
Frequent kernel panics when doing heavy I/O in LXC containers on Btrfs
| Affects | Status | Importance | Assigned to | Milestone | |
|---|---|---|---|---|---|
| linux (Ubuntu) |
Confirmed
|
High
|
Unassigned | ||
Bug Description
I initially reported this as a bug in LXC (https:/
I'm running Ubuntu 14.04.1 LTS (x86_64) on my Laptop. Current Kernel version is "3.13.0-
I have a dedicated Btrfs file system mounted on /container/, which I use for storing all LXC containers.
The file system is created on top of a logical volume:
lenz@lenz-
/dev/mapper/
lenz@lenz-
--- Logical volume ---
LV Path /dev/ubuntu-
LV Name container
VG Name ubuntu-vg
LV UUID JUq21P-
LV Write Access read/write
LV Creation host, time lenz-ThinkPad-T440, 2014-09-15 13:42:27 +0200
LV Status available
# open 1
LV Size 65,00 GiB
Current LE 16640
Segments 1
Allocation inherit
Read ahead sectors auto
- currently set to 256
Block device 252:5
The hard disk drive is a Samsung SSD ("Samsung SSD 840 EVO 500GB, EXT0BB0Q, max UDMA/133", according to dmesg).
I have a number containers based on CentOS 6, these were created by cloning a base image using lxc-clone -s.
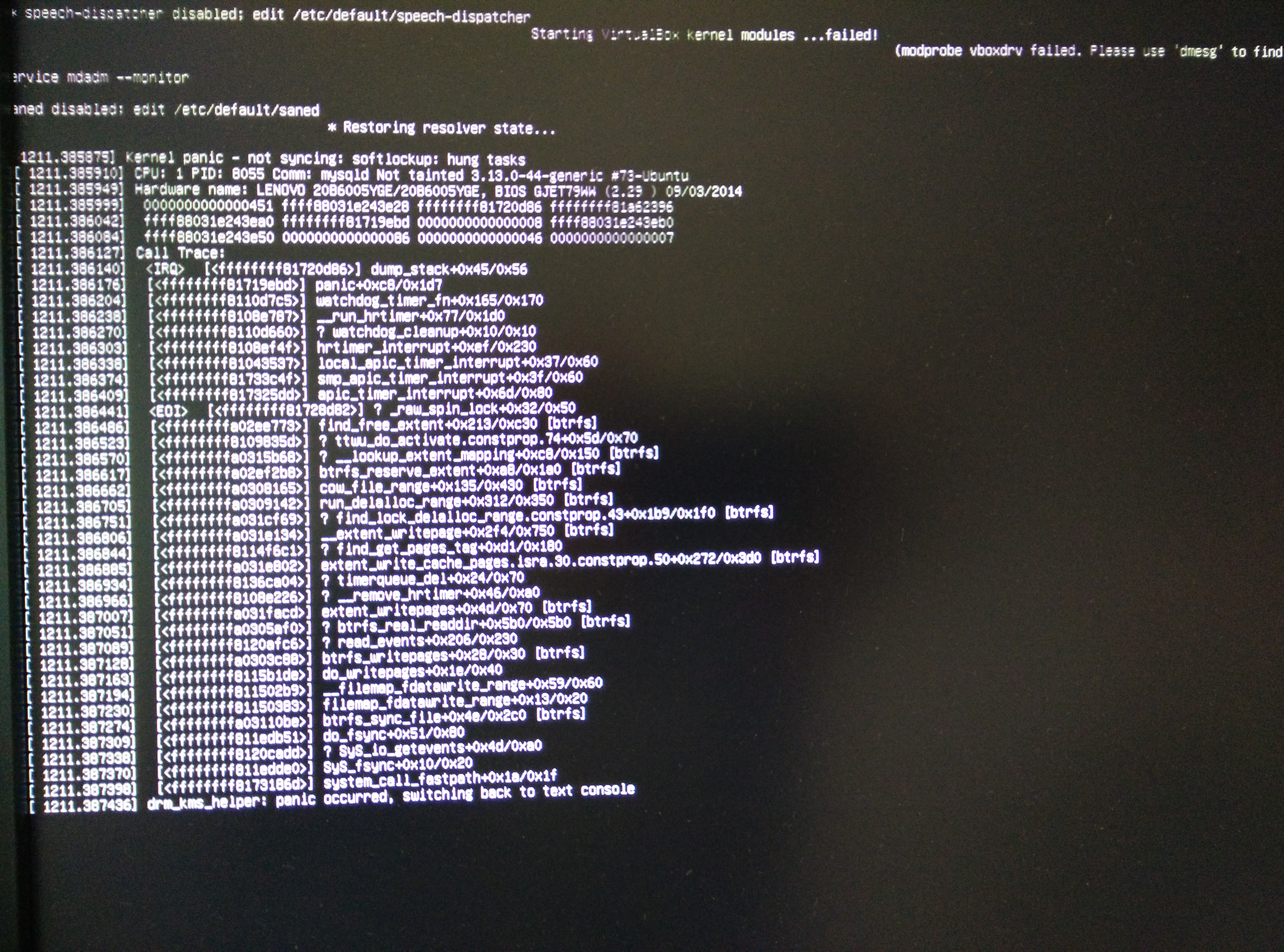
Quite frequently, when I create heavy disk I/O in one or several of these containers (e.g. by running yum update concurrently, or by transferring large files e.g. via a HTTP upload to one of the container instances), my host system freezes. This only happens when container activity is involved, the system runs stable otherwise. Most of the time the X desktop freezes, sometimes a Kernel panic can be observed on the console. Unfortunately I'm unable to capture it other than by taking a picture. The only solution is to perform a cold reboot using the power button.
This occurred to me before. I then re-created the /container/ file system from scratch and started again. But now it's happening again, so I would like to report it for investigation.
ProblemType: Bug
DistroRelease: Ubuntu 14.04
Package: linux-image-generic 3.13.0.44.51
ProcVersionSign
Uname: Linux 3.13.0-44-generic x86_64
ApportVersion: 2.14.1-0ubuntu3.6
Architecture: amd64
AudioDevicesInUse:
USER PID ACCESS COMMAND
/dev/snd/
/dev/snd/
CurrentDesktop: Unity
Date: Wed Jan 28 16:16:20 2015
HibernationDevice: RESUME=
InstallationDate: Installed on 2014-09-15 (135 days ago)
InstallationMedia: Ubuntu 14.04.1 LTS "Trusty Tahr" - Release amd64 (20140722.2)
MachineType: LENOVO 20B6005YGE
ProcFB: 0 inteldrmfb
ProcKernelCmdLine: BOOT_IMAGE=
RelatedPackageV
linux-
linux-
linux-firmware 1.127.11
SourcePackage: linux
UpgradeStatus: No upgrade log present (probably fresh install)
dmi.bios.date: 09/03/2014
dmi.bios.vendor: LENOVO
dmi.bios.version: GJET79WW (2.29 )
dmi.board.
dmi.board.name: 20B6005YGE
dmi.board.vendor: LENOVO
dmi.board.version: 0B98401 PRO
dmi.chassis.
dmi.chassis.type: 10
dmi.chassis.vendor: LENOVO
dmi.chassis.
dmi.modalias: dmi:bvnLENOVO:
dmi.product.name: 20B6005YGE
dmi.product.
dmi.sys.vendor: LENOVO

{kind=link}
{kind=link}
| tags: |
added: kernel-da-key removed: kernel-key |
Attaching a second screen shot with a slightly different stack trace