|---|---|---|---|---|---|
| Fuel for OpenStack |
Won't Fix
|
Medium
|
Fuel Python (Deprecated) | ||
| 8.0.x |
Won't Fix
|
Medium
|
Fuel Python (Deprecated) | ||
Bug Description
1. Used Fuel 6.0 to create a OpenStack Cluster with 1 controller & 4 compute nodes
2. Successfully deployed
---------------
3. Added 4 nodes as Ceph OSD's, configured networking & hard drives
4. Click Deploy
Result:
Error:
2015-07-11 02:00:19 ERR (/Stage[
2015-07-11 02:00:19 ERR /usr/bin/puppet:4
2015-07-11 02:00:19 ERR /usr/lib/
2015-07-11 02:00:19 ERR /usr/lib/
2015-07-11 02:00:19 ERR /usr/lib/
2015-07-11 02:00:19 ERR /usr/lib/
2015-07-11 02:00:19 ERR /usr/lib/
2015-07-11 02:00:19 ERR /usr/lib/
2015-07-11 02:00:19 ERR /usr/lib/
2015-07-11 02:00:19 ERR /usr/lib/
2015-07-11 02:00:19 ERR /usr/lib/
2015-07-11 02:00:19 ERR /usr/lib/
2015-07-11 02:00:19 ERR /usr/lib/
2015-07-11 02:00:19 ERR /usr/lib/
2015-07-11 02:00:19 ERR /usr/lib/
2015-07-11 02:00:19 ERR /usr/lib/
2015-07-11 02:00:19 ERR /usr/lib/
2015-07-11 02:00:19 ERR /usr/lib/
2015-07-11 02:00:19 ERR /usr/lib/
2015-07-11 02:00:19 ERR /usr/lib/
2015-07-11 02:00:19 ERR /usr/lib/
2015-07-11 02:00:19 ERR /usr/lib/
2015-07-11 02:00:19 ERR /usr/lib/
2015-07-11 02:00:19 ERR /usr/lib/
2015-07-11 02:00:19 ERR /usr/lib/
2015-07-11 02:00:19 ERR /usr/lib/
2015-07-11 02:00:19 ERR /usr/lib/
2015-07-11 02:00:19 ERR /usr/lib/
2015-07-11 02:00:19 ERR /usr/lib/
2015-07-11 02:00:19 ERR /usr/lib/
2015-07-11 02:00:19 ERR /usr/lib/
2015-07-11 02:00:19 ERR /usr/lib/
2015-07-11 02:00:19 ERR /usr/lib/
2015-07-11 02:00:19 ERR /usr/lib/
2015-07-11 02:00:19 ERR /usr/lib/
2015-07-11 02:00:19 ERR /usr/lib/
2015-07-11 02:00:19 ERR /usr/lib/
2015-07-11 02:00:19 ERR /usr/lib/
2015-07-11 02:00:19 ERR /usr/lib/
2015-07-11 02:00:19 ERR /usr/lib/
2015-07-11 02:00:19 ERR ceph-deploy --overwrite-conf config pull node-2 returned 1 instead of one of [0]

{kind=link}
{kind=link}
| Changed in fuel: | |
| status: | New → Confirmed |
| Changed in fuel: | |
| status: | Confirmed → Incomplete |
| Changed in fuel: | |
| status: | New → Confirmed |
| Changed in fuel: | |
| milestone: | 7.0 → 8.0 |
| status: | Won't Fix → Triaged |
| no longer affects: | fuel/8.0.x |
| tags: | added: area-python |
Everytime I try to submit a the logs (995MB), launchpad takes 8 minutes to upload, then after reaching 100%, it gives me this:
Timeout error
Sorry, something just went wrong in Launchpad.
We’ve recorded what happened, and we’ll fix it as soon as possible. Apologies for the inconvenience.
Trying again in a couple of minutes might work.
(Error ID: OOPS-c0dd22466f83815695539d8057071ee5)